https://kernelgo.org/virtio-overview.html
http://lihanlu.cn/virtio-frontend-kick/
Qemu Vhost Block架构分析
https://blog.csdn.net/u012377031/article/details/38186329
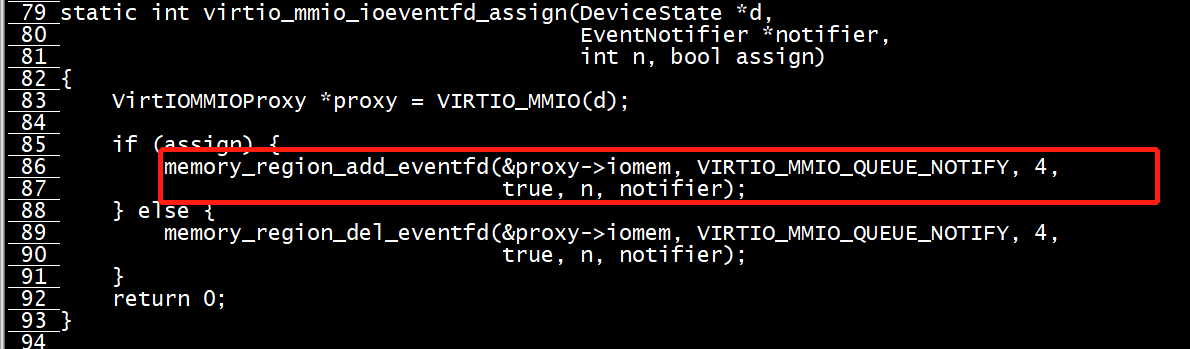
virtio guest notifier和host notifier分别使用不同的ioeventfd和irqfd
1、kick产生,如果该eventfd是由qemu侧来监听的,则会执行对应的qemu函数kvm_handle_io();如果是vhost来监听的,则直接在vhost内核模块执行vhost->handle_kick()。
1、 eventfd 一半的用法是用户态通知用户态,或者内核态通知用户态。例如 virtio-net 的实现是 guest 在 kick host 时采用 eventfd 通知的 qemu,然后 qemu 在用户态做报文处理。但 vhost-net 是在内核态进行报文处理,guest 在 kick host 时采用 eventfd 通知的是内核线程 vhost_worker。所以这里的用法就跟常规的 eventfd 的用法不太一样。
虚拟机与物理机的通信通过vring来实现数据交互,这之间存在一种io的通信机制。
-
主机通知客户机是通过注入中断来实现,虚拟设备连在模拟的中断控制器上,有自己的中断线信息,PCI设备的中断信息会被写入该设备的配置空间
-
客户机通知主机是通过virtio读写内存来实现的。
上面第二条分有两类:MMIO和PIO。MMIO是通过mmap()像写内存一样读写虚拟设备,比如内存。PIO(就是通常意义上的io端口)通过hypervisor捕获设备io来实现虚拟化。两者的区别是:MMIO是通过内存的异常来进行,PIO则是通过io动作的捕获。
virtio是KVM环境下的I/O虚拟化的框架,目前已经使用到的虚拟化设备包括block、net、scsi,本质是guest os与host os间的一种高效通信机制。本文旨在对virtio通信用到的eventfd进行分析。为了描述简单,一般来说,称guest侧通知host侧的行为为kick,host侧通知guset侧的行为为call。
参考资料:
1. virtio spec
2. Virtio 基本概念和设备操作
3. note
1. 什么是eventfd?
eventfd是只存在于内存中的文件,通过系统调用sys_eventfd可以创建新的文件,它可以用于线程间、进程间的通信,无论是内核态或用户态。其实现机制并不复杂,参考内核源码树的fs/eventfd.c文件,看数据结构struct eventfd_ctx的定义:
struct eventfd_ctx {
struct kref kref;
wait_queue_head_t wqh;
/*
* Every time that a write(2) is performed on an eventfd, the
* value of the __u64 being written is added to "count" and a
* wakeup is performed on "wqh". A read(2) will return the "count"
* value to userspace, and will reset "count" to zero. The kernel
* side eventfd_signal() also, adds to the "count" counter and
* issue a wakeup.
*/
__u64 count;
unsigned int flags;
};eventfd的信号实际上就是上面的count,write的时候对其++,read的时候则清零(并不绝对正确)。wait_queue_head wqh则是用来保存监听eventfd的睡眠进程,每当有进程来epoll、select且此时不存在有效的信号(count <= 0),则sleep在wqh上。当某一进程对该eventfd进行write的时候,则会唤醒wqh上的睡眠进程。代码细节参考eventfd_read(), eventfd_write()。
virtio用到的eventfd其实是kvm中的ioeventfd机制,是对eventfd的又一层封装(eventfd + iodevice)。该机制不进一步细说,下面结合virtio的kick操作使用来分析,包括两部分:
1. 如何设置:如何协商该eventfd?
2. 如何产生kick信号:是谁来负责写从而产生kick信号?
2. 如何设置?
即qemu用户态进程是如何和kvm.ko来协商使用哪一个eventfd来kick通信。
这里就要用到kvm的一个系统调用:ioctl(KVM_IOEVENTFD, struct kvm_ioeventfd),找一下qemu代码中执行该系统调用的路径:
memory_region_transaction_commit() {
address_space_update_ioeventfds() {
address_space_add_del_ioeventfds() {
MEMORY_LISTENER_CALL(eventfd_add, Reverse, §ion,
fd->match_data, fd->data, fd->e);
}
}
}上面的eventfd_add有两种可能的执行路径:
1. mmio(Memory mapping I/O): kvm_mem_ioeventfd_add()
2. pio(Port I/O): kvm_io_ioeventfd_add()
通过代码静态分析,上面的调用路径其实只找到了一半,接下来使用gdb来查看memory_region_transaction_commit()可能的执行路径,结合vhost_blk(qemu用户态新增的一项功能,跟qemu-virtio或dataplane在I/O链路上的层次类似)看一下设置eventfd的执行路径:
#0 memory_region_transaction_commit () at /home/gavin4code/qemu-2-1-2/memory.c:799
#1 0x0000000000462475 in memory_region_add_eventfd (mr=0x1256068, addr=16, size=2, match_data=true, data=0, e=0x1253760)
at /home/gavin4code/qemu-2-1-2/memory.c:1588
#2 0x00000000006d483e in virtio_pci_set_host_notifier_internal (proxy=0x1255820, n=0, assign=true, set_handler=false)
at hw/virtio/virtio-pci.c:200
#3 0x00000000006d6361 in virtio_pci_set_host_notifier (d=0x1255820, n=0, assign=true) at hw/virtio/virtio-pci.c:884 ---------------- 非vhost也调用
#4 0x00000000004adb90 in vhost_dev_enable_notifiers (hdev=0x12e6b30, vdev=0x12561f8)
at /home/gavin4code/qemu-2-1-2/hw/virtio/vhost.c:932
#5 0x00000000004764db in vhost_blk_start (vb=0x1256368) at /home/gavin4code/qemu-2-1-2/hw/block/vhost-blk.c:189
#6 0x00000000004740e5 in virtio_blk_handle_output (vdev=0x12561f8, vq=0x1253710)
at /home/gavin4code/qemu-2-1-2/hw/block/virtio-blk.c:456
#7 0x00000000004a729e in virtio_queue_notify_vq (vq=0x1253710) at /home/gavin4code/qemu-2-1-2/hw/virtio/virtio.c:774
#8 0x00000000004a9196 in virtio_queue_host_notifier_read (n=0x1253760) at /home/gavin4code/qemu-2-1-2/hw/virtio/virtio.c:1265
#9 0x000000000073d23e in qemu_iohandler_poll (pollfds=0x119e4c0, ret=1) at iohandler.c:143
#10 0x000000000073ce41 in main_loop_wait (nonblocking=0) at main-loop.c:485
#11 0x000000000055524a in main_loop () at vl.c:2031
#12 0x000000000055c407 in main (argc=48, argv=0x7ffff99985c8, envp=0x7ffff9998750) at vl.c:4592整体执行路径还是很清晰的,vhost模块的vhost_dev_enable_notifiers()来告诉kvm需要用到的eventfd。
3. 如何产生kick信号?
