栈帧结构与函数调用约定
栈,是一种先入后出的数据结构,就像我们堆放书籍一样,先放的在最底下,后放置的在顶上,当我们要取的时候就是拿最上面一本,即最后放置的那一本。即FILO(first in last out)。
对大多数的应用程序员来说,栈就是这么一个数据结构的概念,而对于嵌入式工程师来说,栈还代表着另一种举足轻重的角色,今天我们就来聊一聊内存中的栈结构。
什么是栈?
在早期的计算机系统中,事实上是没有栈这个概念的,内存中栈的设计是由于过程式语言的面世。
CPU寄存器是CPU内部的存储设备,而内存是独立于CPU之外的存储设备,存储着数据、程序等等,当CPU需要执行程序时,将内存中的数据读入寄存器,然后执行相应指令,寄存器是内存与CPU之间交互的桥梁,寄存器中缓存着需要执行程序的数据或者指令地址等等。这种执行模式一直持续到过程式语言被创造之前。
后来逐渐有了Fortran、C语言的面世,函数的概念被提出,这导致一个什么结果呢?
当一个函数调用另一个函数时,势必涉及到保存调用函数的状态保存,因为在调用完成之后必须要能够原封不动地还原调用函数的状态,继续往下执行函数,而且往往这个调用过程是递归的,但是这些数据存在哪里呢?
显然,光靠寄存器是不够的,经典的8086才8个16位通用寄存器。在这个时候,人们就想到了是不是可以在内存中开辟出一部分专门用来存储这些函数调用的中间数据,答案当然是可以的,虽然比起寄存器的访问速度,内存访问的效率明显低很多,但是这也是没有办法的办法。
但是问题又来了,这部分内存采取什么样的管理结构呢?
我们来模拟一下调用过程,当A调用B时,在B中又调用了函数C,当函数C返回时,清除C的信息,返回到B的执行状态中,当B执行完之后,清除B的信息,返回到A中。整个过程是这样的:
我们可以看到,执行顺序为:A->B->C,而返回顺序是C->B->A,由于内存是线性空间,很显然这是一个栈的结构,先进后出,所以栈就应运而生。
为了支持函数调用而在内存中开辟出来的一段空间,这个数据空间的规则是先进后出。
那么,既然是为了支持函数调用而产生的,它到底是以一个怎样的方式来支持函数调用的呢?
栈到底在哪里?
既然栈是内存中开辟出来的空间,那么我们是怎么指定它的位置的?
在经典操作系统中,栈总是向下生长的,向下生长意味着由高地址向低地址延伸,当数据压栈时,栈向低地址延伸,当从栈中弹出数据时,栈缩回高地址。
CPU有一个内部寄存器esp专门用来存储栈顶位置,随着栈的伸缩而改变,始终指向栈顶,由这个寄存器我们就可以访问当前栈中的内容。
还有一个寄存器ebp,这个ebp寄存器存储的则是当前执行函数的栈基地址(下面还会详细讲到)。
栈帧结构
从上一部分我们知道了怎么定位栈的地址,esp和ebp两个寄存器定位栈活动记录的方式就叫栈帧结构,现在我们以一个简单的例子来分析一下栈帧结构:
int func(int x,int y)
{
int a=x,b=y;
return a+b;
}
int main()
{
int c = func(3,4);
return c;
}
事实上光是简单地看函数实现是看不出什么东西的,我们必须得从底层来分析,最好的方式就是直接看汇编代码的实现。
在这里我们生成汇编代码:
gcc -g test.c -o test
objdump -S test > asm_file
这样我们就可以直接在asm_file中查看反汇编代码,为什么不直接使用gcc -S test.c直接编译生成汇编代码呢?其实这是因为格式问题,objdump生成的代码更清晰,而且也嵌入了源代码做对应。下面就是部分主要的汇编(注1):
int func(int x,int y)
{
1 4004d6: 55 push %rbp
2 4004d7: 48 89 e5 mov %rsp,%rbp
3 4004da: 89 7d ec mov %edi,-0x14(%rbp)
4 4004dd: 89 75 e8 mov %esi,-0x18(%rbp)
5 int a=x,b=y;
6 4004e0: 8b 45 ec mov -0x14(%rbp),%eax
7 4004e3: 89 45 f8 mov %eax,-0x8(%rbp)
