1. Broadcasting
-
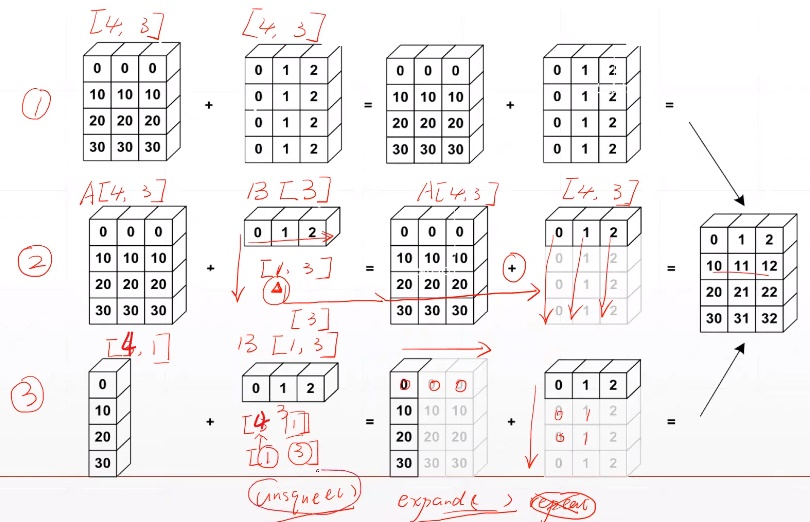
Broadcasting能够实现 Tensor自动维度增加(unsqueeze)与 维度扩展(expand)
-
使两个Tensor的shape一致,从而完成某些操作,主要步骤:
-
从最后面的维度开始匹配(一般后面理解为小维度);
-
在前面插入若干维度,进行unsqueeze操作;
-
将维度的size从 1 通过expand变到 和 某个Tensor相同的维度。
-
-
举例:
-
Feature maps:[4, 32, 14, 14]
-
Bias:[32, 1, 1](Tip:后面的两个1是手动unsqueeze插入的维度)-> [1, 32, 1, 1] -> [4, 32, 14, 14]
-
为什么使用broadcasting?
-
举例:
-
[class, students, scores]
-
Add bias for every students: +5 score
-
[4, 32, 8] + [4, 32, 8]
-
[4, 32, 8] + [1] ([1].unsqueeze(0).unsqueeze(0).expand_as(A): [1]->[1,1,1]->[4,32,8])
-
-
memory consumption (与repeat相比)
-
[4, 32, 8] => 1024
-
[5.0] => 1
-
匹配规则(从最后面的维度开始匹配):(符合boardcast规则,则自动完成)
-
if current dim=1,expand to same
-
if either has no dim,insert one dim and expand to same
-
otherwise,NOT broadcasting-able
A的维度[4, 32, 8],B的维度[1],[1]->[1, 1, 1]->[4, 32, 8],对应情况1
A的维度[4, 32, 8],B的维度[8],[1]->[1, 1, 8]->[4, 32, 8],对应情况2
A的维度[4, 3, 32, 32],B的维度[3, 1, 1], [3, 1, 1]->[1, 3, 1, 1]->[4,3,32,32]
A的维度[4, 32, 8],B的维度[4],对应情况3,不能broadcasting
2. 拼接与拆分
2.1 cat拼接操作
-
功能:通过dim指定维度,在当前指定维度上直接拼接 (concat)
-
默认是dim=0
-
指定的dim上,维度可以不相同,其他dim上维度必须相同,不然会报错
a1=torch.rand(4,3,32,32)
a2=torch.rand(5,3,32,32)
print(torch.cat([a1,a2],dim=0).shape) #torch.Size([9, 3, 32, 32])
a3=torch.rand(4,1,32,32)
print(torch.cat([a1,a3],dim=1).shape) #torch.Size([4, 4, 32, 32])
a4=torch.rand(4,3,16,32)
print(torch.cat([a1,a4],dim=2).shape) #torch.Size([4, 3, 48, 32])

2.2 stack拼接操作
-
与cat不同的是,stack是在拼接的同时,在指定dim处插入维度后拼接(create new dim)
-
stack需要 保证两个Tensor的shape是一致的,这就像是有两类东西,它们的其它属性都是一样的(比如男的一张表,女的一张表)。
-
使用stack时候要指定一个维度位置,在那个 位置前 会插入一个新的维度
-
因为是 两类东西 合并过来所以这个新的维度size是2,通过指定这个维度是0或者1来选择性别是男还是女。
-
默认dim=0
a1 = torch.rand(4,3,32,32)
a2 = torch.rand(4,3,32,32)
# 左边起第二个维度取0时,取上半部分即a1; 左边起第二个维度取1时,取下半部分即a2
print(torch.stack([a1, a2],dim=1).shape) # torch.Size([4, 2, 3, 32, 32])
print(torch.stack([a1,a2],dim=2).shape) #torch.Size([4, 3, 2, 32, 32])
a1 = torch.rand(4,3,16,32)
a2 = torch.rand(4,3,16,32)
