第一次启动HDFS需对NameNode(简称NN)格式化
bin/hadoop namenode -format
HDFS动态添加和删除DataNode(简称DN),DN无需格式化而是在第一次启动时创建存储目录。DN可以管理多个目录,配置${dfs.data.dir} = "/data/datanode,/data2/datanode"
1.1 ${dfs.data.dir}目录
该目录一般有4个目录和2个文件。
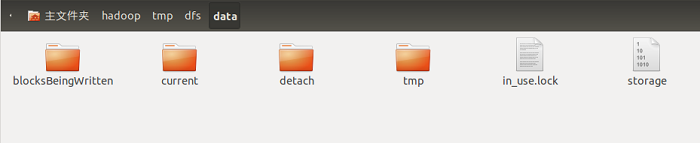
其中in_use.lock文件是在DataNode节点启动之后产生的,其中各个目录的作用如下:
blocksBeingWritten:该文件夹保存着当前正在”写“的数据块。
current:保存着HDFS文件系统中的数据块,这些数据块是成功提交到HDFS中的数据块。detach:用于配合数据节点升级,共数据块分离操作保存临时工作文件。
tmp:该文件夹保存着当前正在”写“的数据块,和blockBeingWritten文件夹的区别是,blockBeingWritten中的数据块写操作由客户端发起,tmp中的写操作由数据块复制引发,另一个数据节点正在发送数据到数据块中。
storage:0.13版本以前的Hadoop使用storage文件作为数据块的保存目录,和现在的目录结构不兼容,这个文件用于防止过旧的Hadoop版本在新的目录结构上启动,损坏系统。
in_use.lock:表明目录已经被使用,停止数据节点,该文件会消失,通过in_use.lock文件,数据节点可以保证独自占用该目录,防止两个数据节点示例共享一个目录,造成混乱。
1.2 ${dfs.data.dir}/current目录
current目录是数据节点中最重要的一个目录,它用于存放数据块,该目录中既包含目录,也包含文件,其中文件有两种类型:
HDFS数据块,保存着HDFS文件的内容;
-
用于保存数据块的校验信息的校验信息文件,以meta后缀名标识;
-
VERSION文件是一个Java属性文件,包含了HDFS的版本信息。
current目录如下图所示:
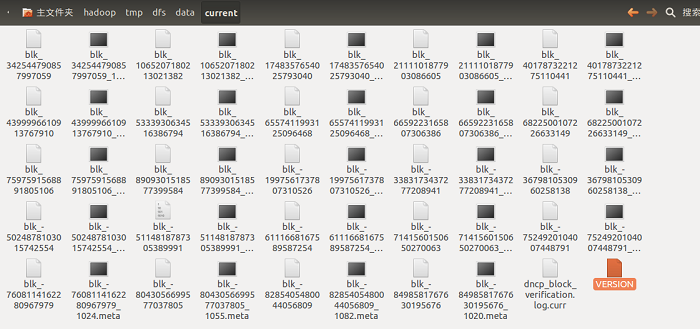
在这个图片中,没有目录,是因为当前的数据节点中的文件块的数量较少,只有当目录中存储的数据块增加到一定规模时,子目录名以subdir为前缀,然后后面加上目录编号,数据节点会创建一个新目录,用于保存新的块及元数据。目录中的数据块数达到64时,便会创建子目录,并形成一个更宽的目录结构,同时统一父目录下最多会创建64个子目录,所以在默认配置下,一个目录下最多只有64个文件块(128个文件)和64个子目录。这种目录管理方式既保证了目录深度不会太深,而影响检索文件性能,同时也避免了目录保存大量数据块,确保每个目录中的文件块是可控的。