1. 第一个scrapy实例

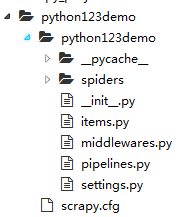
1.1 建立一个Scrapy爬虫工程
scrapy startproject python123demo



1.2 在工程中产生一个scrapy爬虫
(1)生成一个demo的爬虫
scrapy genspider demo python123demo.io

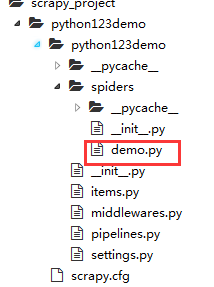
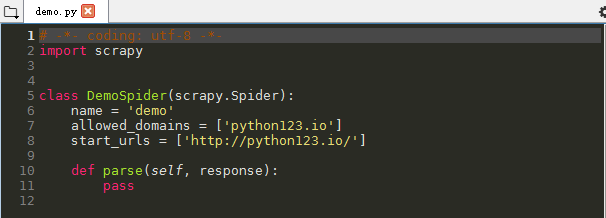

1.3 配置产生的spider爬虫
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' # allowed_domains = ['python123.io'] # 修改为需要访问的链接 start_urls = ['http://python123.io/ws/demo.html'] # 修改爬取方法 # response: 网络中返回内容的对象 def parse(self, response): fname = response.url.split('/')[-1] with open(fname, 'wb') as f: f.write(response.body) self.log('Saved file %s.' % fname)
1.4 运行爬虫,获取网页
(1)运行demo这个爬虫
scrapy crawl demo

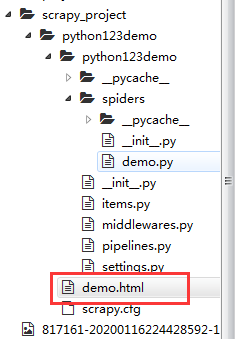 (成功)
(成功)
2. 完整版配置代码
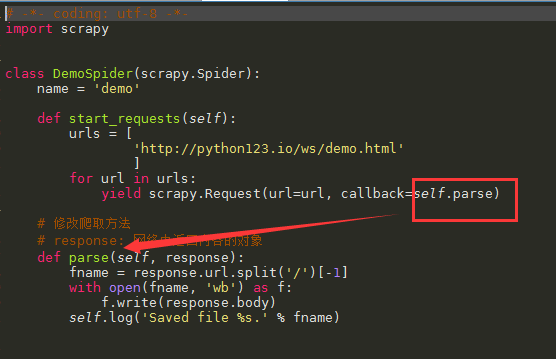
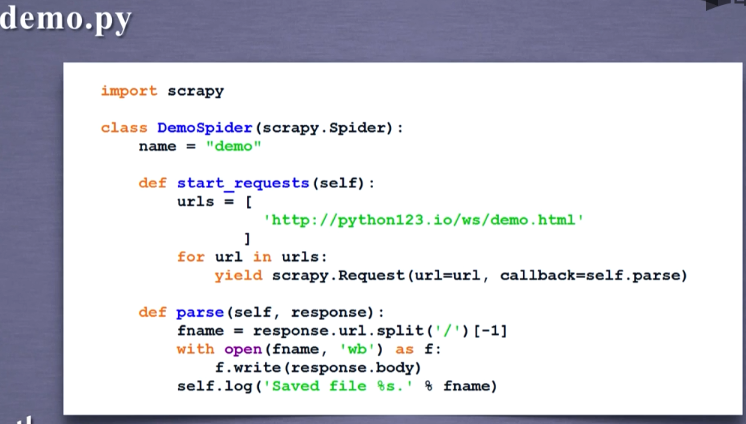
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name = 'demo' def start_requests(self): urls = [ 'http://python123.io/ws/demo.html' ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) # 修改爬取方法 # response: 网络中返回内容的对象 def parse(self, response): fname = response.url.split('/')[-1] with open(fname, 'wb') as f: f.write(response.body) self.log('Saved file %s.' % fname)

3. yield关键字




4. Scrapy爬虫的使用步骤