8 4004e6: 8b 45 e8 mov -0x18(%rbp),%eax
9 4004e9: 89 45 fc mov %eax,-0x4(%rbp)
10 return a+b;
11 4004ec: 8b 55 f8 mov -0x8(%rbp),%edx
12 4004ef: 8b 45 fc mov -0x4(%rbp),%eax
13 4004f2: 01 d0 add %edx,%eax
}
14 4004f4: 5d pop %rbp
15 4004f5: c3 retq
int main()
{
16 4004f6: 55 push %rbp
17 4004f7: 48 89 e5 mov %rsp,%rbp
18 4004fa: 48 83 ec 10 sub $0x10,%rsp
19 int c = func(3,4);
20 4004fe: be 04 00 00 00 mov $0x4,%esi
21 400503: bf 03 00 00 00 mov $0x3,%edi
22 400508: e8 c9 ff ff ff callq 4004d6 <func>
23 40050d: 89 45 fc mov %eax,-0x4(%rbp)
24 return c;
25 400510: 8b 45 fc mov -0x4(%rbp),%eax
}
在上述的汇编代码中,第一列是代码地址,第二列是机器指令,这一部分我们不需要关注,而第三四列就是汇编指令。这里反汇编出来的汇编指令是AT&T格式的,与我们常学的intel格式的汇编指令有所区别,这里我们需要知道源操作单元的目标操作单元与intel格式中是相反的。
汇编代码分析
接下来我们从main函数开始逐行分析这些汇编指令,为了方便讲解,我人为地为它们添加了行号。
保存及切换栈帧
我们先看main()最前两行:
16 4004f6: 55 push %rbp
17 4004f7: 48 89 e5 mov %rsp,%rbp
几乎每一个函数的前两条指令都是这两个语句,刚好这条汇编指令就表明了栈帧结构的核心内容,我们可以先看这个结构图:
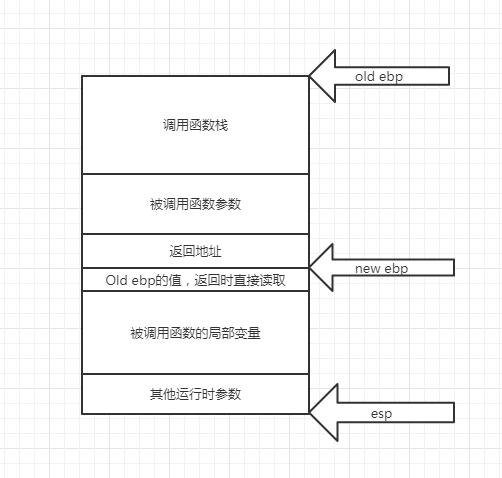
- 首先,我们需要明确的一点就是,main()函数并非程序真正的入口函数,在main()函数之前系统会做一系列的初始化操作,然后再调用main()
- 在上面我们就有提到过,rsp(由于平台的不一致,这里的rsp就是上述提到的esp)一直是指向栈顶位置,而ebp则指向当前执行函数的栈基地址。
- 如图所示,当发生函数调用时,调用者先将被调用函数的参数压栈,然后将返回地址压栈,然后在被调用函数中,将调用函数的ebp压栈,再将esp寄存器的值赋值给ebp,因为esp在调用之前总是指向栈顶的,将其赋值给ebp,就是从栈顶位置开始为被调用函数分配空间。
举个例子,当发生函数调用已经进入到被调用函数时,假如当前esp值(即栈顶位置)为0x10010,ebp的值为0x10000,先将ebp压栈,esp的指针往栈顶移四个字节,然后将ebp的值放入0x10014的位置(汇编中push操作先将栈顶指针后移,然后再将数据放入)。
然后将esp的值赋给ebp,这时候ebp的值为0x10014,然后为被调用函数分配空间.当函数返回时,再pop ebp,就可以将栈帧状态返回到被调用函数继续执行的状态。
分配内存空间
18 4004fa: 48 83 ec 10 sub $0x10,%rsp
这一条指令是 rsp-0x10,就如上述提到的,栈是由高地址向低地址延伸,所以减去0x10即是为main()函数分配0x10的局部空间。
调用函数的准备
19 int c = func(3,4);
20 4004fe: be 04 00 00 00 mov $0x4,%esi
21 400503: bf 03 00 00 00 mov $0x3,%edi
22 400508: e8 c9 ff ff ff callq 4004d6 <func>
这三条指令就是将被调用函数的参数放入寄存器中进行参数传递(经典实现为通过栈传递),从这里可以看到,显示传递参数4,然后再是参数3,从这里可以看出,不管是寄存器传递还是栈传递,C语言参数传递顺序都是从右往左。
