一 生成器:
什么是⽣成器. ⽣成器实质就是迭代器.
在python中有三种方式来获取生成器:
1. 通过生成器函数
2. 通过各种推导式来实现生成器
3. 通过数据的转换也可以获取生成器
本质:迭代器(所以自带了__iter__方法和__next__方法,不需要我们去实现)
特点:惰性运算,开发者自定义
首先, 我们先看一个很简单的函数:
def func():
print("111")
return 222
ret = func()
print(ret)
结果:
111
222
# 将函数中的return改为yield就是生成器
def func():
print("111")
yield 222
ret = func()
print(ret)
结果:
<generator object func at 0x10567ff68>
运行的结果和上⾯不一样. 为什么呢. 由于函数中存在了yield. 那么这个函数就是一个生成器
函数. 这个时候. 我们再执行这个函数的时候. 就不再是函数的执行了. ⽽而是获取这个生成器.
如何使⽤呢? 想想迭代器. 生成器的本质是迭代器. 所以. 我们可以直接执行__next__()或则next()来执行
以下生成器.
def func():
print("111")
yield 222
gener = func() # 这个时候函数不会执行. 而是获取到生成器
ret = gener.__next__() # 这个时候函数才会执行. yield的作⽤和return一样. 也是返回
数据
print(ret)
结果:
111
222
那么我们可以看到, yield和return的效果是一样的. 有什么区别呢? yield是分段来执行一个
函数. return呢? 直接停止执行函数.
def func():
print("111")
yield 222
print("333")
yield 444
gener = func()
ret = gener.__next__() # 111
print(ret) # 222
ret2 = gener.__next__() #333
print(ret2) # 444
ret3 = gener.__next__() # 最后⼀一个yield执行完毕. 再次__next__()程序报错, 也就是
说. 和return无关了
print(ret3)
结果:
111
Traceback (most recent call last):
222
333
File "/Users/sylar/PycharmProjects/oldboy/iterator.py", line 55, in
<module>
444
ret3 = gener.__next__() # 最后⼀个yield执行完毕. 再次__next__()程序报错, 也
就是说. 和return⽆关了.
StopIteration
当程序运行完最后一个yield. 那么后⾯继续进行__next__()程序会报错.
好了生成器说完了. 生成器有什么作⽤用呢? 我们来看这样一个需求. 老男孩向JACK JONES订
购10000套学⽣生服. JACK JONES就比较实在. 直接造出来10000套衣服.
def cloth(): lst = [] for i in range(0, 10000): lst.append("⾐衣服"+str(i)) return lst cl = cloth() # 但是呢, 问题来了. 老男孩现在没有这么多学⽣啊. 一次性给我这么多. 我往哪里放啊. 很尴尬啊. 最好的效果是什么样呢? 我要1套. 你给我1套. 一共10000套. 是不是最完美的. def cloth(): for i in range(0, 10000): yield "⾐衣服"+str(i) cl = cloth() print(cl.__next__()) print(cl.__next__()) print(cl.__next__()) print(cl.__next__()) # 区别: 第⼀种是直接一次性全部拿出来. 会很占⽤用内存. 第二种使⽤生成器. 一次就一个. 用多少生成多少. 生成器是一个一个的指向下一个. 不会回去, __next__()到哪, 指针就指到哪儿.下一次继续获取指针指向的值.
