安装scrpay框架,具体可参考https://blog.csdn.net/c406495762/article/details/60156205
windows下开发需要安装下pywin32模块才能正常调用
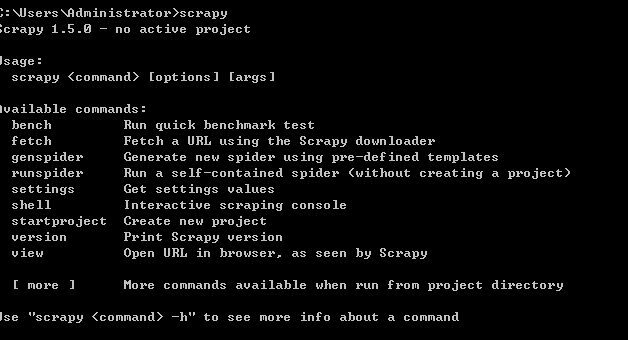
安装成功后打开命令行输入scrapy:可以看到里面的语法调用信息
创建项目:项目目录下命令行输入;scrapy startproject projectname(项目名称)

输入 cd projectname(上面输入的项目名称,进入到目录)
cd cnblogs
执行快速生成命令:scrapy genspider blogs https://news.cnblogs.com/
其中blogs表示名称,可自行定义,后面https://news.cnblogs.com/为需要采集的站点网址,这里以采集博客园新闻为例

输入命令:scrapy crawl blogs 运行
scrapy crawl blogs-- nolog (--nolog表示运行的时候不会输出系统自带的调试信息)
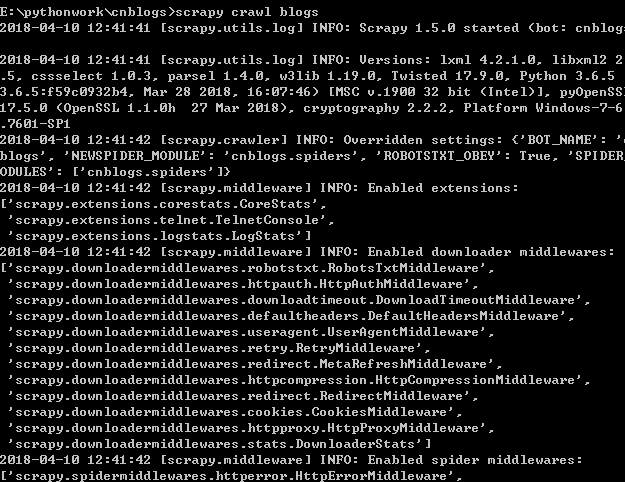
正常请求后可以看到抓取网页的一些信息
在pycharm中打开刚刚创建的项目,目录结构如下
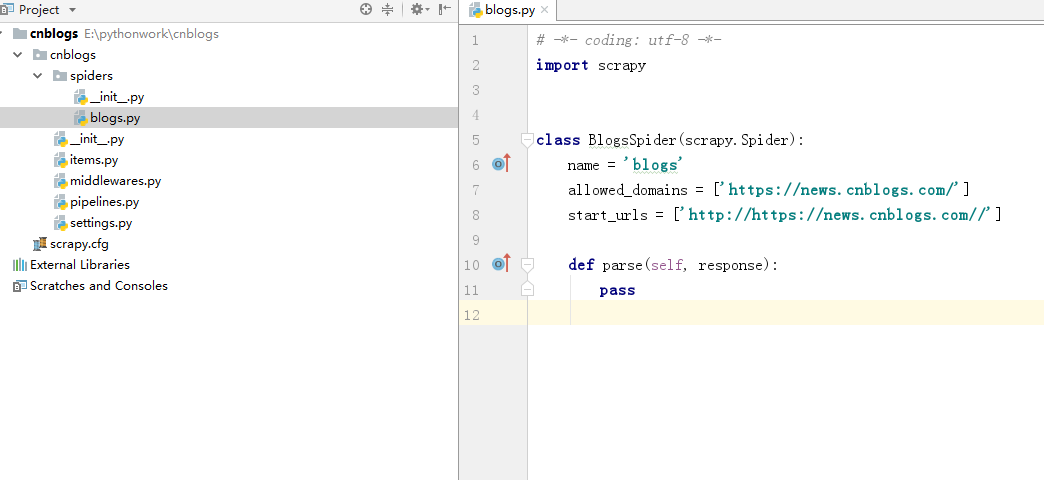
其中spiders下blogs.py就是上面scrapy genspider blogs https://news.cnblogs.com/这句代码所自动生成的
接下来在item中定义一个实体,用来接收抓取到的文章信息
item.py相关代码:
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class CnblogsItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 pass 15 16 17 class ArticleItem(scrapy.Item): 18 title=scrapy.Field() 19 img=scrapy.Field() 20 source=scrapy.Field() 21 viewcount=scrapy.Field() 22 releasetime=scrapy.Field()
