1. 安装visdom
2. 开启监听进程
python -m visdom.server
3. 访问
用chrome浏览器访问url连接:http://localhost:8097
4. 可视化训练
-
在之前定义网络结构(参考上一节)的基础上加上Visdom可视化。
-
在训练-测试的迭代过程之前,定义两条曲线,在训练-测试的过程中 再不断填充点 以实现 曲线随着训练动态增长:
from visdom import Visdom
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.', legend=['loss', 'acc.']))
-
第二行
Visdom(env="xxx")参数env来设置环境窗口的名称,这里什么都没传(在默认的main窗口下)。 -
viz.line的 前两个参数 是曲线的Y和X的坐标(前面是纵轴后面才是横轴) -
设置了不同的 win参数,它们就会在不同的窗口中展示,
-
第四行定义的是 测试集的loss 和 acc两条曲线,所以在X等于0时,Y给了两个初始值。
开始训练:
- 为了知道训练了多少个batch,设置一个全局的计数器:
global_step = 0
- 在每个batch训练完后,为训练曲线添加点,来让曲线实时增长:
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
-
这里用 win参数 来选择是哪条曲线,用
update='append'的方式添加曲线的增长点,前面是Y坐标,后面是X坐标。 -
在每次测试结束后,并在另外两个窗口(用win参数设置)中展示图像(.images) 和 预测值(文本用.text):
viz.line([[test_loss, correct / len(test_loader.dataset)]], [global_step],
win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().numpy()), win='pred', opts=dict(title='pred'))
完整代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
# 超参数
batch_size=200
learning_rate=0.01
epochs=10
# 获取训练数据
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True, #train=True则得到的是训练集
transform=transforms.Compose([ #transform进行数据预处理
transforms.ToTensor(), #转成Tensor类型的数据
# transforms.Normalize((0.1307,), (0.3081,)) # 进行数据标准化(减去均值除以方差),如果要显示数据就不要标准化
])),
batch_size=batch_size, shuffle=True) #按batch_size分出一个batch维度在最前面,shuffle=True打乱顺序
# 获取测试数据
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential( #定义网络的每一层,
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
net = MLP()
# 定义sgd优化器,指明优化参数、学习率,net.parameters()得到这个类所定义的网络的参数[[w1,b1,w2,b2,...]
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss()
# 定义两条曲线,在训练-测试的过程中
# 再不断填充点 以实现 曲线随着训练动态增长
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
# 定义的是 测试集的loss 和 acc两条曲线,所以在X等于0时,Y给了两个初始值。
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28) # 将二维的图片数据摊平[样本数,784]
logits = net(data) # 前向传播
loss = criteon(logits, target) # nn.CrossEntropyLoss()自带Softmax
optimizer.zero_grad() # 梯度信息清空
loss.backward() # 反向传播获取梯度
optimizer.step() # 优化器更新
global_step += 1
# 绘制训练集的loss的图
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0: # 每100个batch输出一次信息
print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0 # correct记录正确分类的样本数
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = net(data)
test_loss += criteon(logits, target).item() # 其实就是criteon(logits, target)的值,标量
pred = logits.argmax(dim=1)
correct += pred.eq(target.data).float().sum().item()
# 更新训练集的 loss 和 accuracy
# print('test accuracy: ', correct / len(test_loader.dataset))
viz.line([[test_loss, 100. * correct / len(test_loader.dataset)]], [global_step],