接下来我们来看send方法, send和__next__()一样都可以让生成器执行到下一个yield,但是send可以给yield的前一个变量传值。第一次触发可以使用send(None)或则__next()__()
import time
def consumer(f):
print('%s开始吃包子了'%f)
while True:
baozi = yield # 使函数成为一个生成器
print('包子%s来了,被%s吃了'%(baozi,f))
def producer():
s = consumer('A')
b = consumer('B') # 在此建立两个生成器,等待调用
s.send(None) # 效果是 ‘准备吃包子了’
next(b) # 也可以写作 b.__next__ 或则 b.send(None)
print('老子开始做包子了')
for i in range(1,10,2):
time.sleep(1)
print('做了2个包子')
s.send(i)
# send和__next__()区别:
1. send和next()都是让生成器向下走一次
2. send可以给上一个yield的位置传递值, 不能给最后一个yield发送值. 在第一次执⾏生成器代码的时候不能使⽤用send(),除非b.send(None)
这里我们打个比方,就好比我们去饭店去吃饭,一个大圆桌,列表就像桌子上的菜,而生成器就是一个厨师,但是这个厨师有脾气,只能按着菜单顺序炒菜!(相比之下,圆桌空间有限,放的菜也是有限的,而有了厨师则一次上一个菜,就很节约空间); 还有一种比方就是,你喜欢吃鸡蛋,一次性买200个鸡蛋放冰箱,但是
当你吃到最后的时候,鸡蛋都坏了,但是如果你买一只母鸡回来,想吃每天都有。
生成器可以使用for循环来循环获取内部的元素:(for循环中本来就是调用__next__()方法)
def foo():
print('ok')
yield 1
print('ok2')
yield 2
return 'over'
# 第一种情况
g = foo()
next(g) # ok
next(g) # ok2
# 第二种情况
s = foo()
for i in s:
print(i) # ok 1 ok2 2 因为这里i = next(s) 就会打印yield的返回值


import time def tail(filename): f = open(filename) f.seek(0, 2) #从文件末尾算起 while True: # 使生成器成为无底洞 line = f.readline() # 读取文件中新的文本行 if not line: time.sleep(0.1) continue yield line tail_g = tail('tmp') for line in tail_g: print(line)
def init(func): #在调用被装饰生成器函数的时候首先用next激活生成器 def inner(*args,**kwargs): g = func(*args,**kwargs) next(g) return g return inner @init def averager(): total = 0.0 count = 0 average = None while True: term = yield average total += term count += 1 average = total/count g_avg = averager() # next(g_avg) 在装饰器中执行了next方法 print(g_avg.send(10)) print(g_avg.send(30)) print(g_avg.send(5))
#yield from 从某对象中迭代的拿出来 def gen1(): for c in 'AB': yield c for i in range(3): yield i print(list(gen1())) #['A', 'B', 0, 1, 2] def gen2(): yield from 'AB' yield from range(3) print(list(gen2())) #['A', 'B', 0, 1, 2]
二. 列表推导式, 生成器表达式以及其他推导式
列表推导式是通过一行来构建你要的列表, 列表推导式看起来代码简单. 但是出现错误之
后很难排查.
1、列表推导式的常⽤用写法:
[ 结果 for 变量 in 可迭代对象]
例. 从python1期到python14期写入列表lst:
lst = ['python%s' % i for i in range(1,15)]
print(lst)
2、我们还可以对列表中的数据进行筛选
筛选模式: [ 结果 for 变量 in 可迭代对象 if 条件 ]
# 获取1-100内所有的偶数
lst = [i for i in range(1, 100) if i % 2 == 0]
print(lst)
3、生成器表达式和列表推导式的语法基本上是一样的. 只是把[]替换成()
s = [x**3 for x in range(10)] # 这里生成的是一个列表
s = (x for x in range(10)) # 这里就是个生成器了 <generator object <genexpr> at 0x106768f10>
打印的结果就是一个生成器. 我们可以使用for循环来循环这个生成器:
gen = ("麻花藤我第%s次爱你" % i for i in range(10))
for i in gen:
print(i)
生成器表达式也可以进行筛选:
# 获取1-100内能被3整除的数
gen = (i for i in range(1,100) if i % 3 == 0)
for num in gen:
print(num)
# 100以内能被3整除的数的平⽅
gen = (i * i for i in range(100) if i % 3 == 0)
for num in gen:
print(num)
# 寻找名字中带有两个e的人的名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven',
'Joe'],['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
# 不用推导式和表达式
result = []
for first in names:
for name in first:
if name.count("e") >= 2:
result.append(name)
print(result)
# 推导式
gen = (name for first in names for name in first if name.count("e") >= 2)
for name in gen:
print(name)
4、生成器表达式和列表推导式的区别:
1. 列表推导式比较耗内存. 一次性加载. 生成器表达式几乎不占用内存. 使用的时候才分
配和使用内存
2. 得到的值不一样. 列表推导式得到的是一个列表. 生成器表达式获取的是一个生成器.
举个栗子.
同样一篮子鸡蛋. 列表推导式: 直接拿到一篮子鸡蛋. 生成器表达式: 拿到一个老母鸡. 需要
鸡蛋就给你下鸡蛋.