print(torch.cat([a1, a2], dim=2).shape) # torch.Size([4, 3, 32, 32])
print(torch.stack([a1, a2], dim=2).shape) # torch.Size([4, 3, 2, 16, 32])
a = torch.rand(32, 8)
b = torch.rand(32, 8)
print(torch.stack([a, b], dim=0).shape) # torch.Size([2, 32, 8])
2.3 split分割操作
-
指定拆分dim
-
按长度拆分,给定拆分后的数据大小
c = torch.rand(3,32,8)
aa,bb = c.split([1,2],dim=0)
print(aa.shape,bb.shape) # torch.Size([1, 32, 8]) torch.Size([2, 32, 8])
aa,bb,cc = c.split([1,1,1],dim=0) # 或者写成aa,bb,cc=c.split(1,dim=0)
print(aa.shape,bb.shape,cc.shape) # torch.Size([1, 32, 8]) torch.Size([1, 32, 8]) torch.Size([1, 32, 8])
2.4 chunk分割操作
-
chunk是在指定dim下 按个数拆分 ,给定平均拆分的个数
-
如果给定个数不能平均拆分当前维度,则会取 比给定个数小的,能平均拆分数据的,最大的个数
-
dim默认是0
c = torch.rand(3, 32, 8)
d = torch.rand(2, 32, 8)
aa, bb = c.chunk(2, dim=0)
print(aa.shape, bb.shape) # torch.Size([2, 32, 8]) torch.Size([1, 32, 8])
aa, bb = d.chunk(2, dim=0)
print(aa.shape, bb.shape) # torch.Size([1, 32, 8]) torch.Size([1, 32, 8])
3. 基本运算
3.1 加减乘除
-
加法(a+b、torch.add(a,b))
-
减法(a-b、torch.sub(a,b))
-
乘法(*、torch.mul(a,b))对应元素相乘
-
除法(/、torch.div(a,b))对应元素相除,//整除
a = torch.rand(3, 4)
b = torch.rand(4)
c1 = a + b
c2 = torch.add(a, b)
print(c1.shape, c2.shape) # torch.Size([3, 4]) torch.Size([3, 4])
print(torch.all(torch.eq(c1, c2))) # tensor(True)
print(torch.all(torch.eq(a - b, torch.sub(a, b)))) # 减
print(torch.all(torch.eq(a * b, torch.mul(a, b)))) # 乘
print(torch.all(torch.eq(a / b, torch.div(a, b)))) # 除
3.2 矩阵乘法
-
torch.mm(only for 2d,不推荐使用)
-
torch.matmul(推荐)
-
@
a = torch.rand(2,1)
b = torch.rand(1,2)
print(torch.mm(a, b).shape) # torch.Size([2, 2])
print(torch.matmul(a, b).shape) # torch.Size([2, 2])
print((a @ b).shape) # torch.Size([2, 2])
- 应用于矩阵降维
x = torch.rand(4,784)
w = torch.rand(512,784) # channel-out对应512,channel-in对应784
print((x@w.t()).shape) # (4,784)x(784,512) torch.Size([4, 512]) Tip:.t()只适用于二维
多维矩阵相乘
-
对于高维的Tensor(dim>2)
-
定义其矩阵乘法 仅在最后的两个维度上,要求前面的维度必须保持一致,就像矩阵的索引一样,并且运算操作符只有torch.matmul()。
a = torch.rand(4, 3, 28, 64)
b = torch.rand(4, 3, 64, 32)
