kylin2.3版本启用jdbc数据源(可以直接通过sql生成hive表,省去手动导数据到hive,并建hive表的麻烦)
说明:
jdbc数据源,本质上还是hive数据源。
由于数据库做大表关联方面性能还是不行。所以kylin的默认数据源仍然是hive,我觉得是非常合理的。
对应jdbc数据源,其实就是一种便利的方式。其基本原理就是通过连接数据库,选取所要用的表(或者sql查询)。
通过sqoop并行的抽取数据,并按照表名生成对应的hive表。cube的构建就根据生成的hive表进行。
每次构建的时候都重新抽取数据,生成hive表,构建完成之后,就把这个hive表删除掉。
相当于是自动做了之前开发需要 自己做的数据同步到hdfs、新建hive表、同步hive表到kylin这些繁琐重复的工作。
缺点:
1、基于以上说明,很容易得出其缺点就是这些hive表是瞬时的。每次构建都要现场去抽取全量的数据(从而增大了数据库的压力,增加了网络开销,并且拖慢了cube整体构建速度)。(这里可以通过定制其源码改成可配置的增量更新的方式,会更好用;但是要考虑表结构变更,是删除全表重建,还是要怎么处理)
2、由于表是瞬时的,就不能同时把这些表提供给其他方使用。
3、数据源方式不能共用,就是不能同时使用hive和jdbc数据源。这个对需要大数据平台处理的数据就不那么友好了,数据处理完再写会数据库会非常慢。
参考其官网说明和git
https://issues.apache.org/jira/browse/KYLIN-3044
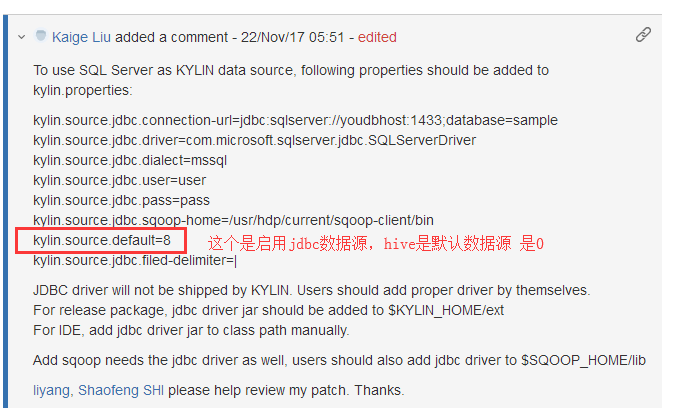
设置sqoop导入的默认并行度
