In my previous blog post I described gVisor as 'some stuff I hardly can really understand'.
Technology is not only about code, understanding where it comes from, why and how it has been done, do helps to understand the design decision and actual goals.
tl;dr: gVisor has been open-sourced recently but it has been running Google App Engine and Google Cloud Functions for years. It is a security sandbox for application, acting as a "Virtual kernel", but not relying on an hypervisor (unlike KataContainers). Now being open-source we can expect gVisor to support more application runtimes and being portable enough so it can replace Docker's runc at some point for those interested in this additional isolation level.
Being in San Francisco for DockerCon'18 I went to visit Google office to meet Googler Ludovic Champenois, and Google Developer Advocate David Gageot, who kindly explained me gVisor history and design. In the meantime some of the informations required to fully understand gVisor became public, so I now can blog on this topic. By the way, Ludo made a presentation on this topic at BreizhCamp, even gVisor name has not been used this was all about it.
History
gVisor introduce itself as "sandboxing for linux applications". To fully understand this, we should ask "Where does it come from" ?
I assume you already heard about Google App Engine. GAE was launched 10 years ago, and allowed to run Python application (then later Java) on google infrastructure for the cost of actually consumed resources. No virtual machine to allocate. Nothing to pay when application is not in use. If they did this in 2018, they probably would have named something like "Google Serverless Engine".
Compared to other cloud hosting platform like Amazon, Google don't rely on virtual machines to isolate applications running on his infrastructure. They made this crazy bet they can provide enough security layers to directly run arbitrary user payload on a shared operating system.
A public cloud platform like Google Cloud is a privileged target for any hacker. in addition, GAE applications do run on the exact same Borg infrastructure as each and every Google services. So the need for security in depth, and Google did invest a lot in security. For sample, the hardware they use in DataCenters do include a dedicated security chip to prevent hardware/firmware backdoors.
When GAE for java was introduced in 2009, it came with some restrictions. This wasn't the exact same JVM you used to run, but some curated version of it, with some API missing. Cause for those restrictions is for google engineers to analyse each and every low level feature of the JRE that would require some dangerous privileges on their infrastructure. Typically, java.lang.Thread was a problem.
Java 7 support for GAE has been announced in 2013, 2 years after Java 7 was launched. Not because Google didn't wanted to support Java, nor because they're lazy, but because this one came with new internal feature invokedynamic. This one introduced a significant new attack surface and required a huge investment to implement adequate security barriers and protections.
Then came Java 8, with lambdas and many other internal changes. And plans for Java 9 with modules was a promise for yet more complicated and brain-burner challenges to support Java on GAE. So they looked for another solution, and here started internal project that became gVisor.
Status
gVisor code you can find on Google's github repository is the actual code running Google App Engine and Google Cloud Function (minus some Google specific pieces which are kept private and wouldn't make any sense outside Google infrastructure).
When Kubernetes was launched, it was introduced as a simplified (re)implementation of Google's Borg architecture, designed for lower payloads (Borg is running *all* Google infra as a huge cluster of hundreds thousands nodes). gVisor isn't such a "let's do something similar in oss" project, but a proven solution, at least for payloads supported by Google Cloud platform.
To better understand it's design and usage, we will need to get into details. Sorry if you get lost in following paragraph, if you don't care you can directly scroll down to the kitten.
What's a kernel by the way ?
"Linux containers", like the ones you use to run with Docker (actually runc, default low level container runtime), but also LXC, Rkt or just systemd (yes, systemd is a plain container runtime, just require a way longer command line to setup :P), all are based on Linux kernel features to filter system calls, applying visibility and usage restrictions on shared system resources (cpu, memory, i/o). They all delegate to kernel responsibility to do this right, which as you can guess is far from being trivial and is the result of a decade of development by kernel experts.
Linux defines a "user-space" (ring 3) and 'kernel-space" (ring 0) as CPU execution levels. "rings" are protection levels implemented by hardware: on can get into a higher ring (during boot), but not the opposite, and each ring only can access a subset of hardware operations.

