序言:
Flink系列的文章会一直更新,这里只是参考官方文档,给出一个大概的解释,这里面涉及很多的细节需要划分多个模块单独来讲解,有兴趣的同学还是直接去看官网(官方文档和社区)和源码,这样获取知识最真实。Flink可能会是Spark之后的一个趋势,只说可能哦。据我所知,国内一些大厂已经开始使用Flink来进行实时业务和离线业务的处理。一位大佬说过,Flink的未来是流处理 + 批处理 + 机器学习 + 物联网。所以小伙伴们赶紧上车吧。
一 Summary(Flink简介):
Apache Flink是一个用于分布式流和批处理数据的开源平台。Flink的核心是一个流数据引擎,它为数据流上的分布式计算提供数据分布、通信和容错能力。Flink在流引擎之上构建批处理,覆盖本地迭代支持、托管内存和程序优化。
二 Concepts:
Dataflow programing Model: 数据流应用模型
Levels of Flink:
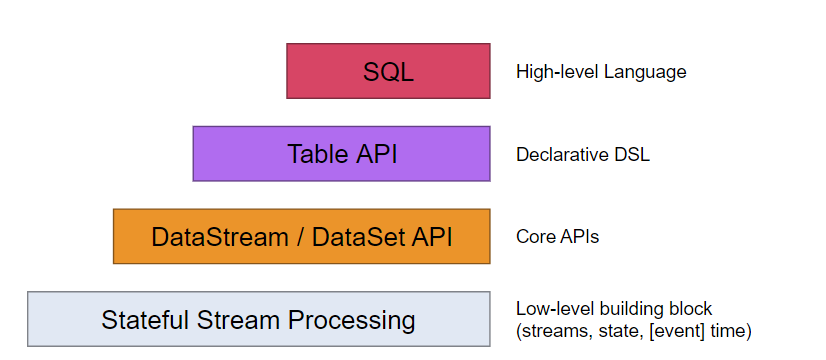
1》Stateful Stream Processing:
低级别的构建模块,主要包含streams、state、[event time]
在flink中属于最底层的API,状态流的抽象。通过Process funtion嵌入到DataStream API中去。
开发者可以自由的使用一致性的状态来处理一个或者多个流事件。除此之外,开发者也可以注册事件时间并处理时间回调,允许应用去实现复杂的计算操作。
2》DataStream / DataSet API:
在实际应用中,大多数的应用不需要低级别的抽象,核心API(DataStream API / DataSet API)已经够用了。
核心API已经提供了数据处理的通用模块,比如说joins, aggregations, windows, state, etc.在Java API和scala API中数据类型使用类来表示。
低级别的Process Function与 DataStream API集成在一起,使得可以仅对某些操作进行较低级别的抽象。DataSet API在有界数据集上提供了额外的基元,如循环/迭代。
3》 Table API:
Table API是以表格为中心的声明式DSL,可以动态地更改表格(表示流时)。
表和关系数据库的表类似,有schema信息,也支持select,join,group by,aggregate等操作Table API描述的一种逻辑操作而不是具体的代码。
尽管Table API用户可以自定义各种函数,更简单的使用,不用写太多代 码。除此之外,Table API在执行之前,会进行最优化处理。开发者可以在DataStream/DataSet和tables之间无缝切换,一个程序可以混合使用 Table API和DataStream and DataSet APIs.
4》 SQL:
Flink提供的最高级别的抽象是SQL。这和Table API在语义和表达上是相似的,但是这个表现形式是SQL查询表达式SQL这种抽象和Table API的交互非常紧密,SQL查询可以通过定义在Table上的Table API执行。