print(torch.matmul(a,b).shape) # torch.Size([4, 3, 28, 32])
c = torch.rand(4, 1, 64, 32)
print(torch.matmul(a,c).shape) # 符合broadcast机制,torch.Size([4, 3, 28, 32])
# d = torch.rand(4,64,32)
# print(torch.matmul(a,d).shape) # 报错
Tip:这种情形下的矩阵相乘,"矩阵索引维度" 如果符合Broadcasting机制,也会自动做广播,然后相乘。
3.3 次方pow(**操作)
a = torch.full([2, 2], 3)
b = a.pow(2)
c = a ** 2
print(a)
print(b)
print(c)
#tensor([[9., 9.],
# [9., 9.]])
3.4 开方sqrt
#接上面
c = b.sqrt() # 也可以a**(0.5)
print(c)
#tensor([[3., 3.],
# [3., 3.]])
d = b.rsqrt() # 平方根的倒数
print(d)
#tensor([[0.3333, 0.3333],
# [0.3333, 0.3333]])
3.5 指数exp与对数log运算
a = torch.exp(torch.ones(2, 2)) #得到2*2的全是e的Tensor
print(a)
#tensor([[2.7183, 2.7183],
# [2.7183, 2.7183]])
print(torch.log(a)) #取自然对数
#tensor([[1., 1.],
# [1., 1.]])
3.6 近似值运算
a = torch.tensor(3.14)
print(a.floor(), a.ceil(), a.trunc(), a.frac()) # 取下,取上,取整数部分,取小数部分
# tensor(3.) tensor(4.) tensor(3.) tensor(0.1400)
b = torch.tensor(3.49)
c = torch.tensor(3.5)
print(b.round(), c.round()) #四舍五入tensor(3.) tensor(4.)
3.7 裁剪运算clamp
-
对Tensor中的元素进行范围过滤,不符合条件的可以把它变换到范围内部(边界)上
-
常用于梯度裁剪(gradient clipping)
-
即在发生梯度离散 或 者梯度爆炸时对梯度的处理
-
(min, max): 小于min的都设置为min,大于max的都设置成max
-
实际使用时,可以查看梯度的(L2范数)模来看看需不需要做处理:w.grad.norm(2)
-
grad = torch.rand(2, 3) * 15 #0~15随机生成
print(grad.max(), grad.min(), grad.median())
# tensor(12.9533) tensor(1.5625) tensor(11.1101)
print(grad)
# tensor([[12.7630, 12.9533, 7.6125],
# [11.1101, 12.4215, 1.5625]])
print(grad.clamp(10)) # 最小是10,小于10的都变成10
# tensor([[12.7630, 12.9533, 10.0000],
# [11.1101, 12.4215, 10.0000]])
print(grad.clamp(3, 10)) # 最小是3,小于3的都变成3; 最大是10,大于10的都变成10
# tensor([[10.0000, 10.0000, 7.6125],
# [10.0000, 10.0000, 3.0000]])
4. 统计属性
4.1 范数norm
- Vector norm 和matrix norm区别

a = torch.full([8],1)
b = a.view(2,4)
c = a.view(2,2,2)
print(b)
#tensor([[1., 1., 1., 1.],
# [1., 1., 1., 1.]])
print(c)
#tensor([[[1., 1.],
# [1., 1.]],
# [[1., 1.],
# [1., 1.]]])
# 求L1范数(所有元素绝对值求和)
print(a.norm(1),b.norm(1),c.norm(1)) # tensor(8.) tensor(8.) tensor(8.)