blogs.py页面相关代码
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 from cnblogs.items import ArticleItem 5 6 class BlogsSpider(scrapy.Spider): 7 name = 'blogs' 8 allowed_domains = ['news.cnblogs.com'] 9 start_urls = ['https://news.cnblogs.com/'] 10 11 def parse(self, response): 12 articleList=response.css('.content') 13 for item in articleList: 14 article=ArticleItem() 15 article['title']=item.css('.news_entry a::text').extract_first() 16 article['img'] = item.css('.topic_img::attr(src)').extract_first() 17 article['source'] = item.css('.entry_footer a::text').extract_first().strip() 18 article['releasetime'] = item.css('span.gray::text').extract_first() 19 article['viewcount'] = item.css('.view::text').extract_first()[:-3] 20 yield article
导出的时候中文字符会有乱码,因此需要在配置文件settings.py里加上 FEED_EXPORT_ENCODING = 'utf-8',设置字符默认为中文编码
在Terminal终端运行命令: scrapy crawl blogs -o file.json
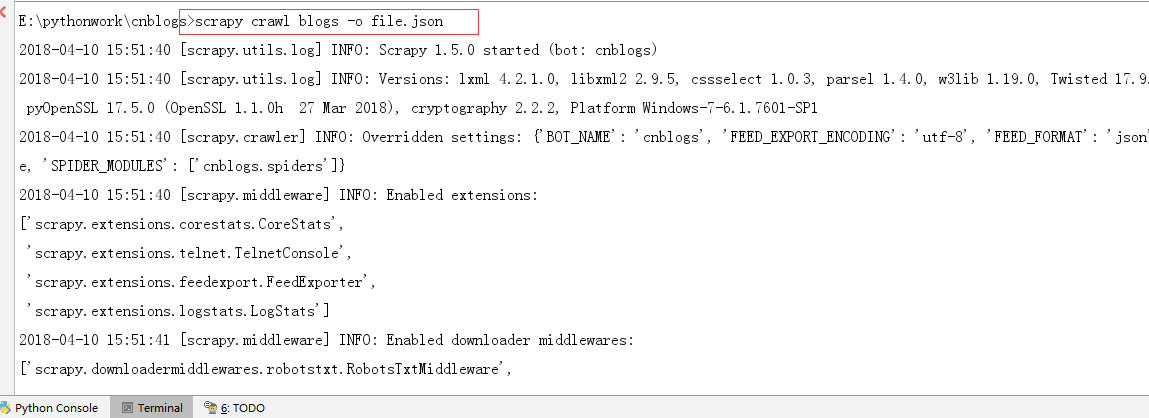
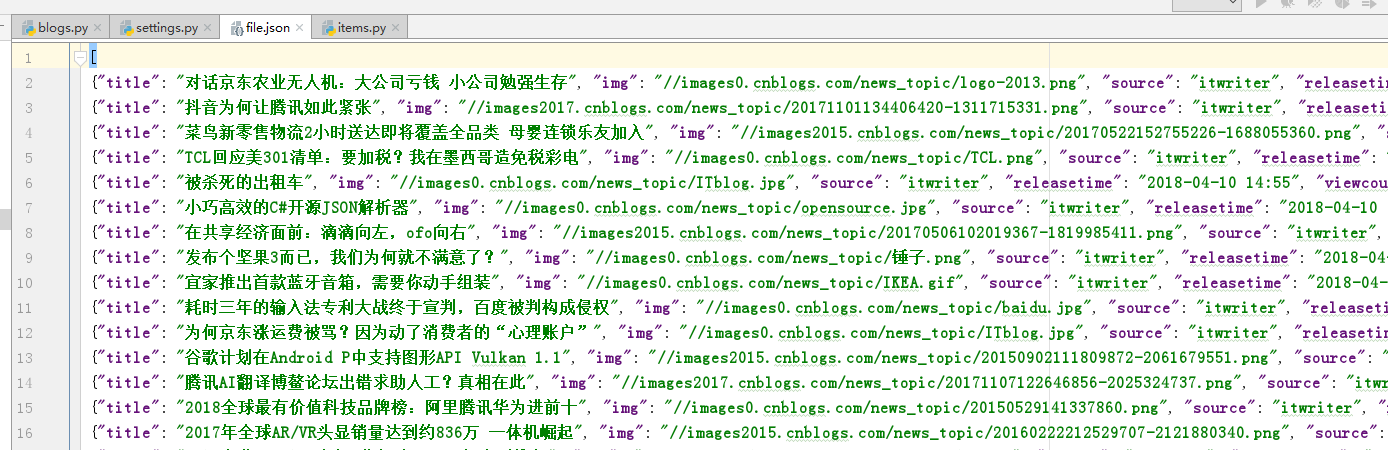
运行完成后在当前项目下会生成file.json文件
打开file.json文件如下:
导出的时候还支持其他格式,如xml.csv等,只需要吧后缀修改即可