惠春阳, Intel 软件工程师, 主要从事SPDK开发和存储软件性能优化的工作。
文章转载自DPDK与SPDK开源社区
随着存储技术的发展, 对存储性能的不懈追求, 高性能存储开始探索向内存通道的迁移。 在这样的情况下, NVDIMM 技术便应运而生了。

NVDIMM (Non-Volatile Dual In-line Memory Module) 是一种可以随机访问的, 非易失性内存。非易失性内存指的是即使在不通电的情况下, 数据也不会消失。因此可以在计算机掉电 (unexpected power loss), 系统崩溃和正常关机的情况下, 依然保持数据。 NVDIMM 同时表明它使用的是 DIMM 封装, 与标准DIMM 插槽兼容, 并且通过标准的 DDR总线进行通信。考虑到它的非易失性, 并且兼容传统DRAM接口, 又被称作Persistent Memory。
种类
目前, 根据 JEDEC 标准化组织的定义, 有三种NVDIMM 的实现。分别是:
NVDIMM-N
指在一个模块上同时放入传统 DRAM 和 flash 闪存。 计算机可以直接访问传统 DRAM。 支持按字节寻址, 也支持块寻址。通过使用一个小的后备电源,为在掉电时, 数据从DRAM 拷贝到闪存中提供足够的电能。当电力恢复时, 再重新加载到DRAM 中。
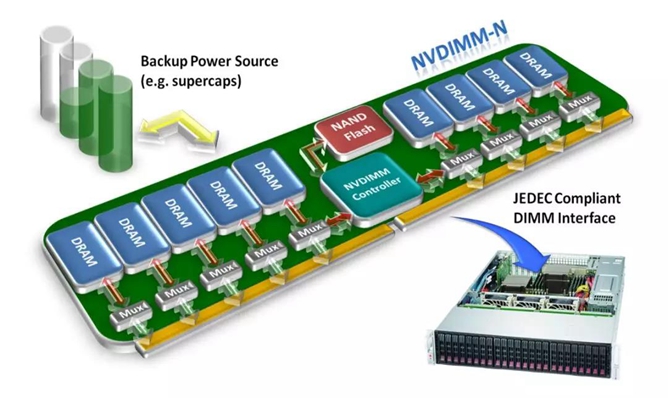
NVDIMM-N 的主要工作方式其实和传统 DRAM是一样的。因此它的延迟也在10的1次方纳秒级。 而且它的容量, 受限于体积, 相比传统的 DRAM 也不会有什么提升。
同时它的工作方式决定了它的 flash 部分是不可寻址的。而且同时使用两种介质的作法使成本急剧增加。 但是, NVDIMM-N 为业界提供了持久性内存的新概念。目前市面上已经有很多基于NVIMM-N的产品。
NVDIMM-F
指使用了 DRAM 的DDR3或者 DDR4 总线的flash闪存。我们知道由 NAND flash 作为介质的 SSD, 一般使用SATA, SAS 或者PCIe 总线。使用 DDR 总线可以提高最大带宽, 一定程度上减少协议带来的延迟和开销。 不过只支持块寻址。
NVDIMM-F 的主要工作方式本质上和SSD是一样的。因此它的延迟在 10的1次方微秒级。它的容量也可以轻松达到 TB 以上。
NVDIMM-P
这是一个目前还没有发布的标准 (Under Development)。预计将与DDR5 标准一同发布。按照计划,DDR5将比DDR4提供双倍的带宽,并提高信道效率。这些改进,以及服务器和客户端平台的用户友好界面,将在各种应用程序中支持高性能和改进的电源管理。
NVDIMM-P 实际上是真正 DRAM 和 flash 的混合。它既支持块寻址, 也支持类似传统 DRAM 的按字节寻址。 它既可以在容量上达到类似 NAND flash 的TB以上, 又能把延迟保持在10的2次方纳秒级。
通过将数据介质直接连接至内存总线, CPU 可以直接访问数据, 无需任何驱动程序或 PCIe 开销。而且由于内存访问是通过64 字节的 cache line, CPU 只需要访问它需要的数据, 而不是像普通块设备那样每次要按块访问。
Intel 公司在2018年5月发布了基于3D XPoint™ 技术的Intel® Optane™ DC Persistent Memory。可以认为是NVDIMM-P 的一种实现。

硬件支持
应用程序可以直接访问NVDIMM-P, 就像对于传统 DRAM那样。这也消除了在传统块设备和内存之间页交换的需要。但是, 向持久性内存里写数据是和向普通DRAM里写数据共享计算机资源的。包括处理器缓冲区, L1/L2缓存等。
