一、Hive介绍:
Apache Hive能够使用SQL读取,写入和管理持久化在分布式存储(比如HDFS)中的大型数据集。 可以和已经存储好的数据(比如HDFS)建立映射关系。 用户可以使用客户端命令行(hive/beeline2)和JDBC驱动程序和数据进行交互。
定位:离线数据仓库
特性:
1、可以使用SQL方便的进行ETL,报表和数据分析
2、一种对各种数据格式施加结构的机制,可以对多种数据结构进行映射,比如json格式数据,parquet格式数据,指定字符分割的文本文件
3、文件可以存储在Apache HDFS、HBase等文件系统中
4、可以通过Apache Tez™, Apache Spark™, or MapReduce执行查询计划
5、通过 Hive LLAP, Apache YARN and Apache Slider执行亚秒级查询
6、HPL-SQL的程序语言,hive program language
7、hive支持标准的SQL函数,包括SQL:2003 and SQL:2011的很多新特性
8、用户可以自定义UDFs(用户自定义函数),UDAFs(用户自定义聚合函数),UDTFs(用户自定义表函数)
两大组件:
HCatalog: Hive的一个组件.它是基于Hadoop之上的一个表和存储管理层,它允许用户使用不同数据处理工具,像Pig和MapReduce,Pig和MapReduce更容易地在网格上读取和写入数据。如下图所示,HCatlog对底层存储的文件做了一层封装,方便MapReduce、Pig进行操作。

WebHCat:提供一个运行Hadoop MapReduce(或YARN)的服务,Pig、Hive任务可以通过HTTP(REST样式)接口执行Hive元数据操作。
二、Hive架构:
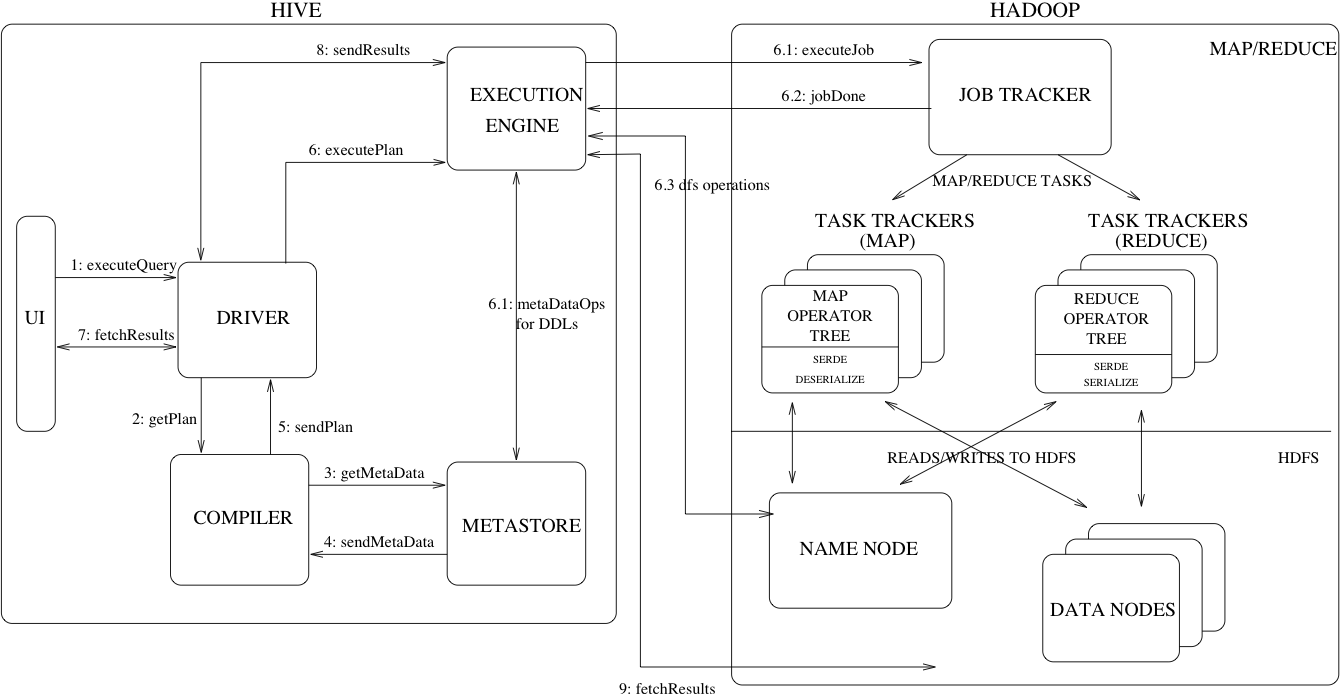
上图,展示了Hive的主要组件以及和hadoop的交互。Hive的主要组件如下:
- UI(用户界面):供用户向系统提交查询和其他操作。截至2011年(官网这部分更新的不是很及时啊),该系统有一个命令行界面,并正在开发一个基于web的GUI。
- Driver(驱动):接收UI查询的组件。这个组件实现了会话句柄的概念,并提供了基于JDBC/ODBC,执行和获取数据api。
- Compiler(编译器):解析查询的组件,对不同的查询块和查询表达式进行语义分析,最后在表和从metastore查找到对应分区元数据的帮助下,生成一个执行计划。
- Metastore(元数据存储):这个组件存储了数据仓库中所有表和分区结构化的信息,包括列和列类型信息、读写数据所需的序列化器和反序列化器以及存储数据的相应HDFS文件。
- Execution Engine(执行引擎):执行编译器创建的执行计划的组件。这个计划是由多个阶段构成的DAG。执行引擎管理执行计划的不同阶段之间的依赖关系,并在决定在那些系统组件上执行这些阶段。
上图,还显示了一个典型查询是如何在Hive系统中运行的。
- UI通过调用执行接口连接到Driver(图中的步骤1 executeQuery)。
- Driver创建一个会话处理查询并将此查询发送到Compiler生成一个执行计划(步骤2 getPlan)。
- Compiler从metastore得到必要的元数据(步骤3 getMetaData和步骤4 sendMetaData)。此元数据用于在查询树中,对表达式进行类型检查,以及根据查询谓词修剪分区。(换言之,就是这个地方会进行字段检查,类型检查,并且查询条件去选择合适的分区)
- Compiler(步骤5 sendPlan)生成的计划是由多个阶段组成的DAG,每个阶段要么一个map/reduce作业,要么是一个元数据操作或者是HDFS上的操作。对于map/reduce阶段来说,计划包含map操作树(map操作)和reduce操作符树(reduce操作)。
- Execution Engine将这些阶段提交给适当的组件(步骤6、6.1、6.2和6.3)。在每个任务(mapper/reducer)中,与表或中间输出相关联的反序列化器,主要用来从HDFS文件中读取行,这些行通过关联的运算符树进行传递。
- 一旦输出生成,就通过序列化器将其写入一个临时HDFS文件(如果操作不需要reducer,这种情况会在mapper中发生)。临时文件用于为计划的后续map/reduce 阶段提供数据。
- 对于DML操作,最终的临时文件将移动到表的位置。此方案用于确保不读取脏数据(文件重命名是HDFS中的原子操作)。
- 对于查询操作,执行引擎直接从HDFS读取临时文件的内容,作为UI从Driver获取数据的一部分(步骤7、8和9)。
本文参考链接:https://cwiki.apache.org/confluence/display/Hive/Design#