第三条汇编指令callq,从字面意思可以看出这一条就是进行函数调用,call指令相当于:
pushl %eip //将eip寄存器中地址压栈,
movl func, %eip //将func()函数的地址放入eip寄存器中,当函数返回时取出这个地址放入eip寄存器即可。
eip寄存器中存放的是下一条将要执行指令的地址
进入到被调用函数
1 4004d6: 55 push %rbp
2 4004d7: 48 89 e5 mov %rsp,%rbp
熟悉的这两行,跟上面说的一样,保存调用者rbp,然后定位被调用函数ebp和esp。
获取参数
3 4004da: 89 7d ec mov %edi,-0x14(%rbp)
4 4004dd: 89 75 e8 mov %esi,-0x18(%rbp)
将参数从寄存器中取出,放到栈上,这里的栈并非像数据结构栈一样,虽然是一样的实现方式,但是这里除了支持pop和push,同时支持ebp的直接寻址操作。
赋值操作
5 int a=x,b=y;
6 4004e0: 8b 45 ec mov -0x14(%rbp),%eax
7 4004e3: 89 45 f8 mov %eax,-0x8(%rbp)
8 4004e6: 8b 45 e8 mov -0x18(%rbp),%eax
9 4004e9: 89 45 fc mov %eax,-0x4(%rbp)
这一部分就是赋值操作,先将实参从栈上取出,然后再赋值给形参a,b。
函数返回值
10 return a+b;
11 4004ec: 8b 55 f8 mov -0x8(%rbp),%edx
12 4004ef: 8b 45 fc mov -0x4(%rbp),%eax
13 4004f2: 01 d0 add %edx,%eax
将a和b相加,然后放在eax寄存器中返回。
执行返回
14 4004f4: 5d pop %rbp
15 4004f5: c3 retq
第一条指令将调用函数的rbp值赋值给rbp寄存器,这样就实现了栈帧结构的返回。
第二条指令retq,等价于
pop %eip
将返回值读出,作为下一条执行指令。
整个汇编程序的过程就是这样的,如果朋友们还没有看懂,我们再用gdb调试的方式来查看栈以及栈上的内容(博主在64位机上做的实验,所以字宽和寄存器容量与32位机上的结果不同,64位为8字节,32位为4字节)。
gdb下的程序执行
同样是以下的程序:
1 int func(int x,int y)
2 {
3 int a=x,b=y;
4 return a+b;
5 }
6 int main()
7 {
8 int c = func(3,4);
9 return c;
10 }
输入编译指令以及进入调试模式:
gcc -g test.c -o test
gdb test
进入调试模式之后,我们先在函数调用前、被调用函数执行开始、和函数调用之后打上断点:
b 8
b 3
b 10
然后键入'r'(run)执行程序,这时程序停在了第一个断点,即第8行。在这里我们先查看一下寄存器的值:
info registers esp ebp
输出结果为:
rsp 0x7fffffffdda0 0x7fffffffdda0
rbp 0x7fffffffddb0 0x7fffffffddb0
可以看到,在调用func()之前,main函数栈基地址为0x7fffffffddb0,而栈顶地址为0x7fffffffdda0,相差0x10,与上面输出的反汇编语句
18 4004fa: 48 83 ec 10 sub $0x10,%rsp
是对得上的,这是在栈上分配内存空间导致栈顶的向下延伸。
然后我们键入'c'(continue)继续执行程序,程序运行到第二个断点即func()函数中,第3行,我们再来看到当前的栈帧寄存器值:
info registers esp ebp
输出结果为:
rsp 0x7fffffffdd90 0x7fffffffdd90
rbp 0x7fffffffdd90 0x7fffffffdd90
这时候rsp和rbp寄存器的结果都是0x7fffffffdd90,为什么会是这个结果,而且两个寄存器结果一样呢?