大体上来说,guest os觉得有必要通知host对virtqueue上的请求进行处理,就会执行vp_notify(),相当于执行一次port I/O(或者mmio),虚拟机则会退出guest mode。这里假设使用的是intel的vmx,当检测到pio或者mmio会设置vmcs中的exit_reason,host内核态执行vmx_handle_eixt(),检测exit_reason并执行相应的handler函数(kernel_io()),整体的执行路径如下:
vmx_handle_eixt() {
/* kvm_vmx_exit_handlers[exit_reason](vcpu); */
handle_io() {
kvm_emulate_pio() {
kernel_io() {
if (read) {
kvm_io_bus_read() {
}
} else {
kvm_io_bus_write() { vhost方式
ioeventfd_write();
}
}
}
}
}最后会执行到ioeventfd_write(),这样就产生了一次kick信号。
如果该eventfd是由qemu侧来监听的,则会执行对应的qemu函数kvm_handle_io();如果是vhost来监听的,则直接在vhost内核模块执行vhost->handle_kick()。
qemu kmv_handle_io()的调用栈如下所示:
Breakpoint 1, virtio_ioport_write (opaque=0x1606400, addr=18, val=0) at hw/virtio/virtio-pci.c:270
270 {
(gdb) t
[Current thread is 4 (Thread 0x414e7940 (LWP 29695))]
(gdb) bt
#0 virtio_ioport_write (opaque=0x1606400, addr=18, val=0) at hw/virtio/virtio-pci.c:270
#1 0x00000000006d4218 in virtio_pci_config_write (opaque=0x1606400, addr=18, val=0, size=1) at hw/virtio/virtio-pci.c:435
#2 0x000000000045c716 in memory_region_write_accessor (mr=0x1606c48, addr=18, value=0x414e6da8, size=1, shift=0, mask=255) at /home/gavin4code/qemu/memory.c:444
#3 0x000000000045c856 in access_with_adjusted_size (addr=18, value=0x414e6da8, size=1, access_size_min=1, access_size_max=4, access=0x45c689 <memory_region_write_accessor>, mr=0x1606c48)
at /home/gavin4code/qemu/memory.c:481
#4 0x000000000045f84f in memory_region_dispatch_write (mr=0x1606c48, addr=18, data=0, size=1) at /home/gavin4code/qemu/memory.c:1138
#5 0x00000000004630be in io_mem_write (mr=0x1606c48, addr=18, val=0, size=1) at /home/gavin4code/qemu/memory.c:1976
#6 0x000000000040f030 in address_space_rw (as=0xd05d00 <address_space_io>, addr=49170, buf=0x7f4994f6b000 "", len=1, is_write=true) at /home/gavin4code/qemu/exec.c:2114
#7 0x0000000000458f62 in kvm_handle_io (port=49170, data=0x7f4994f6b000, direction=1, size=1, count=1) at /home/gavin4code/qemu/kvm-all.c:1674 ----------非vhost方式
#8 0x00000000004594c6 in kvm_cpu_exec (cpu=0x157ec50) at /home/gavin4code/qemu/kvm-all.c:1811
#9 0x0000000000440364 in qemu_kvm_cpu_thread_fn (arg=0x157ec50) at /home/gavin4code/qemu/cpus.c:930
#10 0x0000003705e0677d in start_thread () from /lib64/libpthread.so.0
#11 0x00000037056d49ad in clone () from /lib64/libc.so.6
#12 0x0000000000000000 in ?? ()至此,整个virtio的evenfd机制分析结束。
[root@bogon qemu]# grep virtio_pci_config_write -rn * hw/virtio/virtio-pci.c:443:static void virtio_pci_config_write(void *opaque, hwaddr addr, hw/virtio/virtio-pci.c:479: .write = virtio_pci_config_write, [root@bogon qemu]#
https://kernelgo.org/virtio-overview.html
给vhost发送事件通知,唤醒
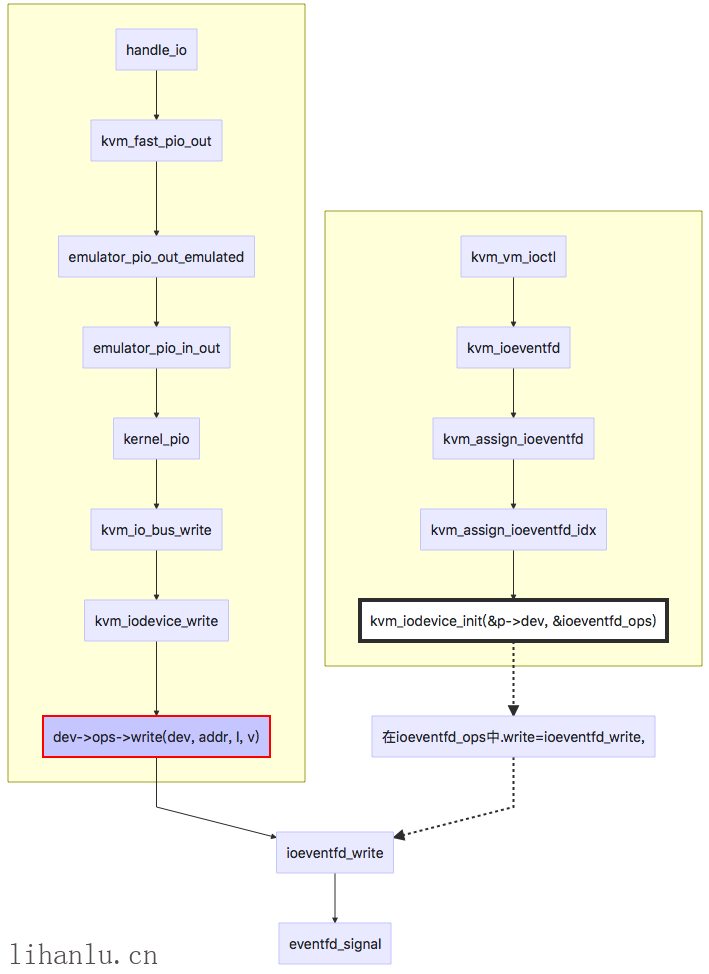
