一、hashlib模块(加密模块)
1、什么叫hash:hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),
该算法接受传入的内容,经过运算得到一串hash值 2、hash值的特点是: 2.1 验证一致性:只要传入的内容一样,得到的hash值必然一样=====>要用明文传输密码文件完整性 校验 2.2 加密:不能由hash值返解成内容=======》把密码做成hash值,不应该在网络传输明文密 码 2.3 不可反推(如今已被反推):只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
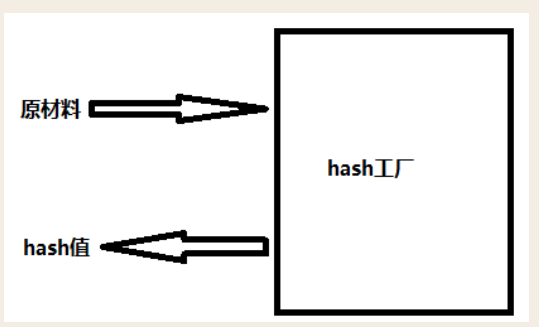
hash算法就像一座工厂,工厂接收你送来的原材料(可以用m.update()为工厂运送原材料),经过加工返回的产品就是hash值。
在我们输入密码后,就会现场经行加密,返回非服务端一份加密值,服务器拿着我们加密的值经行比较和记录。
import hashlib m=hashlib.md5() # m=hashlib.sha256() m.update('hello'.encode('utf8')) # 在解释器中使用的是utf8,所以需要解码。 print(m.hexdigest()) # 5d41402abc4b2a76b9719d911017c592 hexdigest是十六进制的编码,而digest是十进制 print(m.digest()) # b']A@*xbcK*vxb9qx9dx91x10x17xc5x92' m.update('alex'.encode('utf8')) print(m.hexdigest()) # 354ca34fd199b3cbcd45a7df7de2c5a6 m2 = hashlib.md5() m2.update('helloalex'.encode('utf8')) print(m.hexdigest()) # 354ca34fd199b3cbcd45a7df7de2c5a6 与之前一样 # 注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样,但是update多次为校验大文件提供了可能
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来
做加密。
import hashlib # ######## 256 ######## hash = hashlib.sha256('898oaFs09f'.encode('utf8')) # 在最开始加一个key,无序的 可以起到隐藏的作用 hash.update('alvin'.encode('utf8')) print (hash.hexdigest()) # e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
模拟撞库解码:
import hashlib passwds=[ 'alex3714', 'alex1313', 'alex94139413', 'alex123456', '123456alex', 'a123lex', ] def make_passwd_dic(passwds): # 用密码生成的解码对象生成一个字典 dic={} for passwd in passwds: m=hashlib.md5() m.update(passwd.encode('utf-8')) dic[passwd]=m.hexdigest() return dic def break_code(cryptograph,passwd_dic): # 判断字典里的值是否和我们给出的一样,从而打印出对应的密码 for k,v in passwd_dic.items(): if v == cryptograph: print('密码是===>�33[46m%s�33[0m' %k) # 这里033[46m [0m是颜色 cryptograph='aee949757a2e698417463d47acac93df' break_code(cryptograph,make_passwd_dic(passwds))
Python中还有一个hmac模块,它的内部对我们创建key和内容进一步的处理然后在加密
#要想保证hmac最终结果一致,必须保证: #1:hmac.new括号内指定的初始key一样 #2:无论update多少次,校验的内容累加到一起是一样的内容 import hmac h1=hmac.new(b'egon') h1.update(b'hello') h1.update(b'world') print(h1.hexdigest()) h2=hmac.new(b'egon') h2.update(b'helloworld') print(h2.hexdigest()) h3=hmac.new(b'egonhelloworld') print(h3.hexdigest()) ''' f1bf38d054691688f89dcd34ac3c27f2 f1bf38d054691688f89dcd34ac3c27f2 bcca84edd9eeb86f30539922b28f3981 '''
加盐操作:
大家知道,根据MD5算法的不可推性,相同的密码MD5值是一样的,所以我们可以大量的撞库来获取值,那为了再给我们的MD5值
上一把锁----->加盐:“加盐”就是对原密码添加额外的字符串,然后再生成MD5值,这样就没有办法进行破解了(谁也不知道你加的盐是什么),除非拿到“加盐”字符串,但碰撞方法也是需要一个一个重新计算MD5值后再进行碰撞对比的,难度也是极其大的。那么看下面的代码吧:


法一: import hashlib yan = '!任#意%字^符@' #定义加盐字符串 pwd = input('>>>') md5_pwd = hashlib.md5() md5_pwd.update((pwd+yan).encode('UTF-8')) #加盐 pwd = md5_pwd.hexdigest() #pwd = hashlib.new('md5',(pwd+yan).encode('UTF-8')).hexdigest() #也可以这样简写哦。。一句话搞定。 法二: import hashlib md5 = hashlib.md5('盐'.encode('utf-8')) # 选择加密方式 加盐 md5.update('alex3714'.encode('utf-8')) # 将明文转成字节然后进行加密 print(md5.hexdigest()) # 生成密文
二、logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,下面我们看一下怎么用。
import logging logging.debug('调试debug') logging.info('消息info') logging.warning('警告warn') logging.error('错误error') logging.critical('严重critical') ''' WARNING:root:警告warn ERROR:root:错误error CRITICAL:root:严重critical ''' # 显然前面的两个没有打印结果,因为级别太低,且这五个级别递增!
