之前总结过HashMap的原理,同时对源码进行了阅读,不过是针对JDK1.7的版本,同样针对1.8的版本也来做一遍记录
1.HashMap1.8针对1.7的修改点有哪些?
JJDK1.8对HashMap底层的实现进行了优化,例如引入红黑树的数据结构和扩容的优化等,其中最重要的一个优化就是桶中的元素不再唯一按照链表组合,也可以使用红黑树进行存储,总之,目标只有一个,那就是在安全和功能性完备的情况下让其速度更快,提升性能。
具体结构大致如下,该图从别处借来
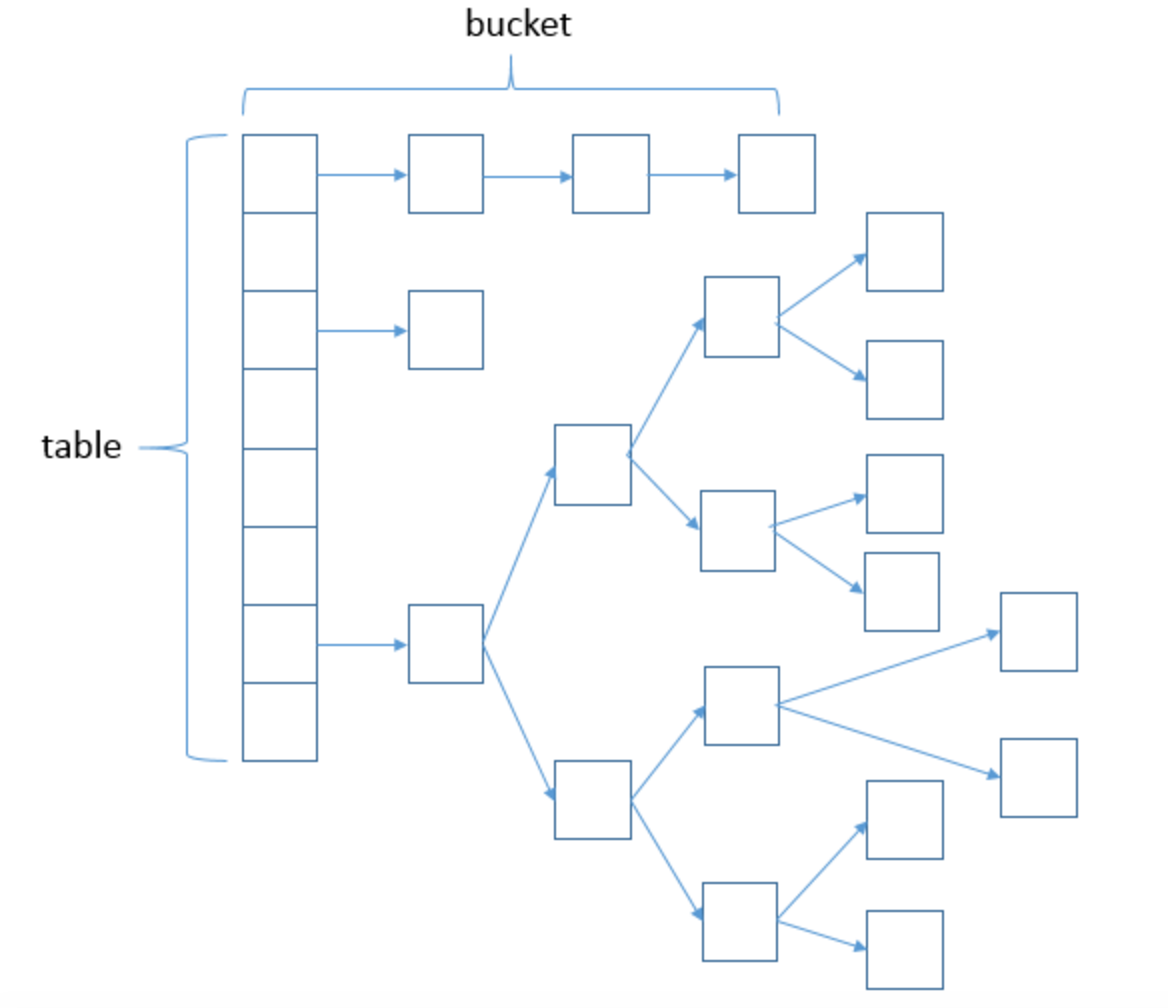
接下来还是从源码的角度的来分析1.8的HashMap
1.数据结构
/** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table; //定义数组 /** * Basic hash bin node, used for most entries. (See below for * TreeNode subclass, and in LinkedHashMap for its Entry subclass.) */ static class Node<K,V> implements Map.Entry<K,V> { //内部类,定义Node final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }
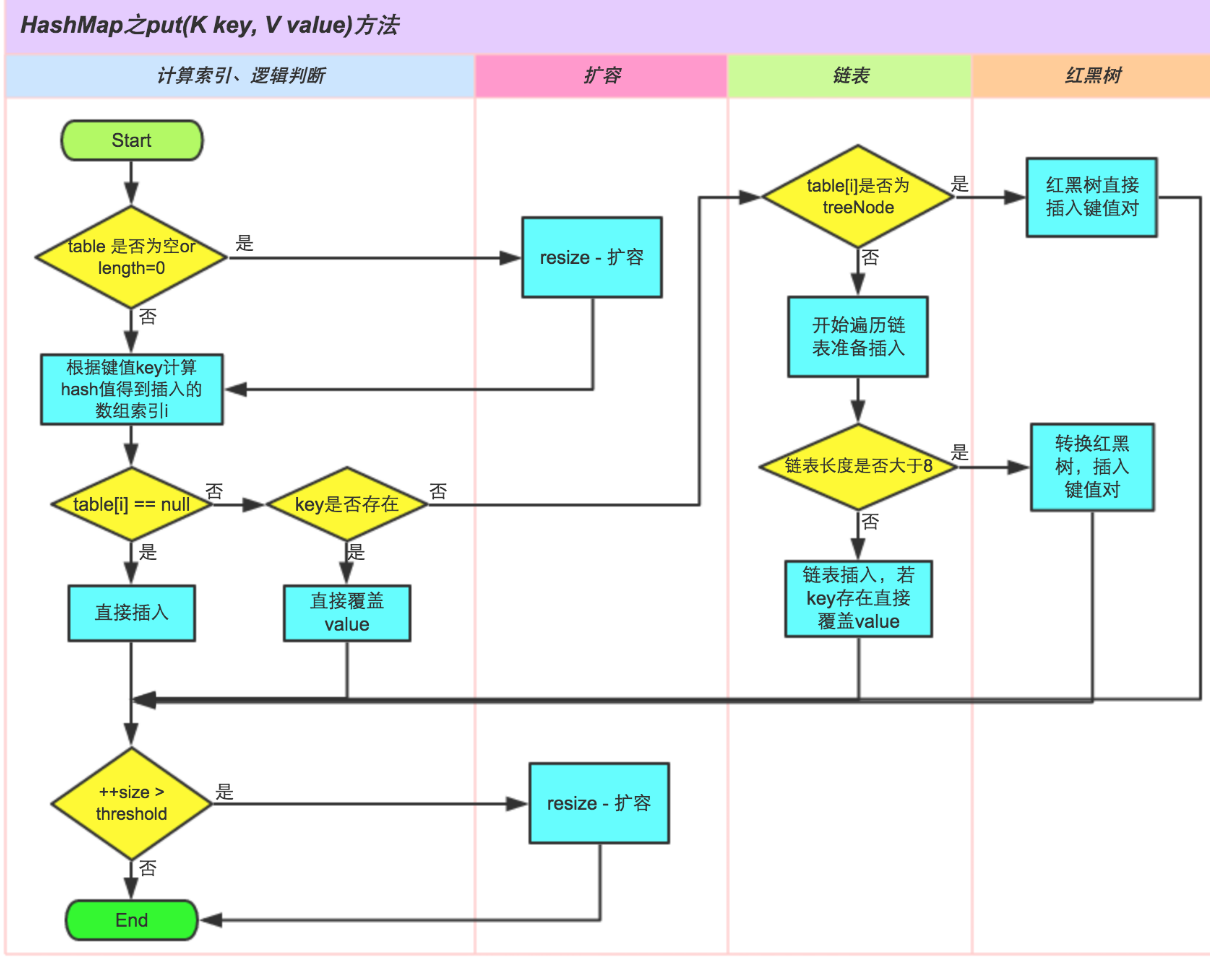
2.put方法
public V put(K key, V value) {
//对key对hash获取Hash值
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) //如果table为空,则进行扩容处理 n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) //计算index,对null进行处理 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) //判断节点是否存在,如果存在直接覆盖 e = p; else if (p instanceof TreeNode) //判断是否为红黑树,如果是则进行红黑树的插入 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //节点为链表 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //判断链表数是否超过8,如果超过,则转换为红黑树 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) //如果key存在则覆盖 break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) //判断是否需要扩容 resize(); afterNodeInsertion(evict); return null; }
再借个流程图说明:
3.get方法
Get方法还是类似,获取hashindex,再判断第一个节点是否为红黑树,如果是红黑树,则通过树的方式获取,否则还是按照链表的方式获取
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } /** * Implements Map.get and related methods * * @param hash hash for key * @param key the key * @return the node, or null if none */ final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) //判断第一个节点是否为红黑树 return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { //否则遍历链表来获取 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
4.扩容
之前讲到1.8对1.7的扩容处理进行了优化,优化在哪个方面?
1.7的扩容,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话),进行扩容的时候需要重新计算hash index
1.8的扩容,使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置;
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图:

既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。