12 > > > kvm_vmx_exit_handlers: [EXIT_REASON_IO_INSTRUCTION> > > > > > handle_io, > > > static int handle_io(struct kvm_vcpu *vcpu) > > > > return kvm_fast_pio_out(vcpu, size, port); > > > > > static int emulator_pio_out_emulated(struct x86_emulate_ctxt *ctxt, int size, unsigned short port, const void *val, unsigned int count) > > > > > > emulator_pio_in_out > > > > > > kernel_pio(struct kvm_vcpu *vcpu, void *pd) > > > > > > > int kvm_io_bus_write(struct kvm_vcpu *vcpu, enum kvm_bus bus_idx, gpa_t addr, > > > > > > > > __kvm_io_bus_write > > > > > > > > > dev->ops->write(vcpu, dev, addr, l, v) > > > > > > > > > dev->ops is ioeventfd_ops 相当ioeventfd_write > > > > > > > > > > eventfd_signal(p->eventfd, 1); > > > > > > > > > > > wake_up_locked_poll(&ctx->wqh, POLLIN);
调用kvm_vm_ioctl给qemu发送事件通知
virtio_pci_config_write --> virtio_ioport_write --> virtio_pci_start_ioeventfd --> virtio_bus_set_host_notifier --> virtio_bus_start_ioeventfd --> virtio_device_start_ioeventfd_impl --> virtio_bus_set_host_notifier --> virtio_pci_ioeventfd_assign --> memory_region_add_eventfd --> memory_region_transaction_commit --> address_space_update_ioeventfds --> address_space_add_del_ioeventfds --> kvm_io_ioeventfd_add/vhost_eventfd_add --> kvm_set_ioeventfd_pio --> kvm_vm_ioctl(kvm_state, KVM_IOEVENTFD, &kick)
accel/kvm/kvm-all.c
946 static MemoryListener kvm_io_listener = { 947 .eventfd_add = kvm_io_ioeventfd_add, 948 .eventfd_del = kvm_io_ioeventfd_del, 949 .priority = 10, 950 }; 951 952 int kvm_set_irq(KVMState *s, int irq, int level) 953 { 954 struct kvm_irq_level event; 955 int ret; 956 957 assert(kvm_async_interrupts_enabled()); 958 959 event.level = level; 960 event.irq = irq; 961 ret = kvm_vm_ioctl(s, s->irq_set_ioctl, &event); 962 if (ret < 0) { 963 perror("kvm_set_irq"); 964 abort(); 965 } 966 967 return (s->irq_set_ioctl == KVM_IRQ_LINE) ? 1 : event.status; 968 }
其实,这就是QEMU的Fast MMIO实现机制。 我们可以看到,QEMU会为每个设备MMIO对应的MemoryRegion注册一个ioeventfd。 最后调用了一个KVM_IOEVENTFD ioctl到KVM内核里面,而在KVM内核中会将MMIO对应的(gpa,len,eventfd)信息会注册到KVM_FAST_MMIO_BUS上。 这样当Guest访问MMIO地址范围退出后(触发EPT Misconfig),KVM会查询一下访问的GPA是否落在某段MMIO地址空间range内部, 如果是的话就直接写eventfd告知QEMU,QEMU就会从coalesced mmio ring page中取MMIO请求 (注:pio page和 mmio page是QEMU和KVM内核之间的共享内存页,已经提前mmap好了)。
#kvm内核代码virt/kvm/eventfd.c中 kvm_vm_ioctl(KVM_IOEVENTFD) --> kvm_ioeventfd --> kvm_assign_ioeventfd --> kvm_assign_ioeventfd_idx # MMIO处理流程中(handle_ept_misconfig)最后会调用到ioeventfd_write通知QEMU。 /* MMIO/PIO writes trigger an event if the addr/val match */ static int ioeventfd_write(struct kvm_vcpu *vcpu, struct kvm_io_device *this, gpa_t addr, int len, const void *val) { struct _ioeventfd *p = to_ioeventfd(this); if (!ioeventfd_in_range(p, addr, len, val)) return -EOPNOTSUPP; eventfd_signal(p->eventfd, 1); return 0; }