用法:
import logging logging.basicConfig(filename='example.log', level=logging.INFO) # 输出到指点文件中,level = logging.INFO表示INFO即以上的等级才能打印 logging.debug('This message should go to the log file') logging.info('So should this') logging.warning('And this, too') """ INFO:root:So should this WARNING:root:And this, too """
似乎忽略了时间:
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.')
"""
09/08/2018 05:39:56 PM is when this event was logged.
"""
为logging模块指定全局配置,针对所有logger有效,控制打印到文件中
可在logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,可用参数有 filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到 sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 #格式 %(name)s:Logger的名字,并非用户名,详细查看 %(levelno)s:数字形式的日志级别 %(levelname)s:文本形式的日志级别 %(pathname)s:调用日志输出函数的模块的完整路径名,可能没有 %(filename)s:调用日志输出函数的模块的文件名 %(module)s:调用日志输出函数的模块名 %(funcName)s:调用日志输出函数的函数名 %(lineno)d:调用日志输出函数的语句所在的代码行 %(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d:线程ID。可能没有 %(threadName)s:线程名。可能没有 %(process)d:进程ID。可能没有 %(message)s:用户输出的消息
实例:
#========使用
import logging
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10)
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
#========结果
access.log内容:
2017-07-28 20:32:17 PM - root - DEBUG -test: 调试debug
2017-07-28 20:32:17 PM - root - INFO -test: 消息info
2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn
2017-07-28 20:32:17 PM - root - ERROR -test: 错误error
2017-07-28 20:32:17 PM - root - CRITICAL -test: 严重critical
part2: 可以为logging模块指定模块级的配置,即所有logger的配置
但是上面打印到屏幕和写入文件只能选其一如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
formatter决定日志记录的最终输出格式。
logger :产生日志的对象
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel): 指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter(): 给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt): 新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
总结
#logger:产生日志的对象 #Filter:过滤日志的对象 #Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端 #Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
1、logging模块的Formatter、Hander、Logger、Filter对象实例
import logging #1、logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出 logger=logging.getLogger(__file__) #2、Filter对象:不常用,略 #3、Handler对象:接收logger传来的日志,然后控制输出 h1=logging.FileHandler('t1.log') #打印到文件 h2=logging.FileHandler('t2.log') #打印到文件 h3=logging.StreamHandler() #打印到终端 #4、Formatter对象:日志格式 formmater1=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p',) formmater2=logging.Formatter('%(asctime)s : %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p',) formmater3=logging.Formatter('%(name)s %(message)s',) #5、为Handler对象绑定格式 h1.setFormatter(formmater1) h2.setFormatter(formmater2) h3.setFormatter(formmater3) #6、将Handler添加给logger并设置日志级别 logger.addHandler(h1) logger.addHandler(h2) logger.addHandler(h3) logger.setLevel(10) #7、测试 logger.debug('debug') logger.info('info') logger.warning('warning') logger.error('error') logger.critical('critical')
2、Logger与Hander的级别
logger是第一级过滤,然后才能到handler,我们可以给logger和handler同时设置level,但是需要注意的是
略
3、Logger的继承