Linux defines a "user-space" (ring 3) and 'kernel-space" (ring 0) as CPU execution levels. "rings" are protection levels implemented by hardware: on can get into a higher ring (during boot), but not the opposite, and each ring only can access a subset of hardware operations.
An application runs in user-space. Doing so there's many hardware related operation it can't use: for sample, allocating memory, which require interactions with hardware and is only available in kernel-space. To get some memory, application has to invoke a system call, a predefined procedure implemented by kernel. When application execute malloc, it actually delegates to kernel the related memory operation. Buy remember : there's no way to move from user-space to kernel-space, so this not just a function call.
System calls implementation depends on architecture. on intel architectures it relies on interruption, which is a signal the hardware uses to handle asynchronous tasks and external events, like timers, a key pressed on keyboard or incoming network packet. Software also can trigger some interruptions, and passing parameters to kernel relies on values set in CPU's registries.
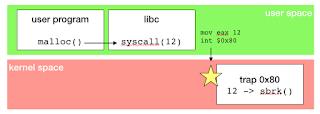
When an interruption happens, the execution of the current program on the CPU is suspended, and a trap assigned to the interruption is executed in kernel-space. When the trap completes, the initial program is restored and follow up it's execution. As interruption only allows to pass few parameters, typically a system call number and some arguments, there's no risk for application to inject illegal code in kernel-space (as long as there's no bug in kernel implementation, typically a buffer overflow weakness).
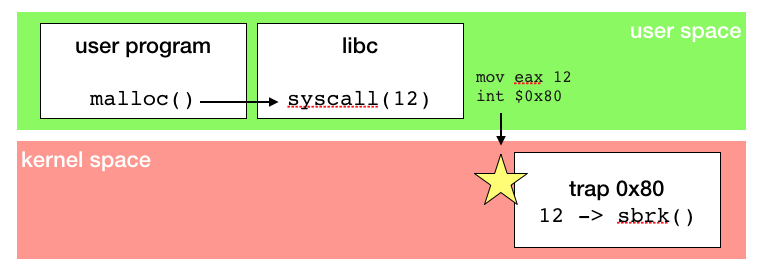
When an interruption happens, the execution of the current program on the CPU is suspended, and a trap assigned to the interruption is executed in kernel-space. When the trap completes, the initial program is restored and follow up it's execution. As interruption only allows to pass few parameters, typically a system call number and some arguments, there's no risk for application to inject illegal code in kernel-space (as long as there's no bug in kernel implementation, typically a buffer overflow weakness).
Kernel trap handling the system call interruption will proceed to memory allocation. Doing so it can apply some for restrictions (so your application can't allocate more that xxx Mb as defined by control-group) and implement memory allocation on actual hardware.
What's wrong with that ? Nothing from a general point of view, this is a very efficient design, and system call mechanism acts as a very efficient filter ... as long as everything in kernel is done right. In real world software comes both with bugs and unexpected security design issues (not even considering hardware ones), so does the kernel. And as Linux kernel protections use by Linux Containers take place within kernel space, anything wrong here can be abused to break security barriers.
 I you check number of CVE per year for linux kernel you will understand being a security engineer is a full time job. Not that linux kernel is badly designed, just that a complex software used by billions devices and responsible to manage shared resources with full isolation on a large set of architectures is ... dawn a complex beast !
I you check number of CVE per year for linux kernel you will understand being a security engineer is a full time job. Not that linux kernel is badly designed, just that a complex software used by billions devices and responsible to manage shared resources with full isolation on a large set of architectures is ... dawn a complex beast !
Congrats to Linux kernel maintainer by the way, they do an awesome job !
Google do have it's own army of kernel security engineers, maintaining a custom kernel : both on purpose for hardware optimisation and to enforce security by removing/replacing/strenghtening everything that may impact their infrastructure, also contributing to mainstream Linux kernel when it makes sense.
But that's still risky : if someone discover an exploit on linux kernel, he might not be smart enough to keep this private or could even try to hack Google.
Additional isolation : better to be safe than sorry.
A possible workaround to this risk is to add one additional layer of isolation / abstraction : hypervisor isolation.