win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x', opts = dict(title = 'Real Image'))
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('
Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)
'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
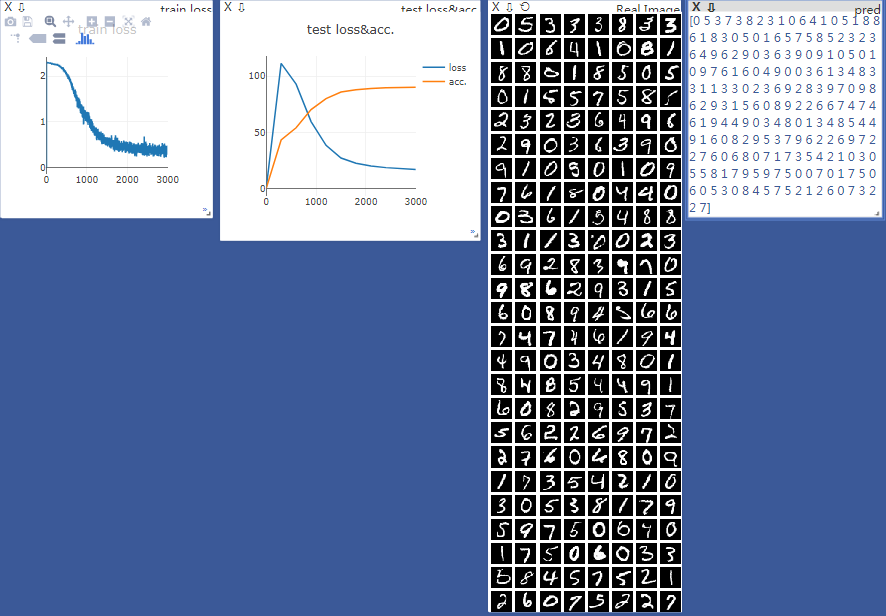
view result
Train Epoch: 0 [0/60000 (0%)] Loss: 2.300833
Train Epoch: 0 [20000/60000 (33%)] Loss: 2.282752
Train Epoch: 0 [40000/60000 (67%)] Loss: 2.260350
test accuracy: 0.4326
Test set: Average loss: 0.0111, Accuracy: 4326.0/10000 (43%)
Train Epoch: 1 [0/60000 (0%)] Loss: 2.243046
Train Epoch: 1 [20000/60000 (33%)] Loss: 2.179665
Train Epoch: 1 [40000/60000 (67%)] Loss: 2.034719
test accuracy: 0.5407
Test set: Average loss: 0.0093, Accuracy: 5407.0/10000 (54%)
Train Epoch: 2 [0/60000 (0%)] Loss: 1.852168
Train Epoch: 2 [20000/60000 (33%)] Loss: 1.656816
Train Epoch: 2 [40000/60000 (67%)] Loss: 1.399417
test accuracy: 0.7035
Test set: Average loss: 0.0060, Accuracy: 7035.0/10000 (70%)
Train Epoch: 3 [0/60000 (0%)] Loss: 1.263554
Train Epoch: 3 [20000/60000 (33%)] Loss: 1.032210
Train Epoch: 3 [40000/60000 (67%)] Loss: 0.860783
test accuracy: 0.8003
Test set: Average loss: 0.0038, Accuracy: 8003.0/10000 (80%)
Train Epoch: 4 [0/60000 (0%)] Loss: 0.833112
Train Epoch: 4 [20000/60000 (33%)] Loss: 0.625544
Train Epoch: 4 [40000/60000 (67%)] Loss: 0.610665
test accuracy: 0.8596
Test set: Average loss: 0.0027, Accuracy: 8596.0/10000 (86%)
Train Epoch: 5 [0/60000 (0%)] Loss: 0.657896
Train Epoch: 5 [20000/60000 (33%)] Loss: 0.530274
Train Epoch: 5 [40000/60000 (67%)] Loss: 0.471292
test accuracy: 0.8795
Test set: Average loss: 0.0023, Accuracy: 8795.0/10000 (88%)
Train Epoch: 6 [0/60000 (0%)] Loss: 0.418883
Train Epoch: 6 [20000/60000 (33%)] Loss: 0.421887
Train Epoch: 6 [40000/60000 (67%)] Loss: 0.429563
test accuracy: 0.8908
Test set: Average loss: 0.0020, Accuracy: 8908.0/10000 (89%)
Train Epoch: 7 [0/60000 (0%)] Loss: 0.429593
Train Epoch: 7 [20000/60000 (33%)] Loss: 0.368680
Train Epoch: 7 [40000/60000 (67%)] Loss: 0.389523
test accuracy: 0.8963
Test set: Average loss: 0.0019, Accuracy: 8963.0/10000 (90%)
Train Epoch: 8 [0/60000 (0%)] Loss: 0.382745
Train Epoch: 8 [20000/60000 (33%)] Loss: 0.352603
Train Epoch: 8 [40000/60000 (67%)] Loss: 0.347548
test accuracy: 0.8982
Test set: Average loss: 0.0018, Accuracy: 8982.0/10000 (90%)
Train Epoch: 9 [0/60000 (0%)] Loss: 0.346902
Train Epoch: 9 [20000/60000 (33%)] Loss: 0.367318
Train Epoch: 9 [40000/60000 (67%)] Loss: 0.369855
test accuracy: 0.9021
Test set: Average loss: 0.0017, Accuracy: 9021.0/10000 (90%)