sklearn
机器学习的工具箱
sklearn功能模块
分类: 识别某个对象属于哪个类别------垃圾邮件监测, 图像识别
回归: 预测与对象相关联的连续值属性------>股价
聚类: 将相似对象自动分组------>客户细分, 分组实验结果
降维: 减少要考虑的随机变量的数量------>可视化
模型选择: 比较, 验证, 选择参数和模型------>通过参数调整提高精度
预处理: 特征提取和归一化------>把输入数据转换为机器学习算法可用的数据
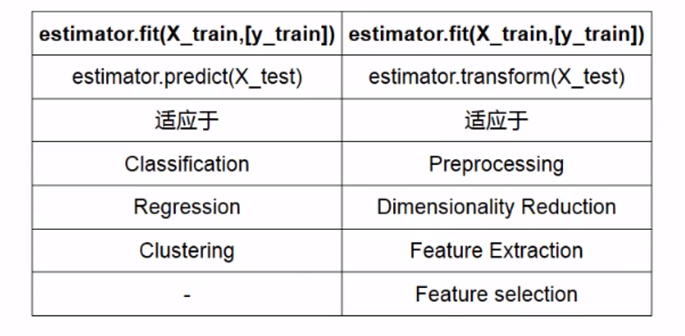
sklearn统一API
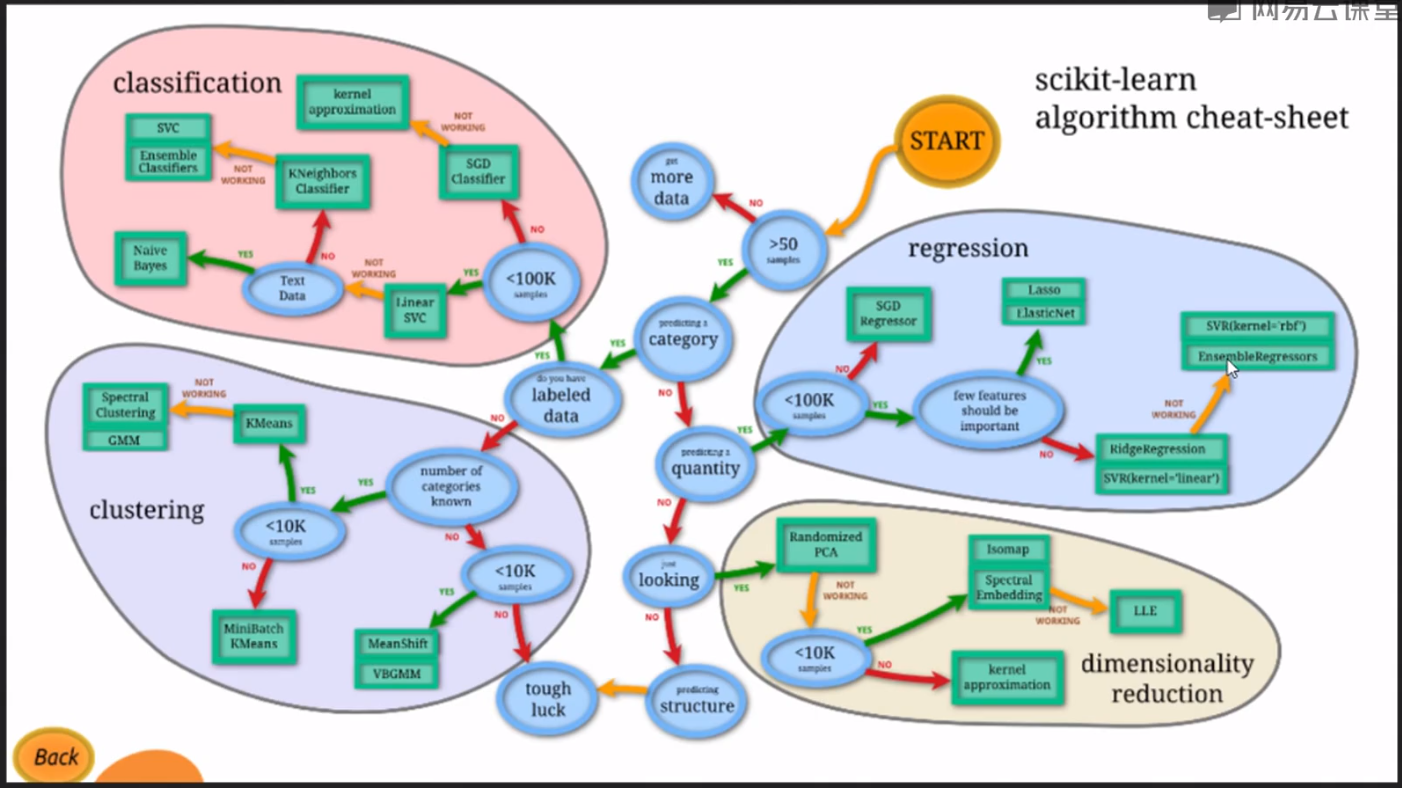
sklearn使用地图
classification: 分类 regression: 回归 clustering: 聚类 demension reduction: 降维
分类:
SVC: 支持向量机--->通过升维划分出数据集的高维线性边界(高维线性边界降维得出低维的各种曲线)
KNeighbors: K近邻
LR: 逻辑回归--->将数据集回归到标签, 而不是回归成一条直线
Naive Bayes: 朴素贝叶斯
回归:
Lasso
ElasticNet
SVR
聚类:
KMeans
降维:
PCA
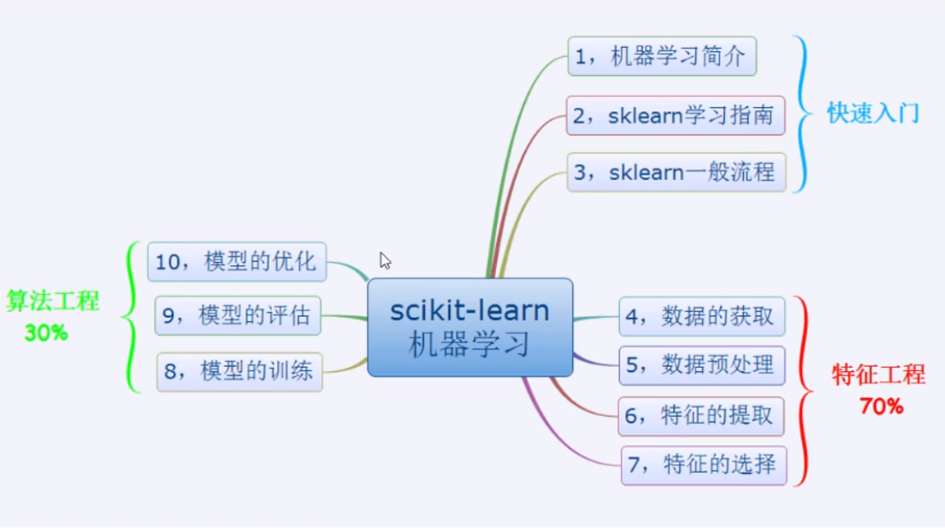
sklearn学习路线
1. 快速入门
sklearn一般流程: 数据获取, 数据预处理, 模型训练, 模型评估, 模型优化
2. 特征工程
数据的获取, 数据预处理, 特征的提取, 特征的选择
3. 算法工程
模型的训练, 模型的评估, 模型的优化