我们再来看看栈上的具体内容:
x/20xw $rsp (x/n查看栈上指定长度的内存数据)
输出结果是这样的:
0x7fffffffdd90: 0xffffddb0 0x00007fff 0x0040050d 0x00000000
0x7fffffffdda0: 0xffffde90 0x00007fff 0x00000000 0x00000000
0x7fffffffddb0: 0x00400520 0x00000000 0xf7a2d830 0x00007fff
0x7fffffffddc0: 0x00000000 0x00000000 0xffffde98 0x00007fff
0x7fffffffddd0: 0x00000000 0x00000001 0x004004f6 0x00000000
可以看到,栈顶位置的数据为0x00007fffffffddb0,对比上面的数据可以发现这正是main()函数中rbp的值,而栈顶向高地址的第二个64位数据是0x000000000040050d。
对比上面的反汇编代码,可以发现这是main()函数中因函数调用而产生的断点,当函数返回时在这里继续向下执行。
所以func()函数返回时的这两条汇编指令可以返回到main()函数中:
14 4004f4: 5d pop %rbp
15 4004f5: c3 retq
至于为什么rsp和rbp在函数中是同一个值,就是因为函数中没有产生分配空间的行为,事实上与经典操作系统不同的是,这里的局部变量操作被直接放在寄存器中进行。
接着键入'c'(continue)继续向下执行,执行到第三个断点处,即func()函数已经返回,这时候我们再来看寄存器内容:
info registers esp ebp
输出结果为:
rsp 0x7fffffffdda0 0x7fffffffdda0
rbp 0x7fffffffddb0 0x7fffffffddb0
栈帧结构恢复到调用前。
调用时栈帧结构总结
即使是反汇编的详解加上对应的跟踪gdb调试器中的栈数据活动,博主觉得还是需要仔细地再梳理一遍,以免某些同学还是没有弄懂这个过程。我们重新贴上汇编代码,
int func(int x,int y)
{
1 4004d6: 55 push %rbp
2 4004d7: 48 89 e5 mov %rsp,%rbp
3 4004da: 89 7d ec mov %edi,-0x14(%rbp)
4 4004dd: 89 75 e8 mov %esi,-0x18(%rbp)
5 int a=x,b=y;
6 4004e0: 8b 45 ec mov -0x14(%rbp),%eax
7 4004e3: 89 45 f8 mov %eax,-0x8(%rbp)
8 4004e6: 8b 45 e8 mov -0x18(%rbp),%eax
9 4004e9: 89 45 fc mov %eax,-0x4(%rbp)
10 return a+b;
11 4004ec: 8b 55 f8 mov -0x8(%rbp),%edx
12 4004ef: 8b 45 fc mov -0x4(%rbp),%eax
13 4004f2: 01 d0 add %edx,%eax
}
14 4004f4: 5d pop %rbp
15 4004f5: c3 retq
int main()
{
16 4004f6: 55 push %rbp
17 4004f7: 48 89 e5 mov %rsp,%rbp
18 4004fa: 48 83 ec 10 sub $0x10,%rsp
19 int c = func(3,4);
20 4004fe: be 04 00 00 00 mov $0x4,%esi
21 400503: bf 03 00 00 00 mov $0x3,%edi
22 400508: e8 c9 ff ff ff callq 4004d6 <func>
23 40050d: 89 45 fc mov %eax,-0x4(%rbp)
24 return c;
25 400510: 8b 45 fc mov -0x4(%rbp),%eax
}
同时写出详细的流程:
- 16行:将调用main()的调用者函数的rbp值压栈
- 17行:将当前rsp的值赋给rbp,由此确定了main()的栈基地址。
- 18行:在栈上开辟0x10的地址空间,用于main()函数的执行
- 20-21行:将参数存入寄存器,以参数从右到左的顺序(为什么是存入寄存器而不是栈,上面有简单提到,下面我们也会详细讲到)
- 22行:调用func()函数,这里的调用即将eip寄存器压栈,eip寄存器存放是下一条将要指令的地址,在15行func()函数中的retq指令就是取出栈上的返回地址重新放回eip寄存器。
- 1-2行:进入到func()函数,将调用者main()函数的栈基地址入栈,然后将rsp的值赋给rbp。
我们可以之前的gdb分析看出,现在的ebp即栈基地址为:0x7fffffffdd90,而main函数的栈顶地址为:0x7fffffffdda0,这其中有两次push操作,一次为callq,一次为push %ebp,由于是64位,每一次操作占用8个字节,所以rsp向下增长0x10字节,即rsp从0x7fffffffdda0变成了0x7fffffffdd90,再将rsp赋值给rbp,自然就是0x7fffffffdd90。
- 3-9行:执行函数的相关操作。
- 11-13行:先执行加法操作,然后将结果放入eax寄存器作为返回值
- 14行:pop操作,此时栈顶为main()函数的rbp值,将栈帧还原到main()函数中。
- 15行:retq,pop操作,经过上一次pop操作,栈顶为23行main()函数中的断点地址,将其放入eip,即下一条指令将跳转回main()函数中。
- 23行:从eax寄存器中接收返回值,放入栈中相对与rbp的-0x4地址处,这里并没有做任何处理。
- 25行:main函数返回,将上一步放入栈中的值作为返回值放入eax寄存器中。
这个整个函数调用时栈帧变化的过程。如果到这里你还没有看懂的话.....