需要注意的是, 要使数据持久, 一定要保证数据写入了持久性内存设备, 或者写入了带有掉电保护的buffer。软件如果要充分利用持久性内存的特性, 指令集架构上至少需要以下支持:
写的原子性
表示对于持久性内存里任意大小的写都要保证是原子性的, 以防系统崩溃或者突然掉电。IA-32 和 IA-64 处理器保证了对缓存数据最大64位的数据访问 (对齐或者非对齐) 的写原子性。 因此, 软件可以安全地在持久性内存上更新数据。这样也带来了性能上的提升, 因为消除了copy-on-write 或者 write-ahead-logging 这种保证写原子性的开销。
高效的缓存刷新(flushing)
出于性能的考虑, 持久性内存的数据也要先放入处理器的缓存(cache)才能被访问。经过优化的缓存刷新指令减少了由于刷新 (CLFLUSH) 造成的性能影响。
a. CLFLUSHOPT 提供了更加高效的缓存刷新指令
b. CLWB (Cache Line Write Back) 指令把cache line上改变的数据写回内存 (类似CLFLUSHOPT), 但是无需让这条 cache line 转变成无效状态(invalid, MESI protocol), 而是转换成未改变的独占状态(Exclusive)。CLWB 指令实际上是在试图减少由于某条cache line刷新所造成的下次访问必然的cache miss。
提交至持久性内存(Committing to Persistence)
在现代计算机架构下, 缓存刷新的完成表明修改的数据已经被回写至内存子系统的写缓冲区。 但是此时数据并不具有持久性。为了确保数据写入持久性内存, 软件需要刷新易失性的写缓冲区或者在内存子系统的其他缓存。 新的用于持久性写的提交指令 PCOMMIT 可以把内存子系统写队列中的数据提交至持久性内存。
非暂时store操作的优化(Non-temporal Store Optimization)
当软件需要拷贝大量数据从普通内存到持久性内存中时(或在持久性内存之间拷贝), 可以使用弱顺序, 非暂时的store操作 (比如使用MOVNTI 指令)。 因为Non-temporal store指令可以隐式地使要回写的那条cache line 失效, 软件就不需要明确地flush cache line了(see Section 10.4.6.2. of Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1)。
总结
本期我们介绍了NVDIMM 的几种实现方式, 以及为了发挥NVDIMM-P 的性能所做的硬件上的优化和支持。后面我们会继续介绍软件方面的支持, 包括编程模型, 编程库, SPDK方面的支持等。敬请期待
随着存储技术的发展,对存储性能的不懈追求,高性能存储开始探索向内存通道的迁移。在这样的情况下, NVDIMM 技术便应运而生了。

NVDIMM (Non-Volatile Dual In-Line Memory Module) 是一种可以随机访问的,非易失性内存, 又被称作PMem (Persistent Memory)。在之前的 NVDIMM上篇中,我们介绍了NVDIMM几种硬件上的实现方式,以及为了支持和优化性能所做的硬件上的改变。今天,我们来讨论一下为了充分发挥NVDIMM的性能,软件方面做了哪些支持。有些人可能会有疑问, 为什么用起来这么麻烦?既然是持久性内存,不是应该关机什么样, 开机什么样, 就可以了吗? 其实目前来看, 这种想法还不会变为现实。 因为除了DRAM是易失性的,比如 cache,寄存器这种也是易失性的。仅仅把内存做成持久性的也不能达成这样的目的。另一个问题是, memory leak。如果发生了内存泄漏, 重启一下就好了。 那如果是持久性内存的泄漏呢?这也是一个很棘手的问题。Pmem有些方面类似于内存,也有些方面类似于存储。但是,通常上我们不会认为Pmem能够替代内存或存储。其实,可以把它看作是一种补充,填补了内存和存储之间巨大的差异。
