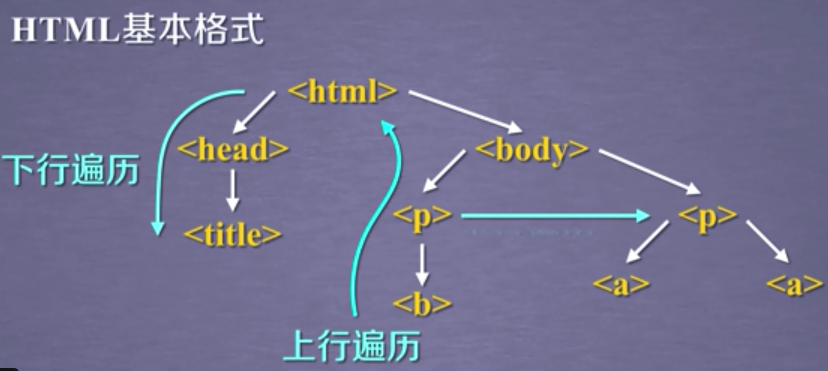
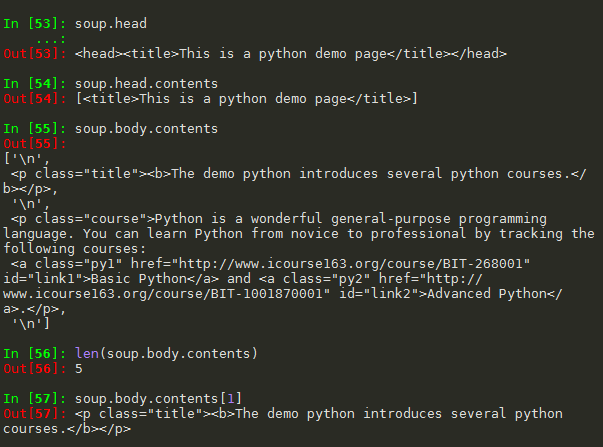
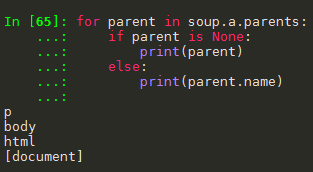
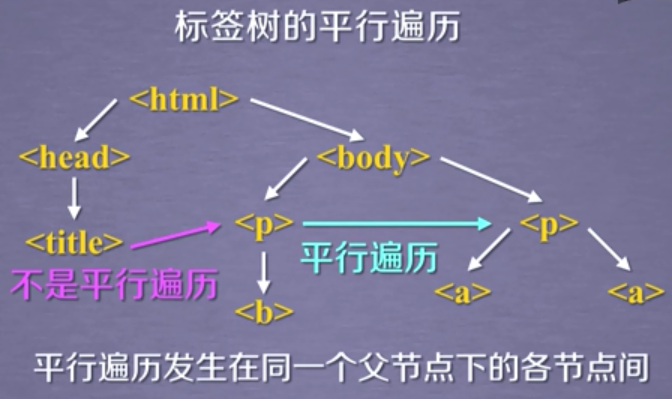
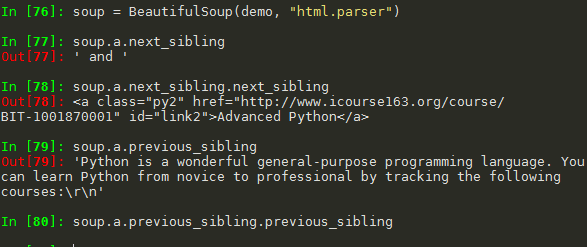
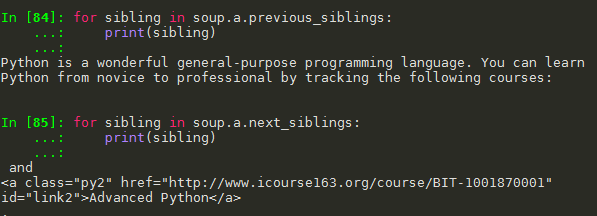
python爬虫笔记(四)网络爬虫之提取—Beautiful Soup库(2)基于bs4库的HTML内容遍历方法 1. 基于bs4库的HTML内容遍历方法 1.1 .contents 举例 1.2 结点的父亲标签 1.3 标签树的上行遍历(parents) 1.4 标签树的平行遍历 注意:标签的儿子结点可能是 NavigableString