sklearn
Key_Word
数据获取: sklearn, datasets, DataFrame, load_*
数据标准化: preprocessing, MinMaxScaler, scaler, fit, transform, data, target
划分测试集: model_selection, train_test_split, test_size
训练模型: fit ,predict, kernel="linear", probability=True
模型评估: score, predict_proba
使用metrics模块评估: classification_report
使用交叉验证方法评估: cross_val_score
模型的优化: GridSearchCV, C, kernel, gamma, param_grid, svc, cv
模型持久化: pikle, joblib, dump, load
sklearn数据获取
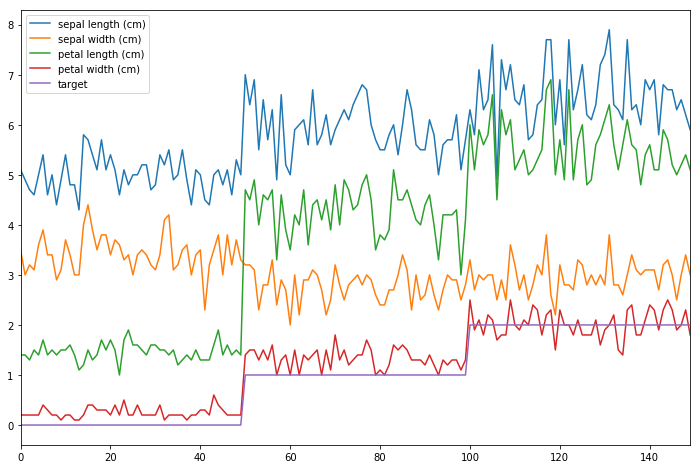
# In[1]: import sklearn # In[2]: sklearn.__version__ # In[6]: import numpy as np import pandas as pd import matplotlib.pyplot as plt get_ipython().run_line_magic('matplotlib', 'inline') #在jupyter中可视化的展示图形 from sklearn import datasets #从sklearn导入数据集 iris = datasets.load_iris() # In[10]: iris iris.data iris['target'] # In[17]: # 利用dataframe做简单的可视化分析 df = pd.DataFrame(iris.data, columns = iris.feature_names) # 是一个表格 df['target'] = iris.target # 表头字段就是key df.plot(figsize = (12, 8))
数据的预处理
数据的标准化: 将每一个数值调整到某一个数量级下
from sklearn import preprocessing # sklearn的数据标准化都在preprocessing下
数据的归一化
数据的二值化
非线性转换
数据特征编码
处理缺失值
数据标准化
Key_Word
preprocessing, MinMaxScaler, scaler, fit, transform, data, target
from sklearn import preprocessing scaler = preprocessing.MinMaxScaler() # scaler: 定标器 # MinMaxScaler将样本特征值线性缩放到0,1之间 scaler.fit(iris.data) # 先fit data = scaler.transform(iris.data) # 再transform 也可以二合一写成fit_transform target = iris.target
模型选择
带标签的属于分类问题, 样本数量为150小于100K, 选择Linear SVC模型进行分类
模型训练
Key_Word
划分测试集: model_selection, train_test_split, test_size
训练模型: fit ,predict, kernel="linear", probability=True
模型评估: score, predict_proba
划分测试集与训练集
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(data, target, test_size = 1/3) # train_test_split(数据集, 目标集, 将多少数据划分成测试集) len(X_train), len(X_test)
导入并训练模型