SPDK 在 17.10 中开始引入对于Pmem的支持。Pmem在SPDK的bdev层暴露为一个块设备, 使用快设备接口和上层进行通信。如图(1)所示。
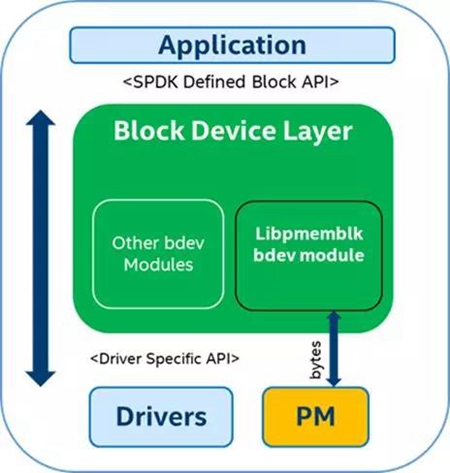
从图中我们可以看到libpmemblk 把块操作转换成了字节操作。它是怎么做到的呢? 在介绍libpmemblk 和 它背后的PMDK之前, 我们了解一下基础知识。
mmap和DAX
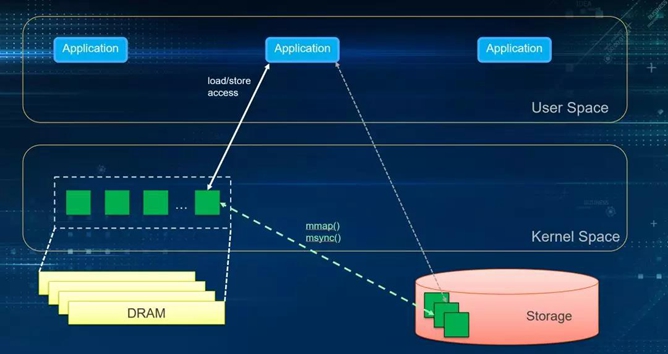
首先,我们来看传统的I/O方式, 即缓存I/O (Buffered I/O). 大多数操作系统默认的IO操作方式都是缓存IO。该机制使IO数据缓存在操作系统的page cache 中, 也就是说, 数据会被先拷贝到操作系统的内核空间的缓冲区中,然后才会从内核空间的缓冲区拷贝到指定的用户地址空间。

在Linux 中, 这种访问文件的方式就是通过read/write 系统调用来实现,如图(2)。接下来, 我们比较一下内存映射IO mmap().
接下来, 我们比较一下内存映射IO mmap().

通过mmap获得了对应文件的一个指针,然后就像操作内存一样进行赋值或者做memcpy/strcpy. 这种我们称之为load/store操作(这种操作一般需要msync、fsync来落盘)。
mmap因为建立了文件到用户空间的映射关系, 可以看作是把文件直接拷贝到用户空间,减少了一次数据拷贝。但是, mmap依然需要依靠page cache。
讲完了mmap, 那么DAX是什么呢?DAX即direct access,这个特性是基于mmap的。而DAX的区别在于完全不需要page cache. 直接对存储设备访问。 所以它就是为了NVDIMM而生的。应用对于mmap的文件操作, 是直接同步到NVDIMM上的。DAX目前在XFS, EXT4, Windows的 NTFS 上都已经支持。需要注意的是, 使用这个模式, 要对应用程序或者文件系统进行修改。
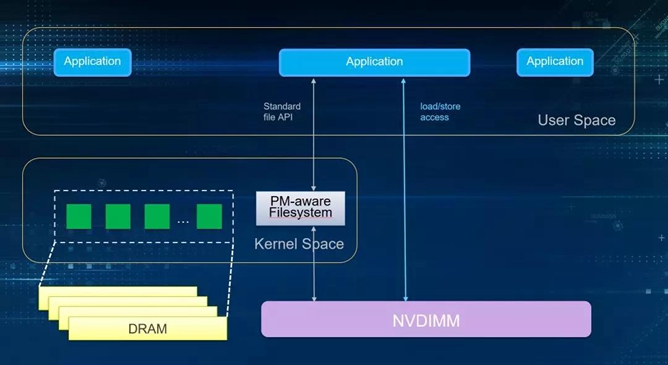
NVM Programming Model
NVM Programming Model 大致定义了三种使用方式。
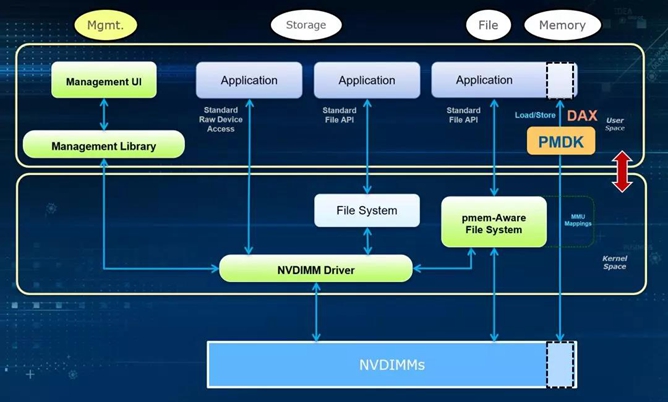
1.最左边Management 主要是通过driver提供的API对NVDIMM进行管理, 比如查看容量信息, 健康状态, 固件版本, 固件升级, 模式配置等等。
2.中间, 作为存储快设备使用, 使用支持NVDIMM driver 的文件系统和内核, 应用程序不用做任何修改,通过标准文件接口访问NVDIMM。
3.第三种, 基于文件系统的DAX特性,通过load/store操作,不需要page cache, 同步落盘。没有系统调用, 没有中断。这也是NVM Programming Model 的核心, 能够充分释放NVDIMM的性能优势。但它的缺点在于,应用程序可能需要做一下改变。
PMDK