函数调用约定
在一些经典操作系统的书中,介绍的都是参数压栈,绝大部分的中间操作都是在栈上执行,但是博主上面贴出的示例明显不一样,例子中显示其实很多操作都是在寄存器中执行的,而没有使用到栈。这又是为什么呢?
这其实是计算机硬件的发展带来的优化结果,经典的操作系统如8086(16位),80386(32位),这两种操作系统都只有8个通用寄存器来存储函数调用时的中间数据,例如参数、返回值、栈帧结构指针等等。
即使是32位的计算机,8个寄存器极限状态(一般不会达到)最多也是8*4(8位/字节)=32字节数据,但是到了64位系统中,寄存器从8个到16个,同时扩展到了64位,容量扩充了很多,所以在某些情况下可以直接使用寄存器操作。
这里需要重点提及的主要是调用约定的问题。
调用约定种类
在函数调用时,关于压栈顺序、堆栈恢复等有一套相应的规则来进行约束,想想如果每个厂商都各执己见,那么就没有可移植性可言了。主要的调用约定有这几个:
- stdcall
- cdecl
- fastcall
- thiscall
- naked call 而stdcall、cdecl、fast call是我们要讨论的,他们分别有这样的特色:
stdcall
- 函数的参数压栈顺序为从右到左
- 参数的平衡由被调用者保持,即参数压栈时由调用者执行,但是执行完之后由被调用函数来销毁栈上的参数,保持堆栈平衡
- 参数优先用栈传递
这种调用约定的典型就是pascal语言,可能大家不太熟悉这种编程语言,它还被广泛用于win32的API中。
关于第二点由被调用参数来销毁栈上的数据,这导致这种调用方式并不支持可变参数函数的实现,因为可变参数函数类似printf()是在执行的时候才知道参数个数,但是被调用函数并不知道有多少个参数传入,所以也就不能正确地释放栈上的数据。(注2)
cdecl
- 函数的参数压栈顺序为从右到左
- 参数的平衡由调用者保持,即参数压栈时由调用者执行,执行完之后由调用函数来销毁栈上的参数,保持堆栈平衡
- 参数优先用栈传递
这是经典操作系统中C语言默认的调用方式,这种调用者保持堆栈平衡的调用方式是可变参数函数实现的基础,但是由于每个平台或者编译器的栈实现方式和结构不一样,将会加大实现程序可移植性的难度。
我们可以这样理解,在stdcall调用中,是自己的事情自己做,自己执行完就将空间还给系统,而这种调用方式下,是自己的事情爸爸做,这样在调用情况复杂的情况下会造成调用函数空间以及时间上的负担。
fastcall
- 函数的参数压栈顺序为从右到左
- 参数的平衡由调用者保持,即参数压栈时由调用者执行,执行完之后由调用函数来销毁栈上的参数,保持堆栈平衡
- 参数优先用寄存器传递
顾名思义,这种调用方式的目标就是快!
主要是由于第三个属性:参数优先使用寄存器传递。CPU访问内部寄存器就像是拿自己家的东西,而访问内存就像从仓库中取,需要在地址总线和数据总线的传输上消耗时间,寄存器速度比访问内存要快很多,所以能用寄存器自然不会舍近求远。
博主在X86-64机器上做了实验并结合相关资料,显示当实参小于6个时,参数由寄存器传递,当多余6个时,将多余参数压栈,知道这些我们就可以写出更高效的代码-参数尽量小于6个。
注1:在经典16或32位X86操作系统中,CPU有八个通用寄存器,但是随着CPU的高速更新换代,64位的X86-64架构有16个64位通用寄存器,效率更高,而且寄存器名也做了小小修改,博主的电脑为64位,所以是rsp而不是esp。(返回正文)
注2:这里所说的销毁(释放)栈上的数据事实上并不是像操作flash一下进行擦除操作,这里仅仅是rsp指针的移动,并不会对地址上的数据进行任何操作,所以栈上的数据依旧存在,下一次运行时会覆盖。所以我们经常会强调不要返回局部变量指针,这是因为局部变量中的数据并不是稳定的。另一个例子是函数体内定义的变量需要初始化,因为局部变量是在栈上分配内存,如果不初始化,局部变量的值就沿用了栈上上一次执行遗留下来的值,是不确定的。
好了,关于C/C++栈帧结构的讨论就到此为止啦,如果朋友们对于这个有什么疑问或者发现有文章中有什么错误,欢迎留言
原创博客,转载请注明出处!
祝各位早日实现项目丛中过,bug不沾身.