跑个任务,跑着跑着就不运行了,查看GC如下,居然Old区无法回收,fullGC的次数大量增加
后来在启动任务中加了打印GC的日志,参数如下
-XX:+HeapDumpOnOutOfMemoryError -verbose:gc -XX:+PrintGCDetails
收集到的信息如下,GC无法回收空间
[Full GC [PSYoungGen: 1244672K->1243884K(2013184K)] [ParOldGen: 5592180K->5592180K(5592576K)] 6836852K->6836065K(7605760K) [PSPermGen: 65803K->65803K(66048K)], 2.5267280 secs] [Times: user=24.47 sys=0.00, real=2.53 secs]
[Full GC [PSYoungGen: 1244672K->1243975K(2013184K)] [ParOldGen: 5592180K->5592180K(5592576K)] 6836852K->6836156K(7605760K) [PSPermGen: 65803K->65803K(66048K)], 6.4962320 secs] [Times: user=63.12 sys=0.00, real=6.50 secs]
[Full GC [PSYoungGen: 1244672K->1244070K(2013184K)] [ParOldGen: 5592180K->5592164K(5592576K)] 6836852K->6836235K(7605760K) [PSPermGen: 65803K->65803K(66048K)], 6.5300410 secs] [Times: user=63.02 sys=0.00, real=6.53 secs]