# 求L2范数(所有元素的平方和再开根)
print(a.norm(2),b.norm(2),c.norm(2)) # tensor(2.8284) tensor(2.8284) tensor(2.8284)
# 在b的1号维度上求L1范数
print(b.norm(1, dim=1)) # tensor([4., 4.])
# 在b的1号维度上求L2范数
print(b.norm(2, dim=1)) # tensor([2., 2.])
# 在c的0号维度上求L1范数
print(c.norm(1, dim=0))
#tensor([[2., 2.],
# [2., 2.]])
# 在c的0号维度上求L2范数
print(c.norm(2, dim=0))
#tensor([[1.4142, 1.4142],
# [1.4142, 1.4142]])
4.2 均值/累加/最大/最小/累积
-
均值mean、累加sum、最小min、最大max、累积prod
-
最大值最小值索引argmax、argmin
b = torch.arange(8).reshape(2, 4).float()
print(b)
# tensor([[0., 1., 2., 3.],
# [4., 5., 6., 7.]])
# 均值,累加,最小,最大,累积
print(b.mean(), b.sum(), b.min(), b.max(), b.prod())
# tensor(3.5000) tensor(28.) tensor(0.) tensor(7.) tensor(0.)
# 不指定维度,输出打平后的最小最大值索引
print(b.argmax(), b.argmin()) # tensor(7) tensor(0)
# 指定维度1,输出每一行最大值所在的索引
print(b.argmax(dim=1)) # tensor([3, 3])
# 指定维度0,输出每一列最大值所在的索引
print(b.argmax(dim=0)) # tensor([1, 1, 1, 1])
Tip:
-
上面的argmax、argmin操作默认会将Tensor打平后取最大值索引和最小值索引
-
如果不希望Tenosr打平,而是求给定维度上的索引,需要指定在哪一个维度上求最大值或最小值索引。
4.3 dim/keepdim
-
例:shape=[4,10],dim=1时,保留第0个维度,即max输出会有4个值。
-
使用keepdim=True:可以 保持应有的dim
- 即,仅仅是将求最值的那个dim的size变成了1,返回的结果是符合原Tensor语义的。
a=torch.rand(4,10)
print(a.max(dim=1)) # 返回结果和索引
# torch.return_types.max(
# values=tensor([0.9770, 0.8467, 0.9866, 0.9064]),
# indices=tensor([4, 2, 2, 4]))
print(a.argmax(dim=1)) # tensor([4, 2, 2, 4])
# 如:这里使用keepdim=True,保持应有的dim=1
print(a.max(dim=1, keepdim=True))
# torch.return_types.max(
# values=tensor([[0.9770],
# [0.8467],
# [0.9866],
# [0.9064]]),
# indices=tensor([[4],
# [2],
# [2],
# [4]]))
print(a.argmax(dim=1,keepdim=True))
# tensor([[4],
# [2],
# [2],
# [4]])
- 这里保持应有的dim=0
# 这里使用keepdim=True,保持应有的dim=0
print(a.max(dim=0, keepdim=True))
# torch.return_types.max(
# values=tensor([[0.8339, 0.7886, 0.8641, 0.9699, 0.7194, 0.7754, 0.9818, 0.8987, 0.8183,
# 0.9588]]),
# indices=tensor([[0, 0, 0, 3, 2, 0, 2, 3, 0, 0]]))
print(a.argmax(dim=0,keepdim=True))
# tensor([[0, 0, 0, 3, 2, 0, 2, 3, 0, 0]])
4.4 topk 和 kthvalue
-
前k大topk(largest=True) / 前k小(largest=False) 的概率值及其索引
-
第k小(kthvalue) 的概率值及其索引
# 2个样本,分为10个类别的置信度
d = torch.randn(2, 10)
# 最大概率的3个类别
print(d.topk(3, dim=1))
# torch.return_types.topk(
# values=tensor([[2.0577, 0.9995, 0.9206],
# [1.6206, 1.4196, 0.5670]]),
# indices=tensor([[3, 6, 9],
# [2, 6, 3]]))
# 最小概率的3个类别
print(d.topk(3, dim=1, largest=False))