生成器的惰性机制: 生成器只有在访问的时候才取值. 说白了. 你找他要他才给你值. 不找他
要. 他是不会执行的
def func():
print(111)
yield 222
g = func() # 生成器器g
g1 = (i for i in g) # 生成器器g1. 但是g1的数据来源于g
g2 = (i for i in g1) # 生成器器g2. 来源g1
print(list(g)) # 获取g中的数据. 这时func()才会被执行. 打印111.获取到222. g完毕.
print(list(g1)) # 获取g1中的数据. g1的数据来源是g. 但是g已经取完了. g1 也就没有数据了
print(list(g2)) # 和g1同理理
def demo(): for i in range(4): yield i g=demo() g1=(i for i in g) #这里会使g1也是一个生成器 g2=(i for i in g1) print(list(g1)) #[0, 1, 2, 3] 这里调用了g1,所以现在g1已经空了。再一次就空了 print(list(g2)) #[] #如果直接调用g2,是可以得到答案的 print(list(g2)) #[0, 1, 2, 3]
深坑==> 生成器. 要值得时候才拿值.
字典推导式:
根据名字应该也能猜到. 推到出来的是字典
# 把字典中的key和value互换 dic = {'a': 1, 'b': '2'} new_dic = {dic[key]: key for key in dic} print(new_dic) # 在以下list中. 从lst1中获取的数据和lst2中相对应的位置的数据组成一个新字典 lst1 = ['jay', 'jj', 'sylar'] lst2 = ['周杰伦', '林林俊杰', '邱彦涛'] dic = {lst1[i]: lst2[i] for i in range(len(lst1))} print(dic)
集合推导式:
集合推导式可以帮我们直接生成一个集合. 集合的特点: 无序, 不重复. 所以集合推导式自
带去重功能
lst = [1, -1, 8, -8, 12] # 绝对值去重 s = {abs(i) for i in lst} print(s)
迭代器和生成器的调用顺序:
迭代器会在内存中生成相应的函数内存地址,而生成器只有在你要的时候才会给你地址,而且只能在__next__和send的情况下调用。
1、生辰器相关: 求结果 v = (lambda :x for x in range(10)) print(v) #一个生成器地址 <generator object <genexpr> at 0x0382E870> print(v[0]) # 注意生成器没有索引 TypeError: 'generator' object is not subscriptable print(v[0]()) # 生成器只能send或则next调用 TypeError: 'generator' object is not subscriptable print(next(v)) #一内存地址 <function <genexpr>.<lambda> at 0x03182F60> print(next(v)()) #1 2、求结果 v = [lambda :x for x in range(10)] print(v) #[<function <listcomp>.<lambda> at 0x02EE2F60>, ……十个地址 print(v[0]) #<function <listcomp>.<lambda> at 0x02EE2F60> print(v[5]()) #9 全是9,应为最后一个x为9,所有的函数执行时都引用一个9的内存 3、生成器list会触发生成器和迭代器,直到最后一个数。 l=list(lambda :x for x in range(10)) print(l[3]()) # 全是9,虽然函数地址不一样但是对应的x一直都是9 4、当lambda函数,只有返回值时 v =lambda :3 print(v()) #3

总结:
推导式有:列表推导式, 字典推导式, 集合推导式, 没有元组推导式
列表推导式:[结果 for 变量 in 可迭代对象 if 条件筛选]
字典推导式:{k:v for 变量 in 可迭代对象 if 条件筛选}
集合推导式:{k for 变量 in 可迭代对象 if 条件筛选}
生成器表达式: (结果 for 变量 in 可迭代对象 if 条件筛选)
生成器表达式可以直接获取到生成器对象. ⽣生成器对象可以直接进行for循环. 生成器具有
惰性机制.
一个面试题:难度系数500000000颗星:
def add(a, b): return a + b def test(): for r_i in range(4): yield r_i g = test() # 实现一个生成器 for n in [2, 10]: # 这里只执行了两次for循环,所以将10带入两次。最开始g=(0,1,2,3),执行两次add后,就是两次10于g累加 g = (add(n, i) for i in g) print(list(g)) #[20, 21, 22, 23] 友情提示: 惰性机制, 不到最后不会拿值 这个题要先读一下. 然后⾃⼰分析出结果. 最后⽤用机器跑⼀下.
