简介
VXLAN是网络虚拟化场景中广泛部署的隧道协议,OVS-DPDK中已经支持VXLAN类型的VTEP (virtual tunnel end point)。VXLAN隧道在数据面引入了报文封装/解封装的操作,且在ingress方向由于VXLAN报文携带两层L2-L4 header,OVS数据面需要通过recirculation机制对报文一层一层解析处理,给整体的转发流程带来了很大的overhead。Intel®E810 网络适配器具有非常灵活的报文解析、exact match、wildcard match模块, 可以广泛地支持多种网络协议,包括隧道协议例如VXLAN、GRE等。E810的可编程packet pipeline可以用于全面匹配VXLAN报文外层和内层中的各个协议字段,卸载OVS-DPDK数据面中大量的包头解析、流表查找操作,显著降低网络隧道所引入的overhead。结合E810硬件加速技术和一系列的软件优化手段,OVS-DPDK在VXLAN场景下的性能得到大幅提升。
E810 programmable pipeline overview
E810 pipeline的各个包处理阶段都是可以灵活配置的,parser可以通过parse graph解析出数据包的packet type, 为每个packet生成context metadata, 其对报文的解析深度可达512B,足够覆盖典型的隧道协议报文和各种复杂协议报文。DDP (dynamic device personalization) 可以针对特定应用场景进一步扩展E810 parser支持的协议。基于parser的结果,相应的profile会从报文中提取各个关键字段作为field vector用于后续Switch, ACL和Classification Filer的lookup key。E810 ACL基于TCAM (ternary content addressable memory) 可支持任意bit通配查找,flow director模块提供16K的规则容量,其匹配域可以覆盖隧道报文内外双层的各个关键字段。

OVS flow cache层级结构
OVS-DPDK通过用户态驱动程序从网卡上获取到报文后,会按照用户定义的Open Flow规则进行转发。OVS为了加速流表查找的速度引入两层flow cache。EMC (exact match cache) 支持精确匹配,速度最快,但是容量较小,所以在flow数目增大时,EMC的cache命中率会降低。数据路径分类器(DPCLS)是第二层缓存,它通过元组空间搜索查找到对应的megaflow,其查找代价相比于EMC更高。如果这两层flow cache都没有命中,那么packet会被送到slow path并按照完整的Open Flow规则处理(例如ofproto分类)。对于VXLAN或者其他类型的隧道报文,packet recirculation导致一个报文处理周期会涉及到多次packet header解析和流表查询。

注:由于篇幅限制,本文暂不考虑SMC(signature match cache),OVS默认关闭此选项。
基于E810软硬件协同设计优化VXLAN
OVS已经支持基本的HW offload框架,OVS内部的flow表示被转化成基于DPDK rte_flow的描述后通过rte_flow_create() API将流表规则下发到硬件,后续OVS接收到的报文将会被硬件打上flow mark标签,OVS可以迅速地从flow mark索引到相应的flow并执行其action。对于VXLAN或者其他类型的隧道协议,OVS HW offload框架需要将软件data path中分别用于VXLAN外层匹配和内层匹配的两条flow合并成一个完整的VXLAN规则,然后将这条较宽的规则下发到硬件中。E810的flow director可以完整地支持VXLAN和其他隧道类型报文的各个协议字段。如下图左侧所示,当一条流的首包到达OVS时,由于快速路径cache miss报文会进入slow path处理并触发flow offload, 后续来自相同流的VXLAN报文将会被E810的flow director匹配并打上flow mark, OVS根据上报的flow mark可以索引到相应的flow,直接执行转发。硬件卸载帮助软件bypass两次软件包解析和流表查询,大幅简化OVS数据路径。
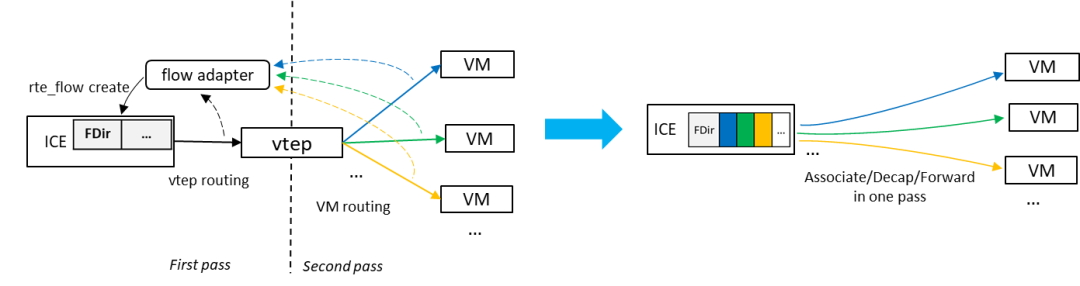
同时,针对OVS的部署场景和VXLAN流量模型,硬件加速配合软件性能调优可以进一步提升OVS的转发效率。下图示意OVS-DPDK VXLAN的网络拓扑结构,OVS网桥通过DPDK vhost-user接口和虚拟机中的virtio设备通信,VXLAN VTEP负责对VXLAN流量做包头的封装/解封装。根据每个端口的实时速率动态调整OVS对各端口的轮询频率可以让OVS更加高效地调用vhost-user的收发包接口;对于同一个mini flow的报文,计算一次哈希值然后重复使用以减少哈希计算的开销;针对流量中主要的flow pattern,例如VXLAN,声明相应的DPCLS lookup function以得到被编译器充分优化过的查找实现,同时对于这些主要的数据包类型实现简洁高效的flow key提取。其他通用的软件调优技术同样适用,例如实现封装/解封装的批处理模式,调整队列的长度以控制OVS的memory footprint。

基于上述的软硬件协同性能调优,OVS-DPDK在1 million VXLAN flow, 128B 双向流量的测试场景中达到了约75%的性能提升,同时可保证OVS升级对guest用户不感知。
结语
通过OVS-DPDK 软硬件协同优化的方式,利用E810网络适配器的可编程packet pipeline 可以显著提高诸如VXLAN等隧道报文的转发效率。其他的场景或者workload也可以借鉴这个方法,充分利用E810的switch, ACL, flow director, advanced RSS等功能实现更高效的数据面包处理。
References
参考文献
1.Introduction to intel Ethernet Flow Director and Memcached Performance, intel White Paper.
2.https://software.intel.com/content/www/us/en/develop/articles/ovs-dpdk-datapath-classifier.html