virtio_bus_set_host_notifier
hw/block/dataplane/virtio-blk.c:200: r = virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), i, true); hw/block/dataplane/virtio-blk.c:204: virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), i, false); hw/block/dataplane/virtio-blk.c:290: virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), i, false); hw/virtio/virtio.c:2634: r = virtio_bus_set_host_notifier(qbus, n, true); hw/virtio/virtio.c:2663: r = virtio_bus_set_host_notifier(qbus, n, false); hw/virtio/virtio.c:2698: r = virtio_bus_set_host_notifier(qbus, n, false); hw/virtio/virtio-bus.c:263:int virtio_bus_set_host_notifier(VirtioBusState *bus, int n, bool assign) hw/virtio/vhost.c:1345: r = virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), hdev->vq_index + i, hw/virtio/vhost.c:1356: e = virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), hdev->vq_index + i, hw/virtio/vhost.c:1380: r = virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), hdev->vq_index + i, hw/scsi/virtio-scsi-dataplane.c:98: rc = virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), n, true); hw/scsi/virtio-scsi-dataplane.c:178: virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), i, false); hw/scsi/virtio-scsi-dataplane.c:217: virtio_bus_set_host_notifier(VIRTIO_BUS(qbus), i, false); include/hw/virtio/virtio-bus.h:152:int virtio_bus_set_host_notifier(VirtioBusState *bus, int n, bool assign);
263 int virtio_bus_set_host_notifier(VirtioBusState *bus, int n, bool assign) 264 { 265 VirtIODevice *vdev = virtio_bus_get_device(bus); 266 VirtioBusClass *k = VIRTIO_BUS_GET_CLASS(bus); 267 DeviceState *proxy = DEVICE(BUS(bus)->parent); 268 VirtQueue *vq = virtio_get_queue(vdev, n); 269 EventNotifier *notifier = virtio_queue_get_host_notifier(vq); 270 int r = 0; 271 272 if (!k->ioeventfd_assign) { 273 return -ENOSYS; 274 } 275 276 if (assign) { 277 r = event_notifier_init(notifier, 1); 278 if (r < 0) { 279 error_report("%s: unable to init event notifier: %s (%d)", 280 __func__, strerror(-r), r); 281 return r; 282 } 283 r = k->ioeventfd_assign(proxy, notifier, n, true); 284 if (r < 0) { 285 error_report("%s: unable to assign ioeventfd: %d", __func__, r); 286 virtio_bus_cleanup_host_notifier(bus, n); 287 } 288 } else { 289 k->ioeventfd_assign(proxy, notifier, n, false); 290 } 291 292 return r; 293 }
- 首先看一下EventNotifier的结构,它包含两个文件描述符,一个用于读,一个用于写,实际上,这两个文件描述符值是一样的,在进程的fdt表中对应的file结构当然也一样,只不过rfd是用作qemu用户态的读,另一个wfd用作qemu用户态或者内核态的写。
struct EventNotifier { int rfd; int wfd; };
- 看一下
virtio_bus_set_host_notifier中EventNotifier的初始化过程:
int event_notifier_init(EventNotifier *e, int active) { ...... ret = eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC); /* 1 */ e->rfd = e->wfd = ret; /* 2 */ ...... }