Programs and Dataflows(数据流程序)
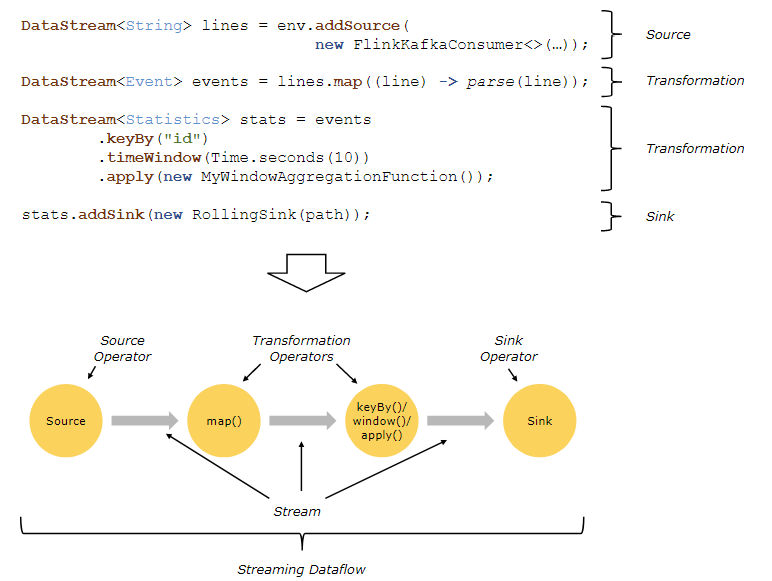
1》Flink应用的两大基础构建模块是streams(流)and transformations(转换操作).(Flink’s DataSet API也是基于流来操作的).streams(流)是什么?流是用来描述源源不断产生的数据记录。transformation指的是对数据的一种操作,对一个或者多个输入的数据流,产生一个或者多个输出流,作为这个transformation的结果。
2》Flink应用被映射成多个数据流,由一系列的streams and transformation operators组成。每个数据流由一个或者多个source组成,并流向一个或者多个sinks。数据的流向可以用有向无环图表示。尽管通过迭代构造可以允许特殊形式的循环,但为了简单起见,我们将在大多数情况下忽略它。
3》Flink应用中的(DataStream)转换与数据流中的操作符(map,flatmap等)之间通常存在一对一的对应关系。然而,有时候,一个转换可能由多个转换操作符组成。
Parallel Dataflows(并行数据流)
Flink中的应用就是并行分布式的。在执行期间,一个流有一个或者多个流分区,一个操作有一个或者多个操作子任务。一个操作的子任务独立于其它的操作,子任务在不同的线程中执行,甚至可能在不同的节点或者containers中执行。对于一个特定的任务来说,它的并行度指的是这个任务的subtask的个数。流的并行度决定了它的生产力。同一应用的不同的操作可能会有不同的并行度。
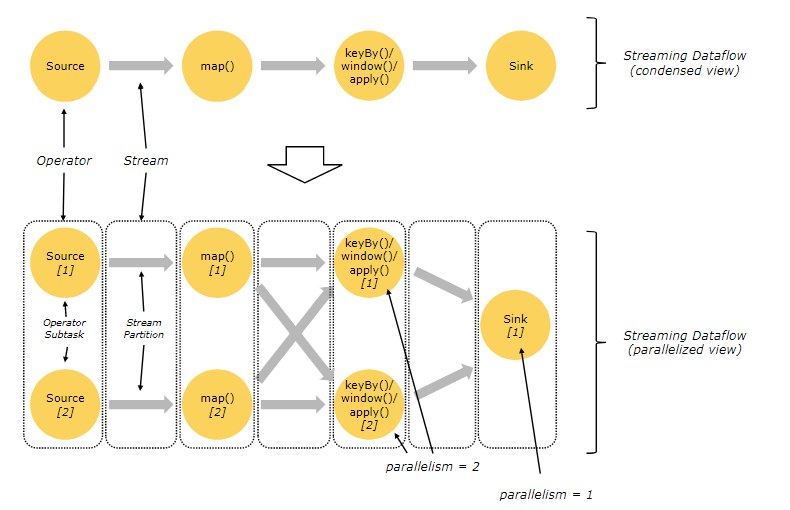
数据流转换的两种方式:
1》one-to-one (or forwarding) pattern:一对一(转发)模式
流中的数据是有序的,比如流中有数据(1,2,3,4,5)对其执行map操作,对每个数据加1就变成(2,3,4,5,6)
比如上图中source -> map的操作 fliter操作除外
2》redistributing pattern:重新分发模式
这种模式会改变流中的分区,每个operator subtask中的数据依赖选择的transformation操作将数据送到不同的目标subtasks中。
keyBy():依据对key进行hash,进行重新分发
broadcast(), or rebalance():随机进行分发
这种模式下,元素的顺序可能会改变,在每个发送subtask和接收subtask中元素的顺序不会改变。在这个例子中,每个操作内部的序列会被保存下来,但是并行机制确实引入了不确定性,比如说不同key的聚合操作,到达同一个sink。
Windows(窗口)
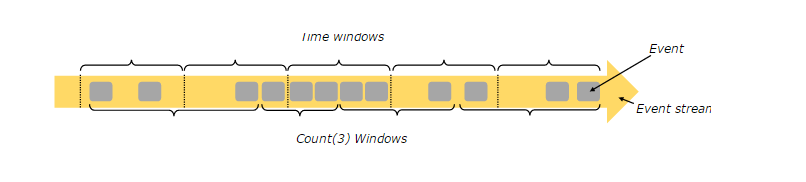
聚合事件(例如count、sums)在流上的工作方式与批处理不同。例如,不可能计算流中的所有元素,因为流通常是无限的(无界的)。相反,流上的聚合(计数、和等)是由窗口限定作用域的,例如“过去5分钟的计数”或“最后100个元素的总和”。