import logging formatter=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p',) ch=logging.StreamHandler() ch.setFormatter(formatter) logger1=logging.getLogger('root') logger2=logging.getLogger('root.child1') logger3=logging.getLogger('root.child1.child2') logger1.addHandler(ch) logger2.addHandler(ch) logger3.addHandler(ch) logger1.setLevel(10) logger2.setLevel(10) logger3.setLevel(10) logger1.debug('log1 debug') logger2.debug('log2 debug') logger3.debug('log3 debug') ''' 2017-07-28 22:22:05 PM - root - DEBUG -test: log1 debug 2017-07-28 22:22:05 PM - root.child1 - DEBUG -test: log2 debug 2017-07-28 22:22:05 PM - root.child1 - DEBUG -test: log2 debug 2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug 2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug 2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug '''
4、logging配置应用
import os import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, }, } def load_my_logging_cfg(): logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(__name__) # 生成一个log实例 logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__': load_my_logging_cfg()
三、collections模块
collections是Python内建的一个集合模块,提供了许多有用的集合类。
1、namedtuple:是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。可以验证创建的Point对象是tuple的一种子类
>>> from collections import namedtuple >>> Point = namedtuple('Point', ['x', 'y']) >>> p = Point(1, 2) >>> p.x 1 >>> p.y 2
>>> isinstance(p, Point) # p 是Point的对象 True >>> isinstance(p, tuple) #同时P也是tuple的对象 True
2、deque: 使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque >>> q = deque(['a', 'b', 'c']) >>> q.append('x') >>> q.appendleft('y') >>> q deque(['y', 'a', 'b', 'c', 'x']) #deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
3、defaultdict: 使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') #括号内可以设置可变数据类型 >>> dd['key1'] = 'abc' >>> dd['key1'] # key1存在 'abc' >>> dd['key2'] # key2不存在,返回默认值 'N/A 1例题 li = [ {'name':'alex','hobby':'抽烟'}, {'name':'alex','hobby':'喝酒'}, {'name':'alex','hobby':'烫头'}, {'name':'alex','hobby':'撩妹'}, {'name':'wusir','hobby':'小宝剑'}, {'name':'wusir','hobby':'游泳'}, {'name':'wusir','hobby':'打牌'}, {'name':'太白','hobby':'烫头'}, {'name':'太白','hobby':'洗脚'}, {'name':'太白','hobby':'开车'}, ] d = defaultdict(list) #创建一个列表将一个字典装起来,当然这里也可以创建其他类型,等价于{'x':[]} for i in li: d[i['name']].append(i['hobby']) print([dict(d)]) # 最后将其转换成字典 2例题:将下面颜色相同的数字相加,最后得到颜色和对应出现次数 li = [('红色',1),('黄色',1),('绿色',1),('蓝色',1),('红色',5),('绿色',1),('绿色',1),('绿色',1)] d = defaultdict(list) for i in li: d[i[0]].append(i[1]) dd = dict(d) for em in dd: dd[em] = sum(dd[em]) print(dd) #{'红色': 6, '黄色': 1, '绿色': 4, '蓝色': 1}
4、Counter:是一个简单的计数器,例如,统计字符出现的个数
>>> from collections import Counter >>> c = Counter() >>> for ch in 'programming': ... c[ch] = c[ch] + 1 ... >>> c #Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
1、 import collections login_user = [ (r'http://www.baidu.com', 'usr1', 'pwd1'), (r'http://www.youdao.com', 'usr2', 'pwd2'), (r'http://mail.126.com', 'usr3', 'pwd3') ] page_info = collections.namedtuple('login_info', ['url', 'username', 'password']) for user in login_user: x = page_info(*user) print(x)
# 上题运行结果 login_info(url='http://www.baidu.com', username='usr1', password='pwd1') login_info(url='http://www.youdao.com', username='usr2', password='pwd2') login_info(url='http://mail.126.com', username='usr3', password='pwd3') #如果打印元组。可以直接使用print(tuple(x)