# torch.return_types.topk(
# values=tensor([[-0.6407, -0.3367, -0.3064],
# [-1.6083, -0.7407, 0.0508]]),
# indices=tensor([[7, 8, 0],
# [7, 1, 9]]))
# 求第8小概率的类别(一共10个那就是第3大,正好对应上面最大概率的3个类别的第3列)
print(d.kthvalue(8, dim=1))
# torch.return_types.kthvalue(
# values=tensor([0.9206, 0.5670]),
# indices=tensor([9, 3]))
4.5 比较操作
-
,>=,<,<=,!=,==
-
torch.eq(a,b)、torch.equal(a,b)
print(torch.equal(a, a)) # True
print(a == a)
print(torch.eq(a,a))
# tensor([[True, True, True],
# [True, True, True]])
# tensor([[True, True, True],
# [True, True, True]])
5. 高阶操作
5.1 where
-
使用
C = torch.where(condition, A, B) -
其中 A,B,C,condition是shape相同的Tensor
-
C中的某些元素来自A,某些元素来自B,这由 condition中 对应位置的元素是1还是0来决定。
-
如果condition对应位置元素是 1,则C中的该位置的元素来自 A 中的该位置的元素
-
如果condition对应位置元素是 0,则C中的该位置的元素来自 B 中的该位置的元素。
例: C[0,0,1]=A[0,0,1], C[0,0,2]=B[0,0,2], C[0,0,3]=B[0,0,3]....
cond = torch.tensor([[0.6,0.1],[0.8,0.7]])
a = torch.tensor([[1,2],[3,4]])
b = torch.tensor([[4,5],[6,7]])
print(cond>0.5)
# tensor([[ True, False],
# [ True, True]])
print(torch.where(cond>0.5, a, b))
# tensor([[1, 5],
# [3, 4]])
# [A[0], B[1]]
# [A[0], A[1]]
5.2 gather
torch.gather(input, dim, index, out=None)对元素实现一个查表映射的操作

prob = torch.randn(4,10)
idx = prob.topk(dim=1,k=3)
print(idx)
# torch.return_types.topk(
# values=tensor([[0.9902, 0.3165, 0.3033],
# [1.7028, 0.5323, 0.1279],
# [2.2629, 1.6216, 0.8855],
# [1.8379, 1.1718, 0.8398]]),
# indices=tensor([[1, 0, 9],
# [4, 0, 9],
# [8, 2, 1],
# [6, 9, 4]]))
# 得到索引
idx = idx[1]
print(idx)
# indices=tensor([[1, 0, 9],
# [4, 0, 9],
# [8, 2, 1],
# [6, 9, 4]]))
label = torch.arange(10)+100
print(label.expand(4, 10))
# tensor([[100, 101, 102, 103, 104, 105, 106, 107, 108, 109],
# [100, 101, 102, 103, 104, 105, 106, 107, 108, 109],
# [100, 101, 102, 103, 104, 105, 106, 107, 108, 109],
# [100, 101, 102, 103, 104, 105, 106, 107, 108, 109]])
print(torch.gather(label.expand(4,10), dim=1, index=idx.long()))
# tensor([[101, 100, 109],
# [104, 100, 109],
# [108, 102, 101],
# [106, 109, 104]])
label=[[100, 101, 102, 103, 104, 105, 106, 107, 108, 109],
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109],
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109],
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]]
index=[[8, 5, 4],
[6, 9, 8],
[1, 3, 8],
[6, 1, 3]]
- gather:利用 index 来 索引input特定位置 的数值。