1. 股票定向爬虫

2. 实例编写

2.1 建立工程和spider模板


(2)配置stocks.py文件
# -*- coding: utf-8 -*- import scrapy import re class StocksSpider(scrapy.Spider): name = 'stocks' start_urls = ['http://quote.eastmoney.com/stock_list.html'] def parse(self, response): for href in response.css('a::attr(href)').extract(): try: stock = re.findall(r'[s][hz]d{6}', href)[0] url = 'https://gupiao.baidu.com/stock/' + stock + '.html' print("debug:", url) yield scrapy.Request(url, callback=self.parse_stock) except: continue def parse_stock(self, response): print("解析股票......................................") infoDict = {} # 获取股票名字 stockInfo = response.css('.stock-bets') name = stockInfo.css('.bets-name').extract()[0] keyList = stockInfo.css('dt').extract() valueList = stockInfo.css('dd').extract() for i in range(len(keyList)): key = re.findall(r'>.*</dt>', keyList[i])[0][1:-5] try: value = re.findall(r'd+.?.*</dd>', valueList[i])[0][1:-5] except: value = '--' infoDict[key] = value infoDict.update( {'股票名称' : re.findall('s.*(', name)[0].split()[0] + re.findall('>.*<', name)[0][1:-1]}) yield infoDict

(3)对爬取项,进一步处理(配置piplines.py文件)
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class BaidustocksPipeline(object): def process_item(self, item, spider): return item class BaidustocksInfoPipeline(object): def open_spider(self, spider): self.f = open('BaiduStockInfo.txt', 'w') def close_spider(self, spider): self.f.close() def process_item(self, item, spider): try: line = str(dict(item)) + ' ' self.f.write(line) except: pass # 如果希望其他函数也处理这个item return item
(4)配置 ITEM_PIPELINES(配置settings.py文件)
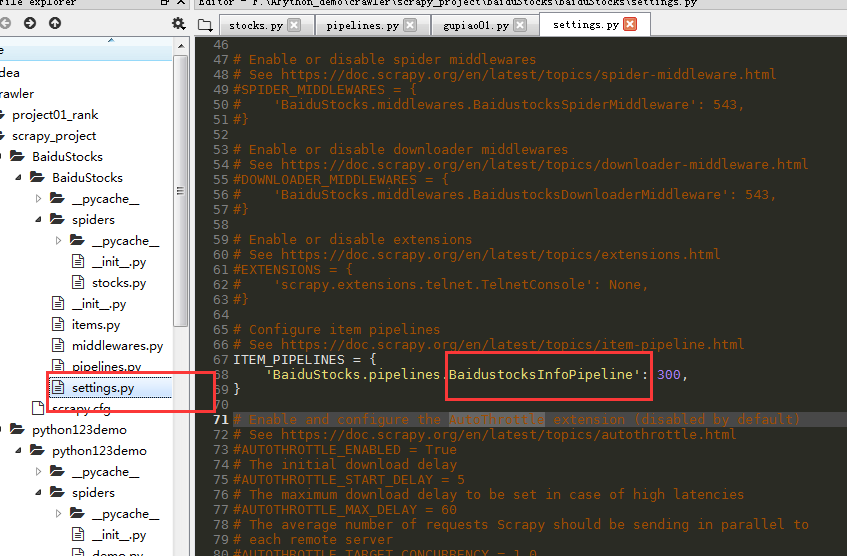
3. 实例优化
