1. Beautiful Soup安装
pip install beautifulsoup
linux要用 pip3
2. 使用
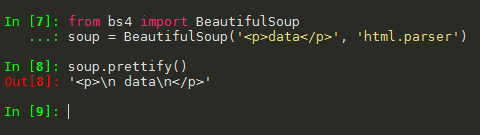
使用这个网站:https://python123.io/ws/demo.html

# -*- coding: utf-8 -*- """ Created on Tue Jan 21 21:29:56 2020 @author: douzi """ import requests from bs4 import BeautifulSoup r = requests.get("http://python123.io/ws/demo.html") print(r.text) demo = r.text soup = BeautifulSoup(demo, "html.parser") print(soup.prettify())
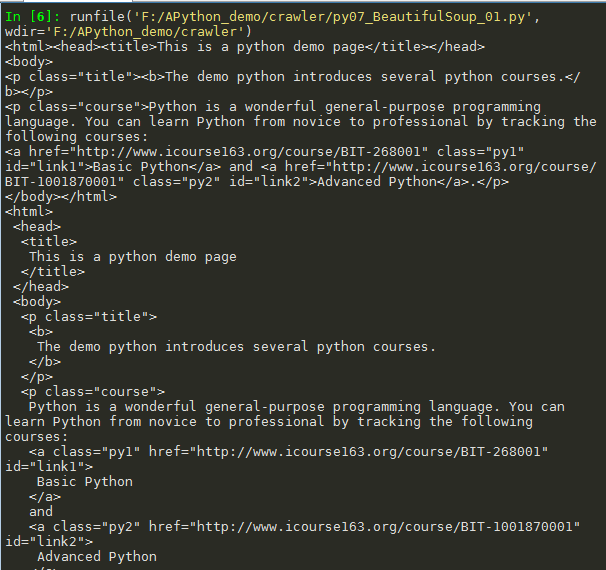
3. Beautiful Soup库的理解

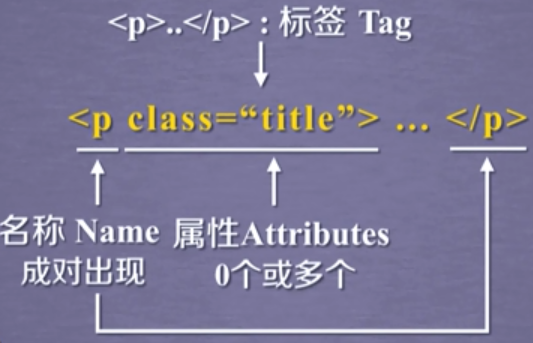



4. 获取html的Tag标签
4.1 title标签
import requests from bs4 import BeautifulSoup r = requests.get("http://python123.io/ws/demo.html") print(r.text, " ") demo = r.text soup = BeautifulSoup(demo, "html.parser") print(soup.title)
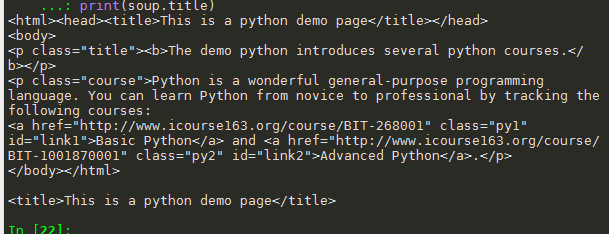
4.2 a标签(链接标签)
tag = soup.a print(tag)


4.3 获取标签属性
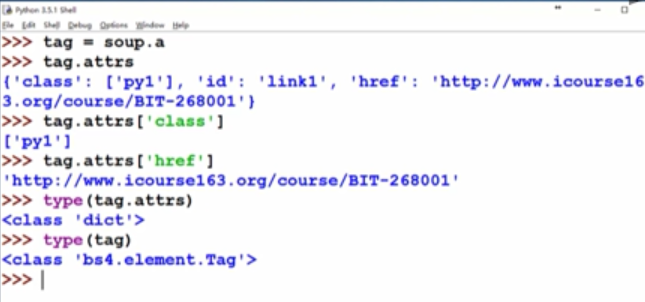
4.4 标签之间的字符串(NavigableString)

4.5 注释

5. 小结

