报名了飞谷六期的爬虫项目,但是自己相关的基础还是较弱,每天都有种无所事事的感觉。决定还是记录一下每天学习到的知识,自己看看也知道学习了些什么。
1.XShell连接阿里云,Xftp传输文件
2.把例子的文件拷贝出来后,link文件夹中的代码如图:
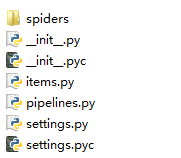
开始看到这些文件,我想说什么鬼。然后看了一下 Scrapy入门,得知,这些文件是在新建scrapy项目后自动生成的。如果建立一个名叫tutorial的新项目,可以输入命令(我都是用的飞谷云提供的环境,linux的)
scrapy startproject tutorial
然后就会生成一个tutorial目录
tutorial/ scrapy.cfg tutorial/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
对比了一下新生成的这些文件和给出的例子文件,发现大多数的文件没有改动,只有
①items.py有少量变化
②spiders文件夹下需要自己写一个py文件,给出具体的爬虫代码。
这两个文件中具体要添加什么代码呢?我也不会,就先照着Scrapy入门的例子抄一下吧
items.py
# Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/topics/items.html from scrapy.item import Item, Field class TutorialItem(Item): # define the fields for your item here like: # name = Field() pass class DmozItem(Item): title = Field() link = Field() desc = Field()
spiders文件夹下新建dmoz_spider.py
import scrapy class DmozSpider(scrapy.spiders.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = ["http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"] def parse(self, response): filename = response.url.split("/")[-2] with open(filename, 'wb') as f: f.write(response.body)
split("/")[-2]:是指以"/"为分隔符分割后,选取倒数第二的部分。 python/Books/分解后的结果是python Books 空,倒数第二个就是Books
在有scrapy.cfg的文件夹下运行
scrapy crawl dmoz
结果,尼玛居然报错了/(ㄒoㄒ)/~~

去问万能的度娘,度娘说是因为我的scrapy的版本太低了,应该看这份教程orz
对比了一下,发现items.py里面没变化,就是dmoz_spider.py导入的模块名字变了
from scrapy.spider import BaseSpider class DmozSpider(BaseSpider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = ["http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"] def parse(self, response): filename = response.url.split("/")[-2] with open(filename, 'wb') as f: f.write(response.body)
运行,注意后面的dmoz就是dmoz_spider.py文件中name中的字符,如果写了其他的名字要改的。
scrapy crawl dmoz
成功了~好开心~可以得到相应页面源码的文件了~
刚才发生的事情:
Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
Shell中使用Selector选择器
可以通过如下命令启动shell:
scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"
结果是这个样子的
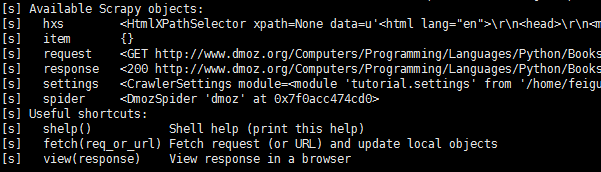
得到信息头,可以通过输入:
response.headers

得到信息内容,可以通过输入:
response.body
有两个选择器可以用于选择内容中的有用信息,分别是hxs和xxs(注意,这个是老版本的,新版本的语句变了)。例:
hxs.select('/html/head/title')
括号里面写的其实是一个XPath语句
最有用的XPath语句如下图,其他的遇到再查好了。
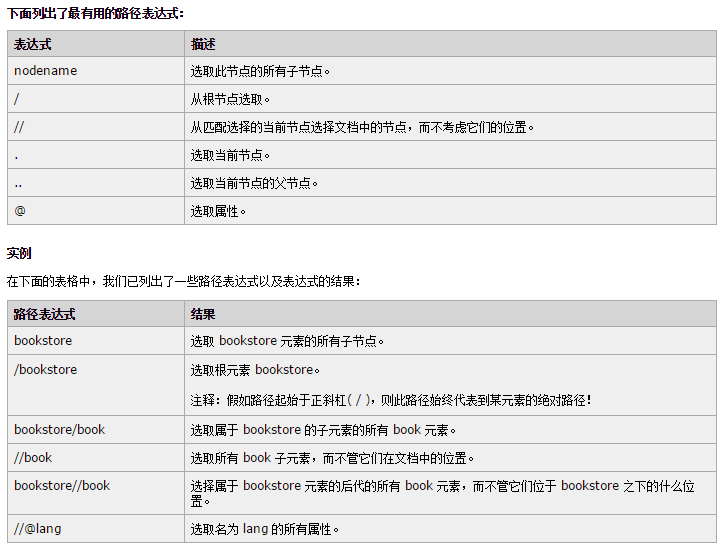
这样,通过选择器,我们就可以提取有用信息了。