libpmemblk 实现了一个驻留在pmem中的同样大小的块的数组。里面每个块对于突然掉电,程序崩溃等情况依然保持原子事务性。libpmemblk是基于libpmem库的。
libpmem是PMDK中提供的一个更底层的库, 尤其是对于flush的支持。它能够追踪每次对pmem的store操作,并保证数据落盘为持久性数据。
除此以外, PMDK 还提供了其他编程库, 比如libpmemobj, libpmemlog, libvmmalloc 等。感兴趣的同学可以访问http://pmem.io/pmdk/ 获取更多信息。
SPDK实战
bdevperf测模拟NVDIMM性能
(1) 创建一个虚拟的Pmem bdev
|
1
2
|
./configure --with-pmdk
make
|
PMDK 已经在一些新的Linux发行版中被引入。如果configure出错,请到https://github.com/pmem/pmdk 自行安装PMDK库。
接下来, 我们可以通过SPDK RPC命令来建立一个pmem_pool。
|
1
|
rpc.py create_pmem_pool /path/to/pmem_pool <TotalSize (MB) > <BlockSize>
|
这里假设我们没有一个真正的NVDIMM做测试, 所以pmem_pool的路径就随便选择一个就好。比如:
|
1
|
rpc.py create_pmem_pool /mnt/pmem 128 4096
|
我们也可以用pmem_pool_info来获取创建pmem_pool的信息:
|
1
|
rpc.py pmem_pool_info /path/to/pmem_pool
|
或者,删除刚创建的pmem_pool:
|
1
|
rpc.py delete_pmem_pool /path/to/pmem_pool
|
然后, 我们在我们创建的pmem_pool上, 建立一个bdev块设备:
|
1
|
rpc.py construct_pmem_bdev /path/to/pmem_pool -n pmem_bdev_name
|
(2) 更新配置文件
更改/path/to/spdk/test/bdev/bdev.conf.in, 只保留Pmem配置的部分。
|
1
2
|
[Pmem]
Blk <pmemblk pool file name> <bdev name>
|
Example:
|
1
2
|
[Pmem]
Blk /mnt/pmem-pool pmem-bdev
|
(3) bdevperf 测试
|
1
|
./bdevperf -c ../bdev.conf.in -q <iodepth> -t <time> -w <io pattern type: write|read|randwrite|randread>-o <io size in bytes>
|
Example command:
|
1
2
|
./bdevperf -c ../bdev.conf.in -q 128 -t 100 -w write -o 4096
./bdevperf -c ../bdev.conf.in -q 1 -t 100 -w randwrite -o 4096
|
结语
至此, 对于NVDIMM硬件和软件上的不同, 大家都有了一个大致的认识。Intel 在2018年5月发布了基于3D XPoint™ 技术的Intel® Optane™ DC Persistent Memory, 引发了NVDIMM爆点。如果你对NVDIMM的用法很感兴趣,或者对于NVDIMM的应用有好的想法, 欢迎通过私信或者在评论区评论交流。希望大家继续关注NVDIMM和SPDK技术。