1. 调用eventfd系统调用,创建eventfd,返回一个描述符,初始化内核计数器为0
2. 将返回的描述符作为EventNotifier的初始值- 初始化EventNotifier之后,它的rfd将作为描述符被qemu主事件循环的poll,qemu会将rfd的可读状态关联一个钩子函数,任何想触发这个钩子函数的qemu线程,或者内核模块,都可以通过写wfd来通知qemu主事件循环,从而达到高效的通信目的。

通过virtio_bus_set_host_notifier使kvm和qemu共享notifier
[root@bogon virtio]# grep ioeventfd_assign -rn * virtio-bus.c:181: if (!k->ioeventfd_assign) { virtio-bus.c:214: if (!k->ioeventfd_assign || !k->ioeventfd_enabled(proxy)) { virtio-bus.c:256: return k->ioeventfd_assign && k->ioeventfd_enabled(proxy); virtio-bus.c:272: if (!k->ioeventfd_assign) { virtio-bus.c:283: r = k->ioeventfd_assign(proxy, notifier, n, true); virtio-bus.c:289: k->ioeventfd_assign(proxy, notifier, n, false); virtio-mmio.c:79:static int virtio_mmio_ioeventfd_assign(DeviceState *d, virtio-mmio.c:514: k->ioeventfd_assign = virtio_mmio_ioeventfd_assign; virtio-pci.c:223:static int virtio_pci_ioeventfd_assign(DeviceState *d, EventNotifier *notifier, virtio-pci.c:2055: k->ioeventfd_assign = virtio_pci_ioeventfd_assign; [root@bogon virtio]#
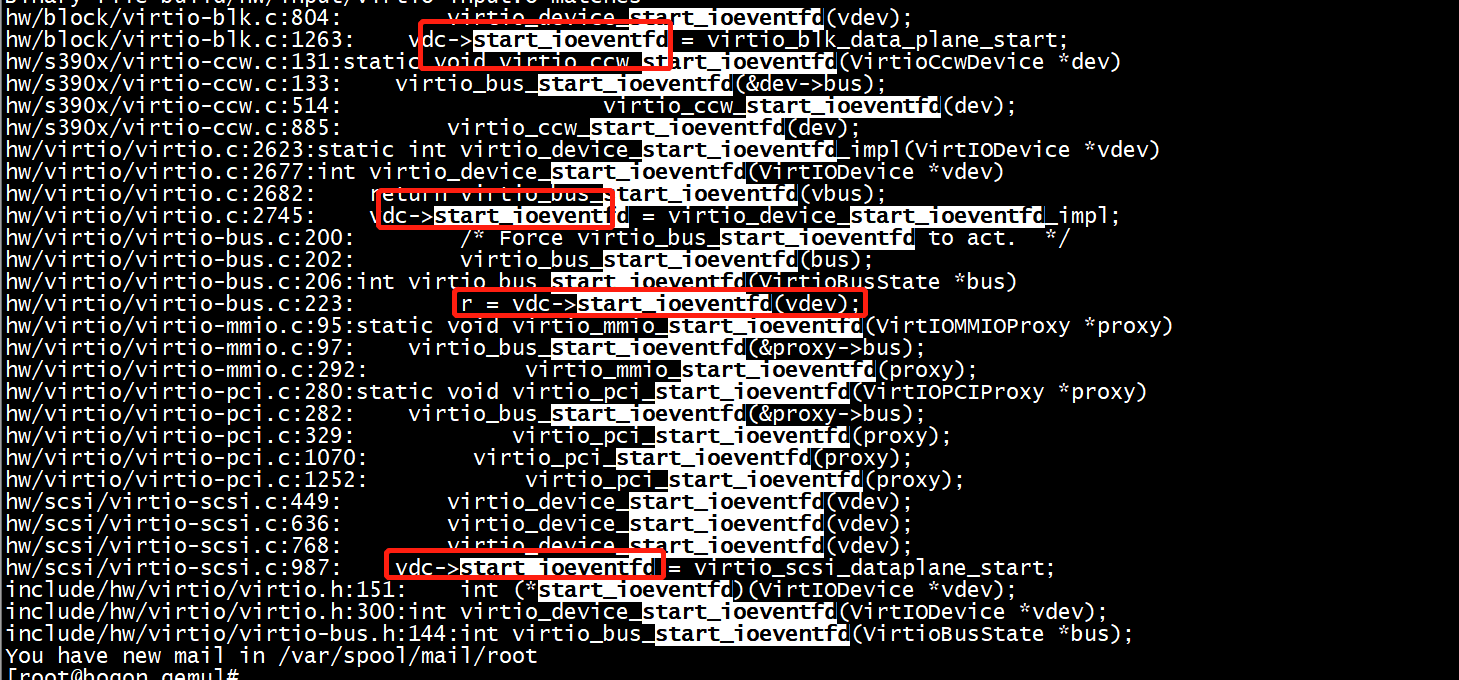
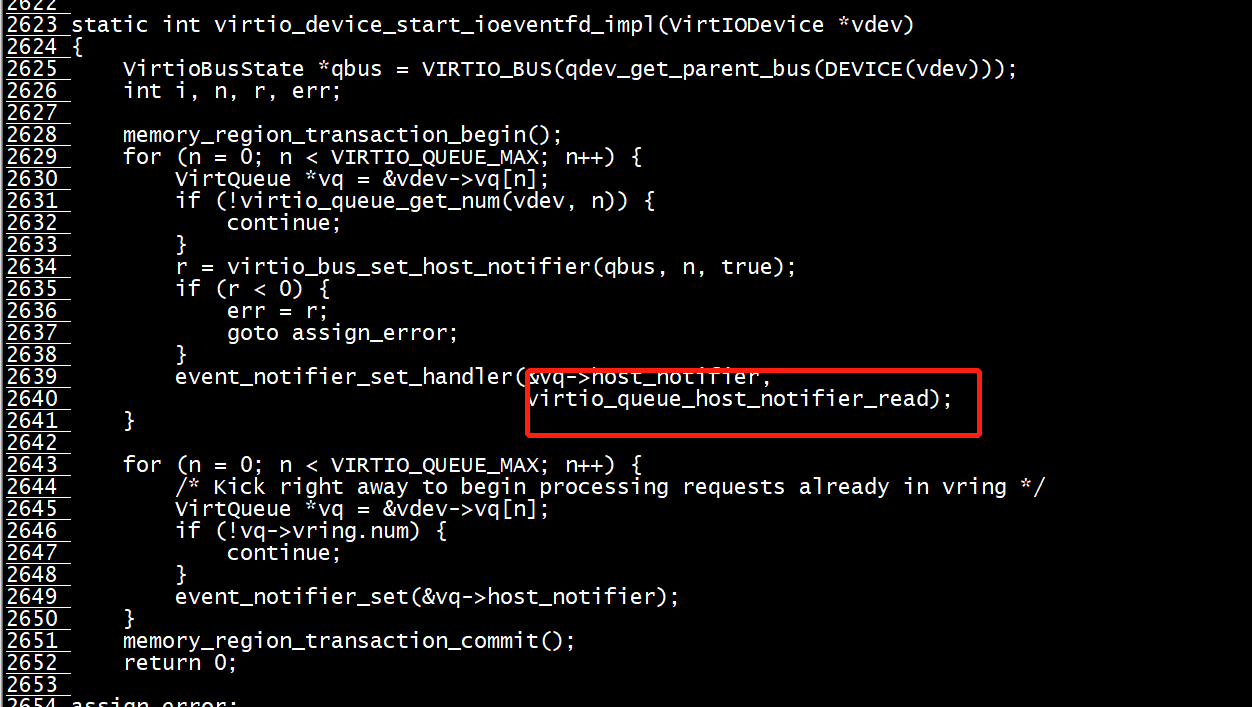
通过virtio_device_start_ioeventfd_impl给qemu设置fd事件读写函数
vdc->start_ioeventfd = virtio_device_start_ioeventfd_impl;
hw/block/virtio-blk.c:804: virtio_device_start_ioeventfd(vdev); hw/block/virtio-blk.c:1263: vdc->start_ioeventfd = virtio_blk_data_plane_start; hw/s390x/virtio-ccw.c:131:static void virtio_ccw_start_ioeventfd(VirtioCcwDevice *dev) hw/s390x/virtio-ccw.c:133: virtio_bus_start_ioeventfd(&dev->bus); hw/s390x/virtio-ccw.c:514: virtio_ccw_start_ioeventfd(dev); hw/s390x/virtio-ccw.c:885: virtio_ccw_start_ioeventfd(dev); hw/virtio/virtio.c:2623:static int virtio_device_start_ioeventfd_impl(VirtIODevice *vdev) hw/virtio/virtio.c:2677:int virtio_device_start_ioeventfd(VirtIODevice *vdev) hw/virtio/virtio.c:2682: return virtio_bus_start_ioeventfd(vbus); hw/virtio/virtio.c:2745: vdc->start_ioeventfd = virtio_device_start_ioeventfd_impl; hw/virtio/virtio-bus.c:200: /* Force virtio_bus_start_ioeventfd to act. */ hw/virtio/virtio-bus.c:202: virtio_bus_start_ioeventfd(bus); hw/virtio/virtio-bus.c:206:int virtio_bus_start_ioeventfd(VirtioBusState *bus) hw/virtio/virtio-bus.c:223: r = vdc->start_ioeventfd(vdev); hw/virtio/virtio-mmio.c:95:static void virtio_mmio_start_ioeventfd(VirtIOMMIOProxy *proxy) hw/virtio/virtio-mmio.c:97: virtio_bus_start_ioeventfd(&proxy->bus); hw/virtio/virtio-mmio.c:292: virtio_mmio_start_ioeventfd(proxy); hw/virtio/virtio-pci.c:280:static void virtio_pci_start_ioeventfd(VirtIOPCIProxy *proxy) hw/virtio/virtio-pci.c:282: virtio_bus_start_ioeventfd(&proxy->bus); hw/virtio/virtio-pci.c:329: virtio_pci_start_ioeventfd(proxy); hw/virtio/virtio-pci.c:1070: virtio_pci_start_ioeventfd(proxy); hw/virtio/virtio-pci.c:1252: virtio_pci_start_ioeventfd(proxy); hw/scsi/virtio-scsi.c:449: virtio_device_start_ioeventfd(vdev); hw/scsi/virtio-scsi.c:636: virtio_device_start_ioeventfd(vdev); hw/scsi/virtio-scsi.c:768: virtio_device_start_ioeventfd(vdev); hw/scsi/virtio-scsi.c:987: vdc->start_ioeventfd = virtio_scsi_dataplane_start; include/hw/virtio/virtio.h:151: int (*start_ioeventfd)(VirtIODevice *vdev); include/hw/virtio/virtio.h:300:int virtio_device_start_ioeventfd(VirtIODevice *vdev); include/hw/virtio/virtio-bus.h:144:int virtio_bus_start_ioeventfd(VirtioBusState *bus);
vhost_user_fs_pci_class_init没有start_ioeventfd
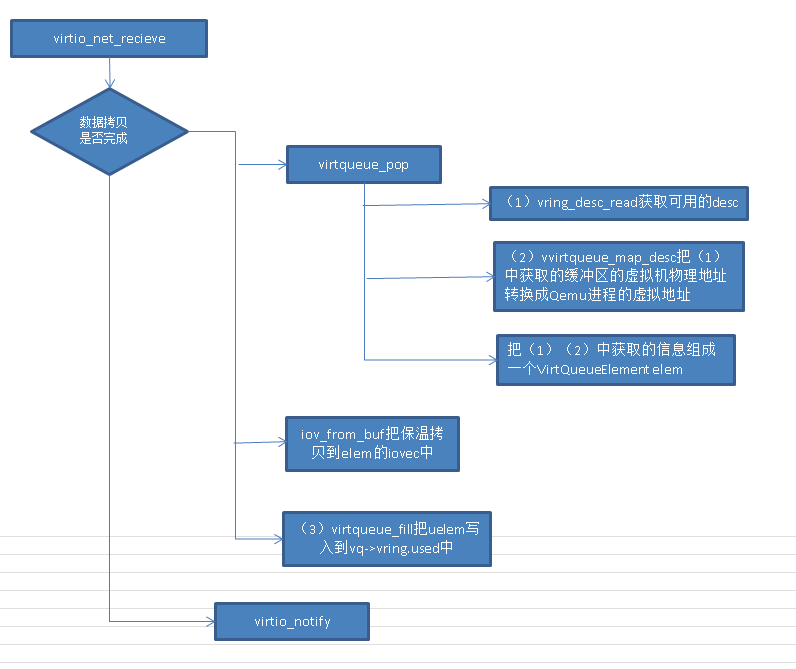
Qemu代码virtio-net相关代码: virtio_queue_host_notifier_read -> virtio_queue_notify_vq -> vq->handle_output -> virtio_net_handle_tx_bh 队列注册的时候,回注册回调函数 -> qemu_bh_schedule -> virtio_net_tx_bh -> virtio_net_flush_tx -> virtqueue_pop -> qemu_sendv_packet_async // 报文放到发送队列上,写tap设备的fd去发包 -> tap_receive_iov -> tap_write_packet // 最后调用 tap_write_packet 把数据包发给tap设备投递出去
*************** 消息传递 Guest->KVM
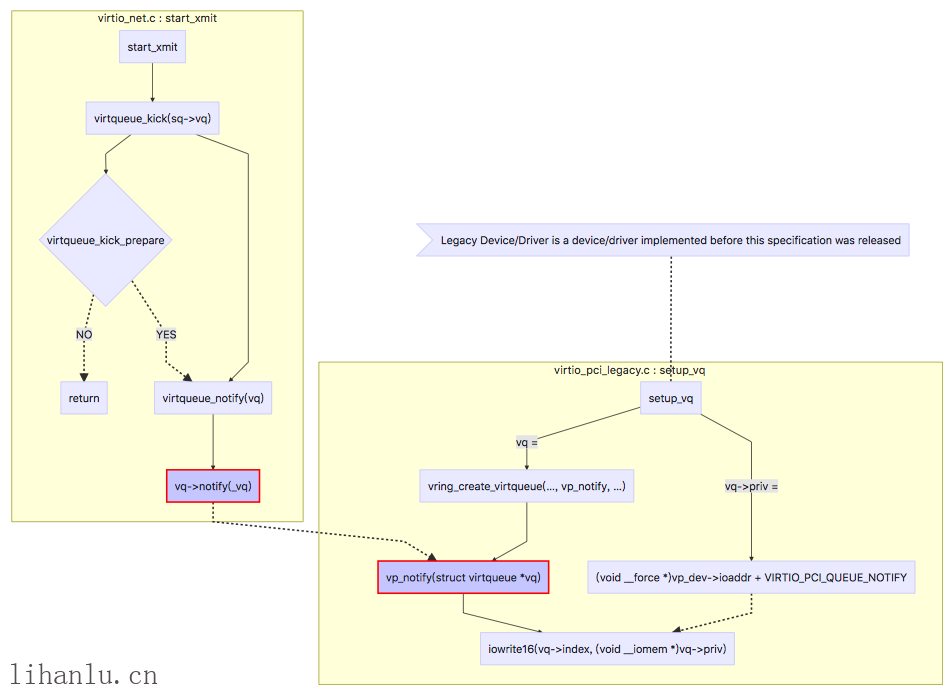
还记得Virtio网络发包过程分析中,driver在start_xmit的最后调用了virtqueue_kick函数来通知device,我们从这里开始分析。代码如下,可以看到函数首先调用了virtqueue_kick_prepare判断当前是否需要kick,如果需要则virtqueue_notify。
bool virtqueue_kick(struct virtqueue *vq)
|
先分析virtqueue_kick_prepare函数,函数获取了old(上次kick后的vring.avail->idx)和new(当前idx),vq->num_added用来表示两者差值。如果vq->event=1则vring_need_event。
1
|
bool virtqueue_kick_prepare(struct virtqueue *_vq)
|
vq->event的值与VIRTIO_RING_F_EVENT_IDX(Virtio PCI Card Specification Version 0.9.5中定义此字段)有关。
Virtual I/O Device (VIRTIO) Version1.0规范中VIRTIO_RING_F_EVENT_IDX变为VIRTIO_F_EVENT_IDX,1.0规范中对此字段介绍的更为详细,具体可以看VirtIO SPEC文档2.4.9节。
下面来看vring_need_event,先看一下传进来的参数event_idx的含义,event_idx实际上为used ring的最后一个元素的值。代码如下,如果(u16)(new_idx - event_idx - 1) < (u16)(new_idx - old)成立说明backend的处理速度够快,那么返回true表示可以kick backend,否则说明backend当前处理的位置event_idx落后于old,此时backend处理速度较慢,返回false等待下次一起kick backend。
对于VirtIO的机制来说,backend一直消耗avail ring,frontend一直消耗used ring,因此backend用used ring的last entry告诉frontend自己当前处理到哪了。
1
|
|
1
|
static inline int vring_need_event(__u16 event_idx, __u16 new_idx, __u16 old)
|
回到virtqueue_kick函数,我们接着来分析virtqueue_notify,virtqueue_notify调用了vq->notify(_vq),notify定义在struct ving_virtqueue中,notify具体是哪个函数是在setup_vq中创建virtqueue时绑定的。
1
|
bool (*notify)(struct virtqueue *vq);
|
1
|
bool virtqueue_notify(struct virtqueue *_vq)
|
下面我们分析setup_vq来看看notify到底是什么,vring_create_virtqueue函数绑定notify为vp_notify,注意一下vq->priv的值下文分析要用到。
1
|
static struct virtqueue *setup_vq(struct virtio_pci_device *vp_dev,
|
可以看到vp_notify函数中写VIRTIO_PCI_QUEUE_NOTIFY(A 16-bit r/w queue notifier)来达到通知的目的.