from sklearn import svm # 导入支持向量机 clf = svm.SVC(kernel = "linear", C = 1, probability = True) # 创建一个线性支持向量机的模型 clf.fit(X_train, y_train) # 导入训练集与训练集的标签 clf.predict(X_test) - y_test # 检验预测结果
查看模型参数
clf.C # 查看模型 的某一个参数,用点语法 clf.get_params() # 参看模型的所有参数
查看预测结果
clf.predict_proba(X_test) # 测试集落在3个label上的概率 clf.score(X_test, y_test) # 查看模型得分
模型的评估
Key_Word
使用metrics模块评估: classification_report
使用交叉验证方法评估: cross_val_score
1.在sklearn.metrics模块针对不同问题类型提供了各种评估指标并且可以创建用户自定义的评估指标
from sklearn.metrics import classification_report print(classification_report(target, clf.predict(data), target_names = iris.target_names))
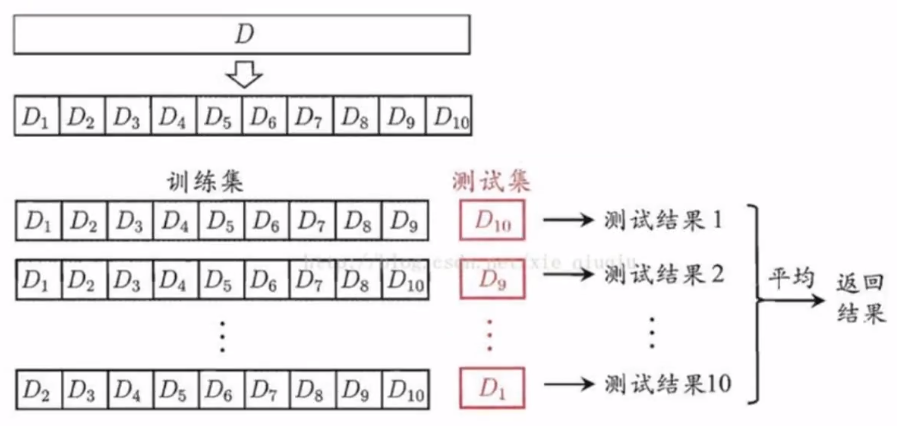
2.可以采用交叉验证方法评估模型的泛化能力
from sklearn.model_selection import cross_val_score scores = cross_val_score(clf, data, target, cv=5) # 采用5折交叉验证 print(scores) # 平均得分和95%的置信区间 print("Accuracy: %0.2f(+/-%0.2f)"%(scores.mean(), scores.std()*2)) # 95%的置信区间在平均值两倍标准差之内
K折交叉验证(K=10)示意图
模型的优化
网格搜索法: 在指定的超参数空间中对每一种可能的情况进行交叉验证评分并选出最好的超参数
就是暴力枚举超参数空间中所有可能出现的超参数,
然后生成所有的模型,
之后使用交叉验证去评分每一种模型
选出最好的超参数组合
随机搜索法
模型特定交叉验证
信息准则优化
Key_Word
模型的优化: GridSearchCV, C, kernel, gamma, param_grid, svc, cv
from sklearn import svm from sklearn.model_selection import GridSearchCV # 估计器 svc = svm.SVC() # 超参数空间 param_grid = [{'C': [0.1, 1, 10, 100, 1000], 'kernel':['linear',]}, {'C': [0.1, 1, 10, 100, 1000], 'gamma':[0.001, 0.01], "kernel":['rbf',]}, ] # 打分函数 scoring = 'accuracy' # 指定采样方法 clf = GridSearchCV(svc, param_grid = param_grid, scoring = scoring, cv = 10) clf.fit(data, target) # 得到的clf是一个优化了的分类器 clf.predict(data) # 用优化了的分类器进行分类 print(clf.get_params()) # 查看全部参数 print(clf.best_params_) # 查看最优参数 clf.best_score_
模型持久化
Key_Word
模型持久化: pikle, joblib, dump, load
使用pickle模块保存模型
对于sklearn, 使用joblib会更有效
import pickle s = pickle.dumps(clf) # 保存模型成字符串 clf2 = pickle.loads(s) # 从字符串加载模型
from sklearn.externals import joblib joblib.dump(clf, 'filename.pkl') # 保存模型到文件 clf3 = joblib.load('filename.pkl') #加载模型