#define RING_F_SP_ENQ 0x0001 /**< The default enqueue is "single-producer". */
#define RING_F_SC_DEQ 0x0002 /**< The default dequeue is "single-consumer". */
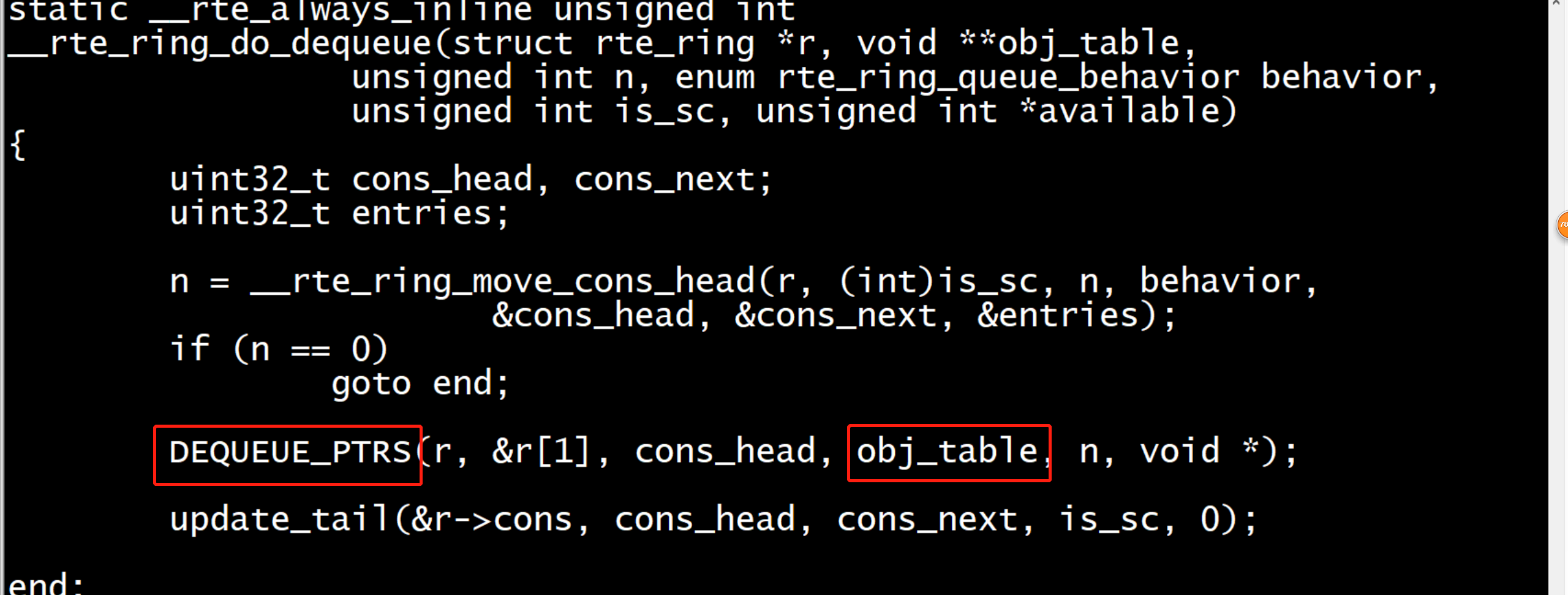
#define DEQUEUE_PTRS(r, ring_start, cons_head, obj_table, n, obj_type) do { unsigned int i; uint32_t idx = cons_head & (r)->mask; const uint32_t size = (r)->size; obj_type *ring = (obj_type *)ring_start; if (likely(idx + n < size)) { for (i = 0; i < (n & (~(unsigned)0x3)); i+=4, idx+=4) { obj_table[i] = ring[idx]; obj_table[i+1] = ring[idx+1]; obj_table[i+2] = ring[idx+2]; obj_table[i+3] = ring[idx+3]; } switch (n & 0x3) { case 3: obj_table[i++] = ring[idx++]; /* fallthrough */ case 2: obj_table[i++] = ring[idx++]; /* fallthrough */ case 1: obj_table[i++] = ring[idx++]; } } else { for (i = 0; idx < size; i++, idx++) obj_table[i] = ring[idx]; for (idx = 0; i < n; i++, idx++) obj_table[i] = ring[idx]; } } while (0)
rte_ring_create
rte_ring_init(r, name, requested_count, flags);
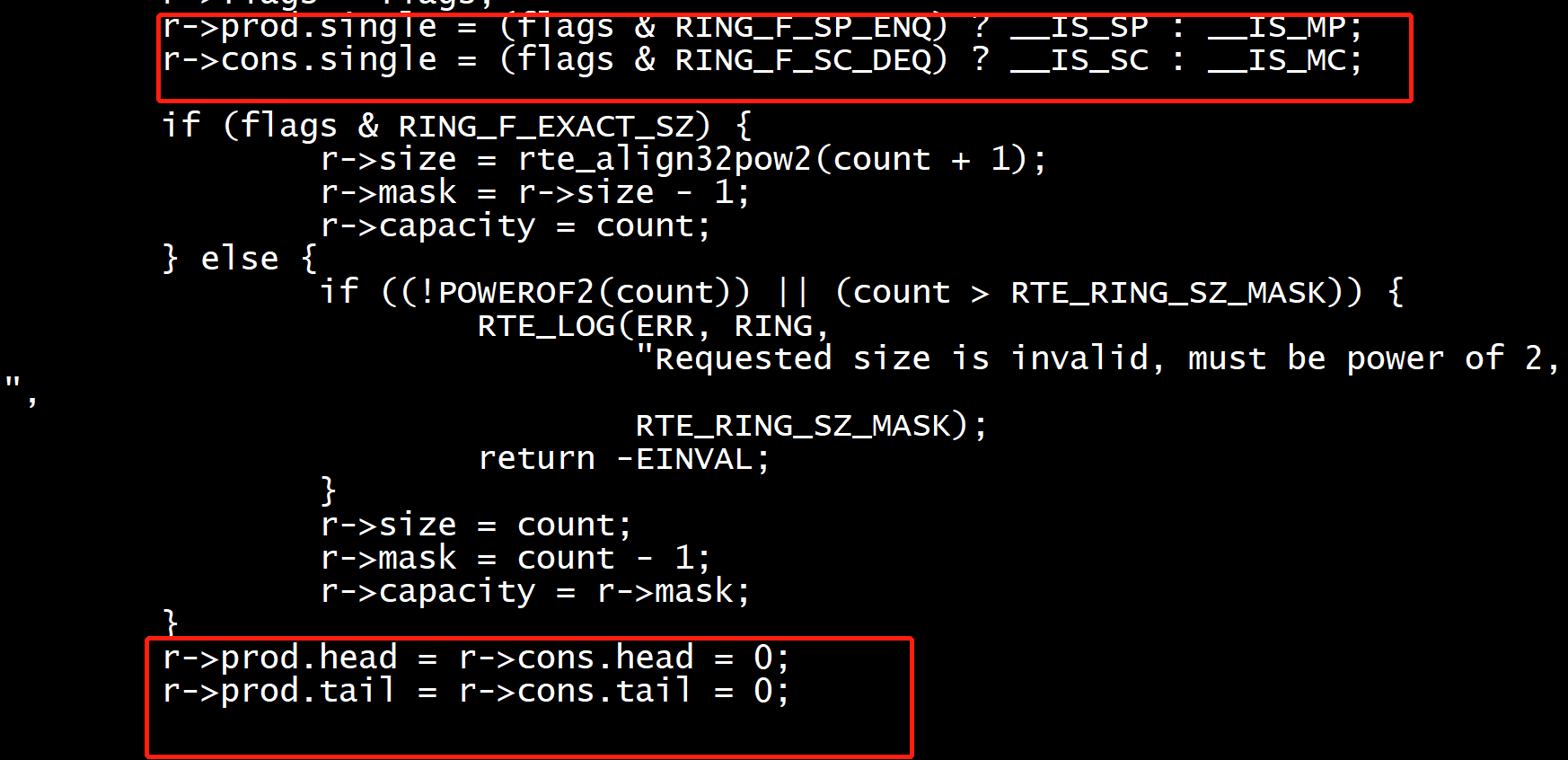
r->prod.single = (flags & RING_F_SP_ENQ) ? __IS_SP : __IS_MP; //默认是mp
r->cons.single = (flags & RING_F_SC_DEQ) ? __IS_SC : __IS_MC;//默认是mc
static __rte_always_inline unsigned rte_ring_sp_enqueue_burst(struct rte_ring *r, void * const *obj_table, unsigned int n, unsigned int *free_space) { return __rte_ring_do_enqueue(r, obj_table, n, RTE_RING_QUEUE_VARIABLE, __IS_SP, free_space); }