1
|
bool vp_notify(struct virtqueue *vq)
|
本节总结
上述过程总结如下图,首先virtqueue_kick_prepare根据feature bit以及后端的处理速度来判断时候需要通知,如果需要则调用vp_notify,在其中iowrite VIRTIO_PCI_QUEUE_NOTIFY
KVM->QEMU
iowrite VIRTIO_PCI_QUEUE_NOTIFY后会产生一个VM exit,KVM会判断exit_reason,IO操作对应的执行函数是handle_io(),此部分的代码比较多,就不占用篇幅进行详细分析了,下面列举出函数的调用流程,感兴趣的小伙伴可以结合代码看一看,如图,最后会调用eventfd_signal唤醒QEMU中的poll。
Backend
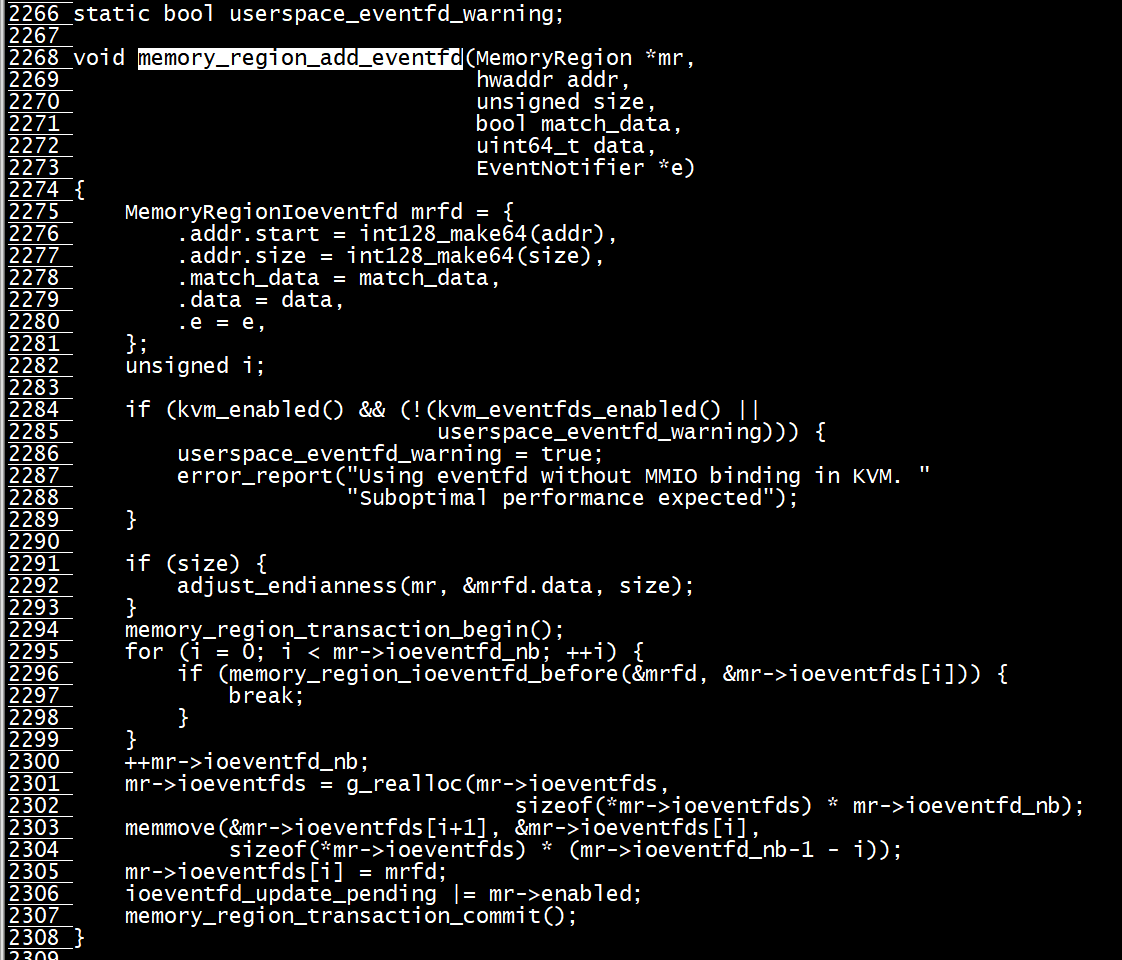
最后看一下Backend的处理,首先在后端是如何把VIRTIO_PCI_QUEUE_NOTIFY和eventfd联系起来的?如下图,memory_region_add_eventfd函数会和kvm来协商使用哪一个eventfd进行kick通信,而event_notifier_set_handler函数把IOHandler函数virtio_queue_host_notifier_read和host_notifier添加到AioHandler中,也就是说当前端kick后,后端会执行virtio_queue_host_notifier_read函数,到这里我们就和上一篇文章的发包过程结合起来了。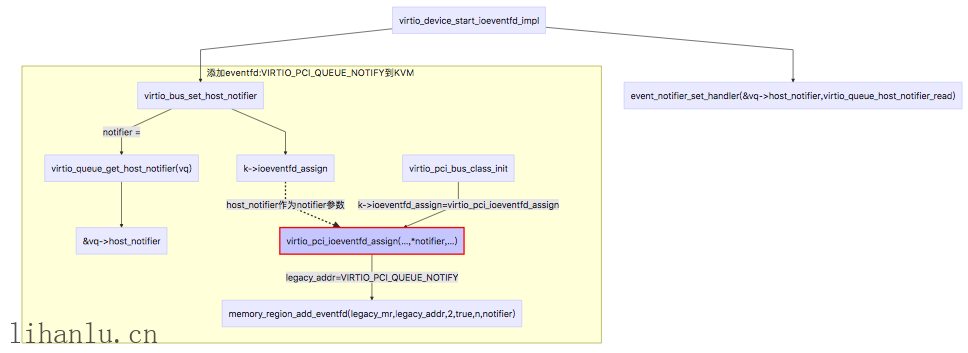
kvm --> guest
1、注册中断fd
前端驱动加载(probe)的过程中,会去初始化virtqueue,这个时候会去申请MSIx中断并注册中断处理函数:
virtnet_probe
--> init_vqs
--> virtnet_find_vqs
--> vi->vdev->config->find_vqs [vp_modern_find_vqs]
--> vp_find_vqs
--> vp_find_vqs_msix // 为每virtqueue申请一个MSIx中断,通常收发各一个队列
--> vp_request_msix_vectors // 主要的MSIx中断申请逻辑都在这个函数里面
--> pci_alloc_irq_vectors_affinity // 申请MSIx中断描述符(__pci_enable_msix_range)
--> request_irq // 注册中断处理函数
// virtio-net网卡至少申请了3个MSIx中断:
// 一个是configuration change中断(配置空间发生变化后,QEMU通知前端)
// 发送队列1个MSIx中断,接收队列1MSIx中断
在QEMU/KVM这一侧,开始模拟MSIx中断,具体流程大致如下:
virtio_pci_config_write
--> virtio_ioport_write
--> virtio_set_status
--> virtio_net_vhost_status
--> vhost_net_start
--> virtio_pci_set_guest_notifiers
--> kvm_virtio_pci_vector_use
|--> kvm_irqchip_add_msi_route //更新中断路由表
|--> kvm_virtio_pci_irqfd_use //使能MSI中断
--> kvm_irqchip_add_irqfd_notifier_gsi
--> kvm_irqchip_assign_irqfd
# 申请MSIx中断的时候,会为MSIx分配一个gsi,并为这个gsi绑定一个irqfd,然后调用ioctl KVM_IRQFD注册到内核中。
static int kvm_irqchip_assign_irqfd(KVMState *s, int fd, int rfd, int virq,
bool assign)
{
struct kvm_irqfd irqfd = {
.fd = fd,
.gsi = virq,
.flags = assign ? 0 : KVM_IRQFD_FLAG_DEASSIGN,
};
if (rfd != -1) {
irqfd.flags |= KVM_IRQFD_FLAG_RESAMPLE;
irqfd.resamplefd = rfd;
}
if (!kvm_irqfds_enabled()) {
return -ENOSYS;
}
return kvm_vm_ioctl(s, KVM_IRQFD, &irqfd);
}
# KVM内核代码virt/kvm/eventfd.c
kvm_vm_ioctl(s, KVM_IRQFD, &irqfd)
--> kvm_irqfd_assign
--> vfs_poll(f.file, &irqfd->pt) // 在内核中poll这个irqfd
从上面的流程可以看出,QEMU/KVM使用irqfd机制来模拟MSIx中断, 即设备申请MSIx中断的时候会为MSIx分配一个gsi(这个时候会刷新irq routing table), 并为这个gsi绑定一个irqfd,最后在内核中去poll这个irqfd。 当QEMU处理完IO之后,就写MSIx对应的irqfd,给前端注入一个MSIx中断,告知前端我已经处理好IO了你可以来取结果了。
2、qemu发送中断事件给kvm fd
virtio_notify_irqfd
例如,virtio-scsi从前端取出IO请求后会取做DMA操作(DMA是异步的,QEMU协程中负责处理)。 当DMA完成后QEMU需要告知前端IO请求已完成(Complete),那么怎么去投递这个MSIx中断呢? 答案是调用virtio_notify_irqfd注入一个MSIx中断。