Windows可以是时间驱动(比如:每30秒)或数据驱动(比如:每100个元素)。一个典型的方法是区分不同类型的窗口,比如tumbling windows(翻滚窗口,没有重叠)、sliding windows (滑动窗口,有重叠)和session windows(会话窗口,中间有一个不活跃的间隙)。
Time(时间)
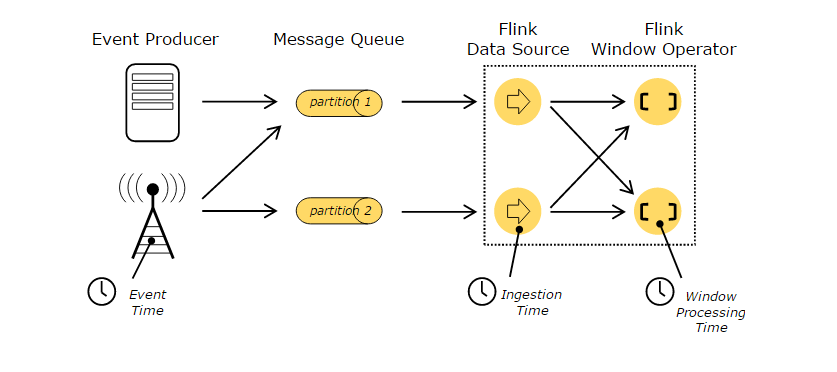
当提到流媒体应用中的时间(比如,定义窗口)时,有以下几种不同的时间概念:
- 事件时间(Event Time):是创建事件的时间。它通常由事件中的时间戳描述,例如由生产传感器或生产服务附加的时间戳。Flink通过timestamp assigners访问事件的时间戳。
- 摄入时间(Ingestion time):是事件进入Flink数据流的时间。
- 处理时间(Processing Time):每个操作符的本地时间。
Stateful Operations(有状态的操作)
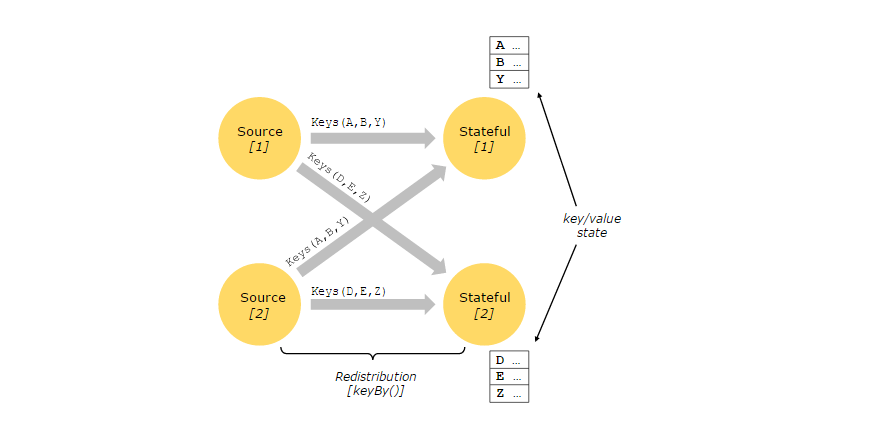
虽然数据流中的许多操作,一次只有一个单独的事件(例如事件解析器),但是一些操作记住了跨多个事件的信息(例如窗口操作符)。这些操作称为有状态操作。
有状态操作的状态被维护在可以认为是存储在嵌入的键/值中。状态与有状态操作符读取的流一起被严格地分区和分布。因此,在keyBy()函数之后,只能在键控流上访问键值状态,并且只能访问与当前事件的键相关联的值。对齐流和状态的键确保所有的状态更新都是本地操作,保证一致性而不增加事务开销。这种对齐还允许Flink透明地重新分配状态和调整流分区。
Checkpoints for Fault Tolerance(Checkpoints容错)
Flink通过流回放(stream replay)和检查点(checkpoint)的组合来实现容错。检查点与每个输入流中的特定点以及每个操作符的对应状态相关。通过恢复操作符的状态并从检查点回放事件,流数据流可以在检查点恢复,同时保持一致性(准确地说是一次处理语义)。
检查点间隔是在执行期间用恢复时间(需要重放的事件数量)来权衡容错开销的一种方法,这句话怎么那么别扭,意思就是检查点间隔越大,可能需要重放的时间数量就越多,需要的恢复时间就越大,需要的开销就越大,因此需要设置合理的间隔,检查点机制的很昂贵的。
Batch on Streaming(基于流上的批处理)
Flink执行批处理程序作为流程序的特殊情况,只不过其中流是有界的(有限的元素数量),这也是Flink和Spark在架构层面上的不同。数据集在内部被视为数据流。因此,上述概念同样适用于批处理程序,也适用于流程序,但还是有一些例外的:
- 批处理程序的容错不使用检查点。恢复通过完全重放流来实现。这是可能的,因为输入是有界的。这将使成本更多地用于恢复,但使常规处理更便宜,因为它避免了检查点。
- 数据集API中的有状态操作使用简化的内存/核心外数据结构,而不是键/值索引。
- DataSet API引入了特殊的synchronized(superstep-based,基于超步的)迭代,这只能在有界的流上实现。