[Full GC [PSYoungGen: 1244672K->1244151K(2013184K)] [ParOldGen: 5592164K->5592164K(5592576K)] 6836836K->6836315K(7605760K) [PSPermGen: 65803K->65803K(66048K)], 6.9306890 secs] [Times: user=61.70 sys=0.00, real=6.93 secs]
[Full GC [PSYoungGen: 1244672K->1244232K(2013184K)] [ParOldGen: 5592164K->5592164K(5592576K)] 6836836K->6836396K(7605760K) [PSPermGen: 65803K->65803K(66048K)], 2.4629620 secs] [Times: user=23.59 sys=0.00, real=2.47 secs]
[Full GC [PSYoungGen: 1244672K->1244247K(2013184K)] [ParOldGen: 5592164K->5592164K(5592576K)] 6836836K->6836411K(7605760K) [PSPermGen: 65803K->65803K(66048K)], 2.4668490 secs] [Times: user=23.49 sys=0.00, real=2.47 secs]
[Full GC [PSYoungGen: 1244672K->1244276K(2013184K)] [ParOldGen: 5592164K->5592164K(5592576K)] 6836836K->6836440K(7605760K) [PSPermGen: 65803K->65803K(66048K)], 2.7571690 secs] [Times: user=26.43 sys=0.00, real=2.76 secs]