相似类型题目分析:
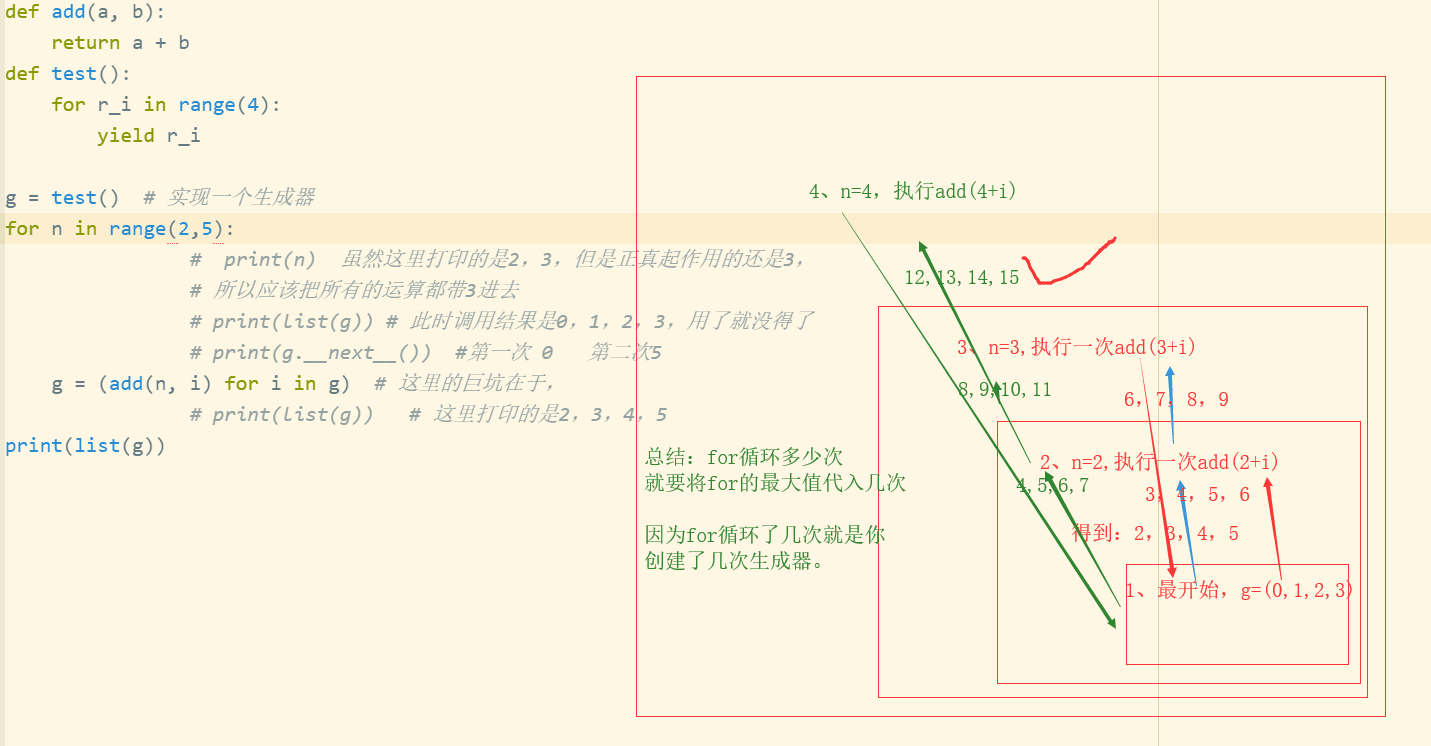
def add(a,b): return a+b def test(): for i in range(4): yield i s = test() g = test() # print(next(s)) # 0 # print(next(s)) # 1 # for i in s: # 此时s已经是一个生成器了 # print(i) # 0 1 2 3 例1、 for n in [2,10]: g = (add(n,i) for i in s ) #print(g) # 此时<generator object <genexpr> at 0x00000275C2F59360> #print(list(g)) # 结果是<generator object <genexpr> at 0x000002136FD79360> [2, 3, 4, 5] <generator object <genexpr> # at 0x000002136FD79410> [] [] 因为生成器只调用一次,就没有了 print(list(g)) # 结果是[10, 11, 12, 13] 这里的原因是,for[2,10]能顺利读取到10,所以是以10为标准,并且这里的s不会迭代使用,而是只进行一次 例2、 for n in [2,10]: g = (add(n,i) for i in g) # 和上面的区别是这里有一个迭代的效果 重复了一次g = (add(n, i) for i in (add(n, i) for i in g)) # 需要注意的是这里的n应该带10进去,因为每一次n进去,n代表的位置都要被取代 print(list(g)) # [20, 21, 22, 23]
解析:
补充:
# 迭代器相关补充: s = 'abcde' it = s.__iter__() # 获取迭代器 ret = list(it) # list内部含有__next__(),所以list可以将迭代器中的值一次性取出来 print(ret)
1、过滤掉长度小于3的字符串列表,并将剩下的转换成大写字母 li=['alex','wusir','abds','meet','ab'] li = [i.upper() for i in li if len(i)>3] print(li) 2、求(x,y)其中x是0-5之间的偶数,y是0-5之间的奇数组成的元祖列表 li = [(x,y) for x in range(0,6,2) for y in range(1,6,2)] print(li) 3、M = [[1,2,3],[4,5,6],[7,8,9]] 求M中3,6,9组成的列表 M = [[1,2,3],[4,5,6],[7,8,9]] li = [v for i in M for v in i if v%3 ==0] print(li) 4、求出50以内能被3整除的数的平方,并放入到一个列表中。 li = [ i**2 for i in range(50) if i%3==0] print(li) 5、构建一个列表:['python1期', 'python2期', 'python3期', 'python4期', 'python6期', 'python7期', 'python8期', 'python9期', 'python10期'] li =[ 'python%s期'%i for i in range(1,11)] print(li) 6.