static __rte_always_inline unsigned rte_ring_mp_enqueue_burst(struct rte_ring *r, void * const *obj_table, unsigned int n, unsigned int *free_space) { return __rte_ring_do_enqueue(r, obj_table, n, RTE_RING_QUEUE_VARIABLE, __IS_MP, free_space); }
rte_ring_init r->flags = flags; r->prod.single = (flags & RING_F_SP_ENQ) ? __IS_SP : __IS_MP; r->cons.single = (flags & RING_F_SC_DEQ) ? __IS_SC : __IS_MC; rte_ring_enqueue_bulk(struct rte_ring *r, void * const *obj_table, unsigned int n, unsigned int *free_space) { return __rte_ring_do_enqueue(r, obj_table, n, RTE_RING_QUEUE_FIXED, r->prod.single, free_space); } rte_ring_dequeue_burst(struct rte_ring *r, void **obj_table, unsigned int n, unsigned int *available) { return __rte_ring_do_dequeue(r, obj_table, n, RTE_RING_QUEUE_VARIABLE, r->cons.single, available); }
flags(RING_F_SP_EN )实际上影响的并不是队列本身的性质而是调用队列的函数__rte_ring_do_enqueue参数)
static __rte_always_inline unsigned int __rte_ring_move_prod_head(struct rte_ring *r, unsigned int is_sp, unsigned int n, enum rte_ring_queue_behavior behavior, uint32_t *old_head, uint32_t *new_head, uint32_t *free_entries) { const uint32_t capacity = r->capacity; unsigned int max = n; int success; do { /* Reset n to the initial burst count */ n = max; *old_head = r->prod.head; /* add rmb barrier to avoid load/load reorder in weak * memory model. It is noop on x86 */ rte_smp_rmb(); /* * The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * *old_head > cons_tail). So 'free_entries' is always between 0 * and capacity (which is < size). */ *free_entries = (capacity + r->cons.tail - *old_head); /* check that we have enough room in ring */
