1. scrapy安装(https://www.osgeo.cn/scrapy/intro/install.html)
建议直接使用anaconda安装,方便快捷,pip安装会遇到很多问题!!!!http://www.scrapyd.cn/doc/124.html
conda install -c conda-forge scrapy
提速可用:
conda config --add channels 'https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/'
conda config --set show_channel_urls yes
修改:C:UsersAdministrator .condarc文件
channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/ show_channel_urls: true ssl_verify: true
如果出现conda更新失败错误,试试这个:http://www.lqkweb.com/conda
上面我失败了,出现这个错误
Anaconda An HTTP error occurred when trying to retrieve this URL.HTTP errors are often intermittent
我改用的:(建议)
conda install scrapy
直接成功:
2. 框架结构

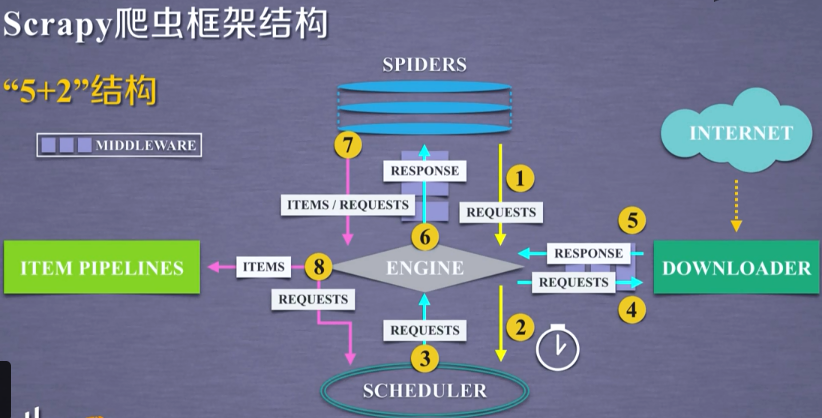
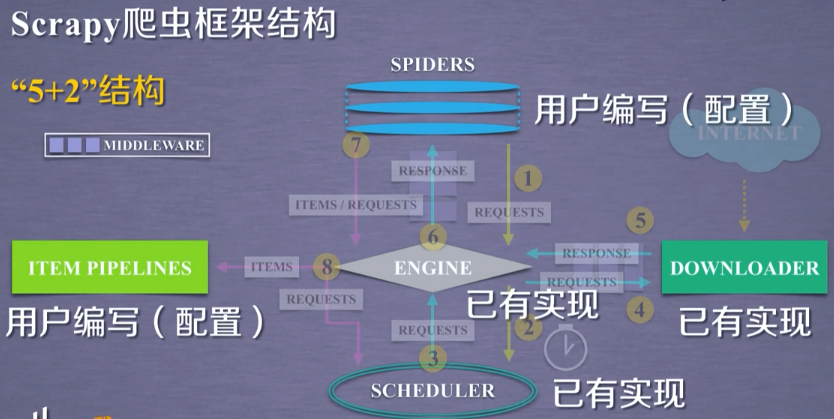
3. 框架解析
3.1 Engine
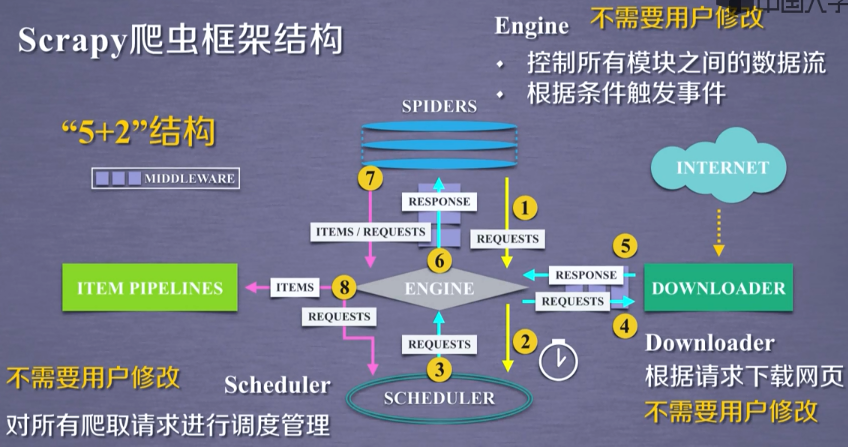
3.2 Downloader

3.3 Spider(核心)

3.4 Spider Middleware

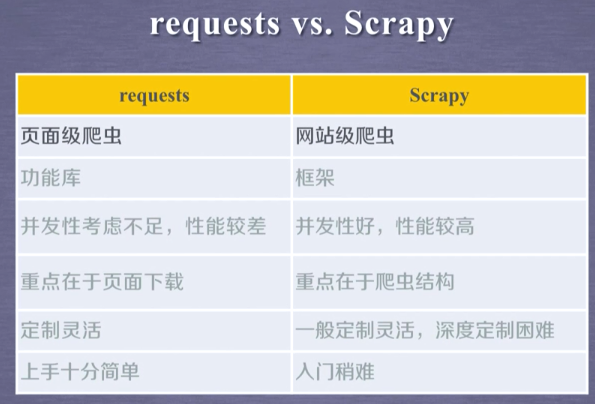
4. request和scrapy对比


5. scrapy常用命令