有一个列表l1 = ['alex', 'WuSir', '老男孩', '太白']将其构造成这种列表 ['alex0', 'WuSir1', '老男孩2', '太白3'] l1 = ['alex', 'WuSir', '老男孩', '太白'] li =[v+'%s'%i for i,v in enumerate(l1)] print(li) 7、(9)有以下数据类型: x = { 'name':'alex', 'Values':[{'timestamp':1517991992.94, 'values':100,}, {'timestamp': 1517992000.94, 'values': 200,}, {'timestamp': 1517992014.94, 'values': 300,}, {'timestamp': 1517992744.94, 'values': 350}, {'timestamp': 1517992800.94, 'values': 280} ],} 将上面的数据通过列表推导式转换成下面的类型: [[1517991992.94, 100], [1517992000.94, 200], [1517992014.94, 300], [1517992744.94, 350], [1517992800.94, 280]] li = [ [i['timestamp'],i['values']] for i in x['Values']] print(li)

在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。 arr = [[1,4,7,10,15], [2,5,8,12,19], [3,6,9,16,22], [10,13,14,17,24], [18,21,23,26,30]] ret = (i for v in arr for i in v) def getNum_1(num,arr): for i in ret: if num==i: return True print(getNum_1(18,arr)) def getNum(num, data=None): while data: if num > data[0][-1]: del data[0] print(data) getNum(num, data=None) elif num < data[0][-1]: data = list(zip(*data)) # 打散把每一组最大的找出来 del data[-1] # 删除最的一组 data = list(zip(*data)) # 再打散聚合 print(data) getNum(num, data=None) else: return True data.clear() return False if __name__ == '__main__': print(getNum(18, arr))
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。 arr = [[1,4,7,10,15], [2,5,8,12,19], [3,6,9,16,22], [10,13,14,17,24], [18,21,23,26,30]] ret = (i for v in arr for i in v) def getNum_1(num,arr): for i in ret: if num==i: return True print(getNum_1(18,arr)) # 法二 def getNum(num, data=None): while data: if num > data[0][-1]: del data[0] print(data) getNum(num, data=None) elif num < data[0][-1]: data = list(zip(*data)) # 打散把每一组最大的找出来 del data[-1] # 删除最的一组 data = list(zip(*data)) # 再打散聚合 print(data) getNum(num, data=None) else: return True data.clear() return False if __name__ == '__main__': print(getNum(18, arr))