To provide more abstraction, a Virtual Machine do rely on hardware capability (typically: intel VT-X) to offer yet another level of interruption based isolation. Let's see how malloc will operate when application runs inside a VM :
- application calls libC's malloc which actually invoke system call number 12 by triggering an interruption.
- interruption is trapped in kernel-space as configured on hardware during operating system early stage boot.
- kernel access hardware to actually allocate some physical memory if legitimate. On bare metal the process would end here, but we are running in a VT-X enabled virtual machine
- as guest kernel is virtualized, it actually run on hosts as a user-space program. VT-X make it possible to have two parallel ring levels. So attempt to access hardware do trigger VMEXIT and let hypervisor to execute trapping instructions to act accordingly. in KVM architecture this means switching into hosts' user-mode as soon as possible (!) and use user-mode QEmu for hardware emulation.
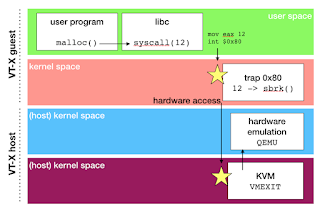
Hypervisor is configured to trap this interruption, and translating the low level hardware access into some actual physical memory allocation, based on emulated hardware and Virtual Machine configuration. So when VM's kernel things it's allocating memory block xyz on physical memory, it's actually asking hypervisor to allocate on an emulated memory model, and hypervisor can detect an illegal memory range usage. security++
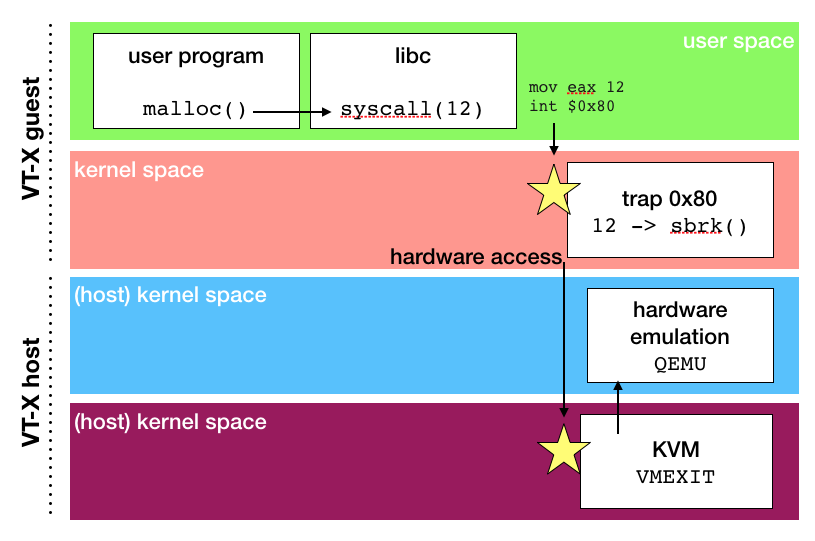
Hypervisor is configured to trap this interruption, and translating the low level hardware access into some actual physical memory allocation, based on emulated hardware and Virtual Machine configuration. So when VM's kernel things it's allocating memory block xyz on physical memory, it's actually asking hypervisor to allocate on an emulated memory model, and hypervisor can detect an illegal memory range usage. security++
This second level of isolation would prevent a bug in virtual machine kernel to expose actual physical resources. It also ensure the resources management logic implemented by guest kernel is strictly limited to a set of higher-level allocated resources. Hacking both the kernel then the hypervisor is possible in theory, but extremely hard in practice.
KataContainers is an exact implementation of this idea : a docker image when ran by runV (KataContainers' alternative to Docker's runC) do use a KVM hypervisor to run a just-enough virtual machine so the container can start. And thanks to OpenContainerInitiative and docker's modular design you can switch from one to the other.
KataContainers is an exact implementation of this idea : a docker image when ran by runV (KataContainers' alternative to Docker's runC) do use a KVM hypervisor to run a just-enough virtual machine so the container can start. And thanks to OpenContainerInitiative and docker's modular design you can switch from one to the other.