不得已,只能jmap 进行dump了
jmap -dump:live,format=b,file=heap.bin 83484
dump下来后,使用MAT打开,dump的文件比较大,需要调整一下MAT的最大内存值,在MemoryAnalyzer.ini中:
-vmargs
-Xmx6g
使用MAT打开heap.bin文件,加载需要一段时间
点击Leak Suspects,显示如下:
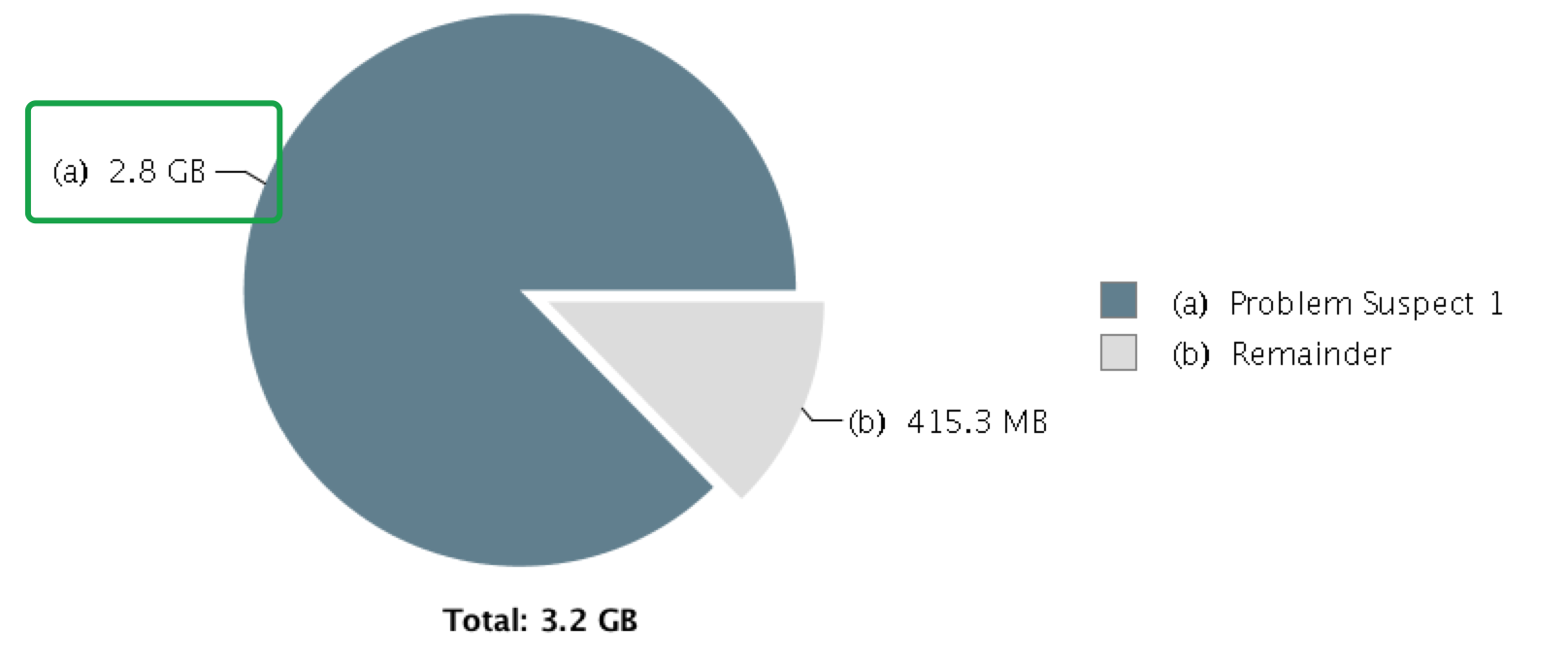
这里提示某个类中的本地变量占了87%的内存
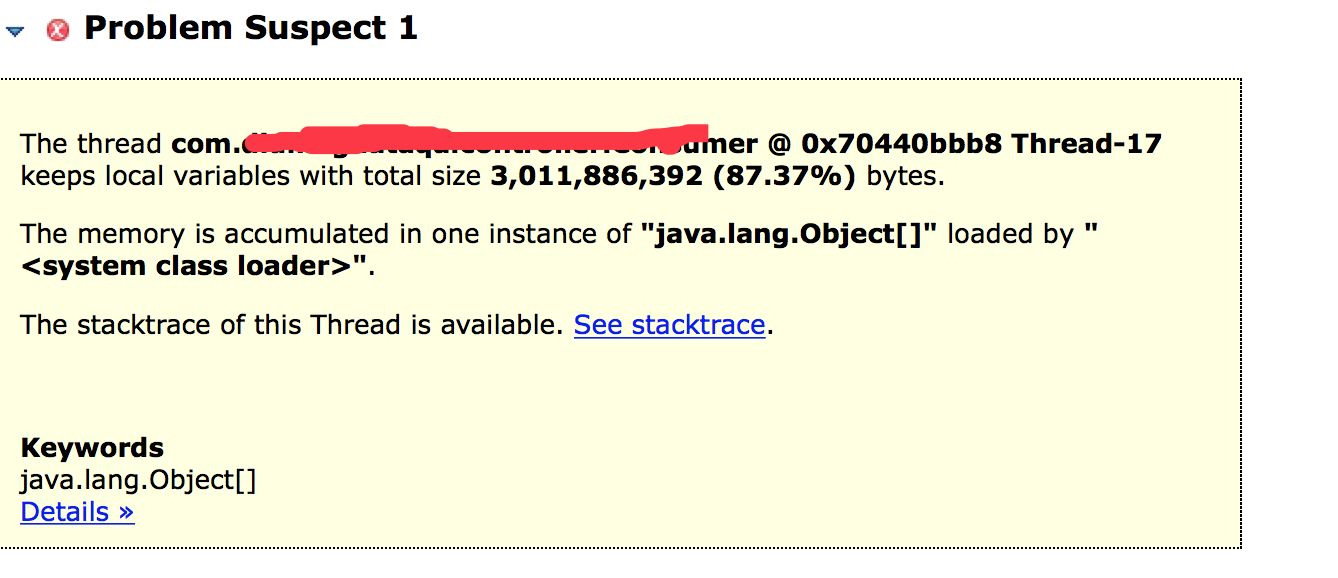
追踪stacktrace,查看到如下,定位到具体代码行,原来是hive使用listPartitions方法,返回的
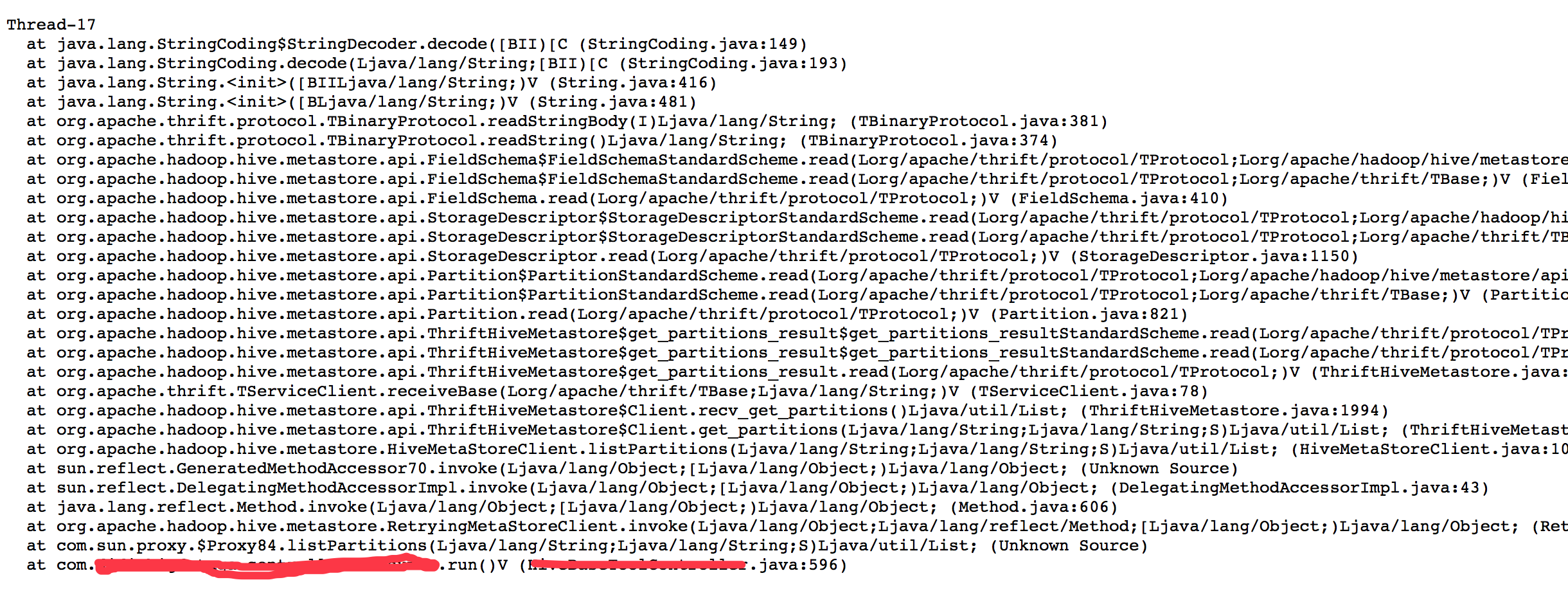
partitions = client.listPartitions(db, tbl, (short) -1);
再查看dominator_tree,可以看到具体哪些对象占用内存较大:
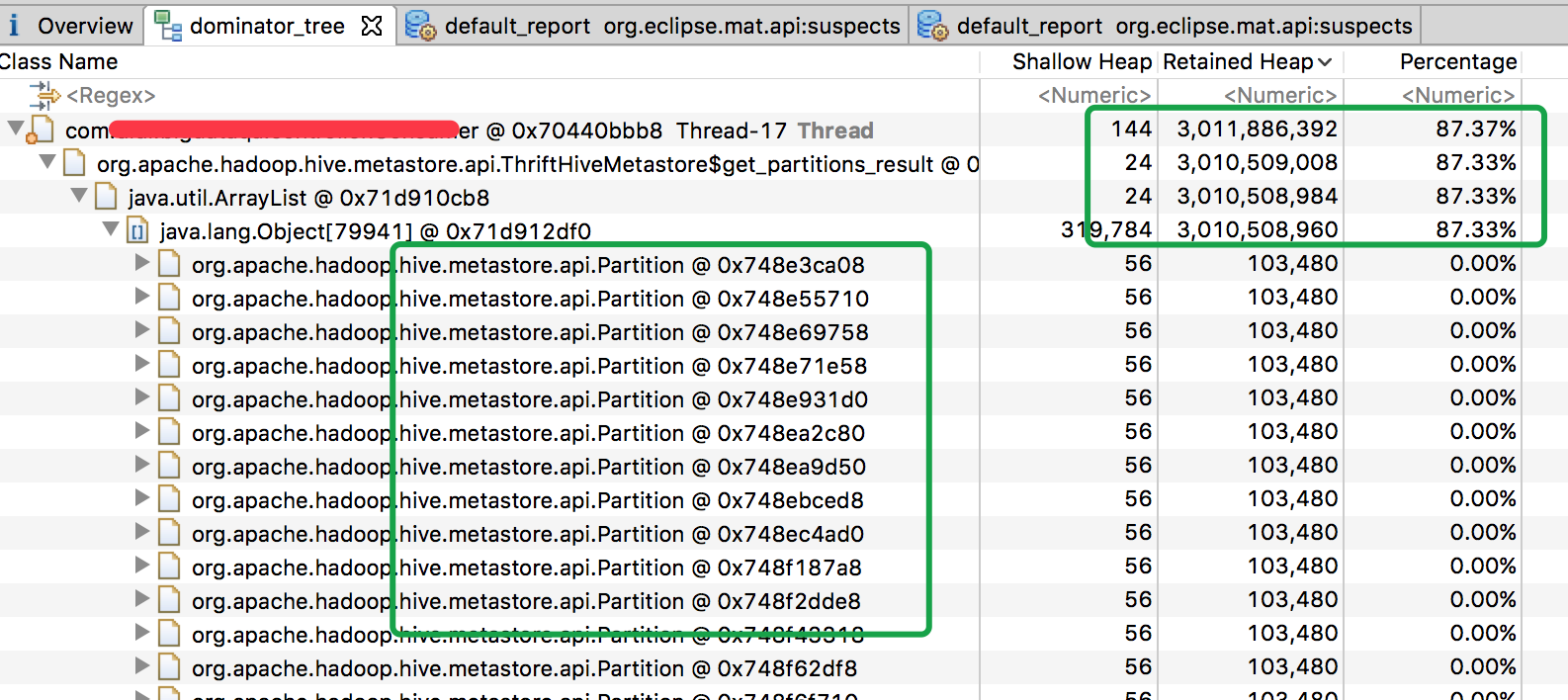
再查看Histogram

这样就能明白了问题出在listPartitions上
但是listPartitions本身没有什么问题,而且只是在一段for循环中遍历,为什么会存在无法回收的情况呢?
再仔细看了listPartitions后面的使用,一个listPartitions返回的partition数多的大多三四万,少的几千,在for循环里面多次调用了hadoop的RPC,fs功能,这样导致这个List对象不会那么快的不被引用,时间会稍微长点:
怀疑是不是对象在新生代停留的时间太短了? 全部到老年代去了? 导致老年代暴增?
通过两个方式来尝试:
第一、修改listPartitions中for循环里面的代码,减少调用RPC的次数,比如对于路径的owner,获取一次就可以,让for循环可以尽早的结束,List不再被引用;
第二、再调整一下运行参数:
-Xms4g -Xmx4g //设置堆内存大小
-XX:MaxPermSize=400m //设置永久代大小
-XX:+UseCMSCompactAtFullCollection //CMS压缩,目前默认为true了
-XX:+HeapDumpOnOutOfMemoryError //出现OOM时进行headDump
-verbose:gc -XX:+PrintGCApplicationStoppedTime //打印GC时应用停顿时间
-Xloggc:gc.log -XX:+PrintGCTimeStamps //打印GC情况、时间
-XX:CMSInitiatingOccupancyFraction=70 //old代70%时进行回收
-XX:+UseCMSInitiatingOccupancyOnly //只是用设定的回收阈值(上面指定的70%),如果不指定,JVM仅在第一次使用设定值,后续则自动调整.
-XX:SurvivorRatio=4 //edin区域survivor0的比例,因为listPartitions获取的对象是比较大的,所以怀疑是survivor区过小,导致listPartitions里面的数据马上就到了old代,导致old代暴增,且对象还在被引用,无法回收,所以会一直停顿在old代GC;
-XX:PrintHeapAtGC //打印GC时堆的使用情况
-XX:+CMSClassUnloadingEnabled //运行对永久代回收
-XX:+PrintGCDetails //打印GC详细
修改后,程序运行没有问题了。