#0 0x00005604798d569b in virtio_notify_irqfd (vdev=0x56047d12d670, vq=0x7fab10006110) at hw/virtio/virtio.c:1684 #1 0x00005604798adea4 in virtio_scsi_complete_req (req=0x56047d09fa70) at hw/scsi/virtio-scsi.c:76 #2 0x00005604798aecfb in virtio_scsi_complete_cmd_req (req=0x56047d09fa70) at hw/scsi/virtio-scsi.c:468 #3 0x00005604798aee9d in virtio_scsi_command_complete (r=0x56047ccb0be0, status=0, resid=0) at hw/scsi/virtio-scsi.c:495 #4 0x0000560479b397cf in scsi_req_complete (req=0x56047ccb0be0, status=0) at hw/scsi/scsi-bus.c:1404 #5 0x0000560479b2b503 in scsi_dma_complete_noio (r=0x56047ccb0be0, ret=0) at hw/scsi/scsi-disk.c:279 #6 0x0000560479b2b610 in scsi_dma_complete (opaque=0x56047ccb0be0, ret=0) at hw/scsi/scsi-disk.c:300 #7 0x00005604799b89e3 in dma_complete (dbs=0x56047c6e9ab0, ret=0) at dma-helpers.c:118 #8 0x00005604799b8a90 in dma_blk_cb (opaque=0x56047c6e9ab0, ret=0) at dma-helpers.c:136 #9 0x0000560479cf5220 in blk_aio_complete (acb=0x56047cd77d40) at block/block-backend.c:1327 #10 0x0000560479cf5470 in blk_aio_read_entry (opaque=0x56047cd77d40) at block/block-backend.c:1387 #11 0x0000560479df49c4 in coroutine_trampoline (i0=2095821104, i1=22020) at util/coroutine-ucontext.c:115 #12 0x00007fab214d82c0 in __start_context () at /usr/lib64/libc.so.6
在virtio_notify_irqfd函数中,会去写irqfd,给内核发送一个信号。
1654 void virtio_notify_irqfd(VirtIODevice *vdev, VirtQueue *vq) 1655 { 1656 bool should_notify; 1657 rcu_read_lock(); 1658 should_notify = virtio_should_notify(vdev, vq); 1659 rcu_read_unlock(); 1660 1661 if (!should_notify) { 1662 return; 1663 } 1664 1665 trace_virtio_notify_irqfd(vdev, vq); 1666 1667 /* 1668 * virtio spec 1.0 says ISR bit 0 should be ignored with MSI, but 1669 * windows drivers included in virtio-win 1.8.0 (circa 2015) are 1670 * incorrectly polling this bit during crashdump and hibernation 1671 * in MSI mode, causing a hang if this bit is never updated. 1672 * Recent releases of Windows do not really shut down, but rather 1673 * log out and hibernate to make the next startup faster. Hence, 1674 * this manifested as a more serious hang during shutdown with 1675 * 1676 * Next driver release from 2016 fixed this problem, so working around it 1677 * is not a must, but it's easy to do so let's do it here. 1678 * 1679 * Note: it's safe to update ISR from any thread as it was switched 1680 * to an atomic operation. 1681 */ 1682 virtio_set_isr(vq->vdev, 0x1); 1683 event_notifier_set(&vq->guest_notifier); 1684 }
QEMU写了这个irqfd后,KVM内核模块中的irqfd poll就收到一个POLL_IN事件,然后将MSIx中断自动投递给对应的LAPIC。 大致流程是:POLL_IN -> kvm_arch_set_irq_inatomic -> kvm_set_msi_irq, kvm_irq_delivery_to_apic_fast
Copy static int irqfd_wakeup(wait_queue_entry_t *wait, unsigned mode, int sync, void *key) { if (flags & EPOLLIN) { idx = srcu_read_lock(&kvm->irq_srcu); do { seq = read_seqcount_begin(&irqfd->irq_entry_sc); irq = irqfd->irq_entry; } while (read_seqcount_retry(&irqfd->irq_entry_sc, seq)); /* An event has been signaled, inject an interrupt */ if (kvm_arch_set_irq_inatomic(&irq, kvm, KVM_USERSPACE_IRQ_SOURCE_ID, 1, false) == -EWOULDBLOCK) schedule_work(&irqfd->inject); srcu_read_unlock(&kvm->irq_srcu, idx); }