* and capacity (which is < size). */ *free_entries = (capacity + r->cons.tail - *old_head); /* check that we have enough room in ring */ if (unlikely(n > *free_entries)) n = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : *free_entries; if (n == 0) return 0; *new_head = *old_head + n; if (is_sp) r->prod.head = *new_head, success = 1; else success = rte_atomic32_cmpset(&r->prod.head, *old_head, *new_head); } while (unlikely(success == 0)); return n; }
static __rte_always_inline unsigned int __rte_ring_move_cons_head(struct rte_ring *r, unsigned int is_sc, unsigned int n, enum rte_ring_queue_behavior behavior, uint32_t *old_head, uint32_t *new_head, uint32_t *entries) { unsigned int max = n; int success; /* move cons.head atomically */ do { /* Restore n as it may change every loop */ n = max; *old_head = r->cons.head; /* add rmb barrier to avoid load/load reorder in weak * memory model. It is noop on x86 */ rte_smp_rmb(); /* The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * cons_head > prod_tail). So 'entries' is always between 0 * and size(ring)-1. */ *entries = (r->prod.tail - *old_head); /* Set the actual entries for dequeue */ if (n > *entries) n = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : *entries; if (unlikely(n == 0)) return 0; *new_head = *old_head + n; if (is_sc) { r->cons.head = *new_head; rte_smp_rmb(); success = 1; } else { success = rte_atomic32_cmpset(&r->cons.head, *old_head, *new_head); } } while (unlikely(success == 0)); return n; }