项目背景:
主要爬取新浪微博用户的相册和视频,下载到本地。
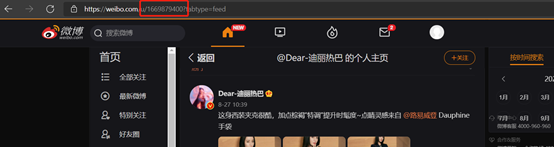
第一步 获取微博用户uid
找到想要获取的用户获取链接里的uid
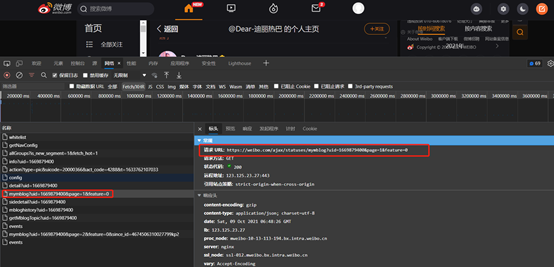
再检查网页,找到微博的api接口,接口里获取的数据包就有我们想要的内容
第二部 写代码
前期分析完后我们就可以来写代码了,
先引用需要的库

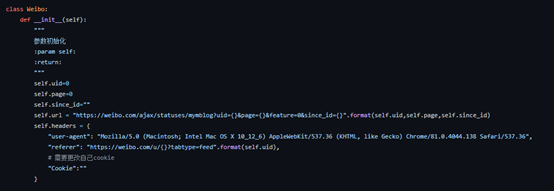
创建一个weibo类,并在构造方法初始化固定参数,如下:
然后去写一个获取单个页面json数据的方法

拿到json数据后就要开始解析它并得到目标数据,所以这里写一个解析json数据的方法,传入一个json参数,如下:
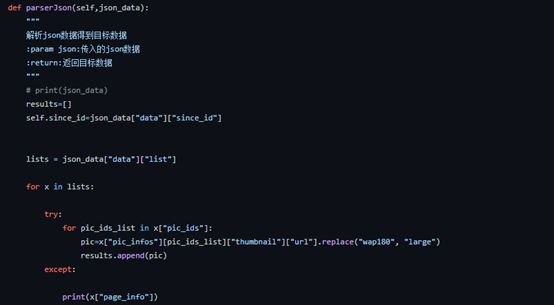
拿到json数据后就要开始解析它并得到目标数据,所以这里写一个解析json数据的方法,传入一个json参数,如下:
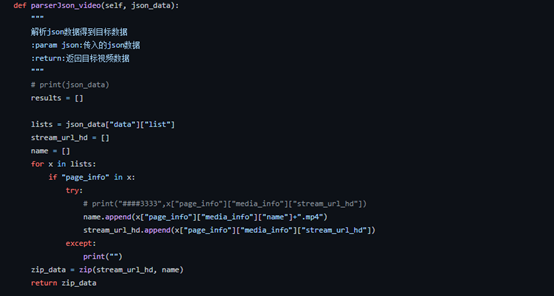
这里返回的是一个个列表,列表里面的元素是存储图片和视频信息的字典,得到图片信息后就可以开始下载了(最令人兴奋的下载环节),如下:
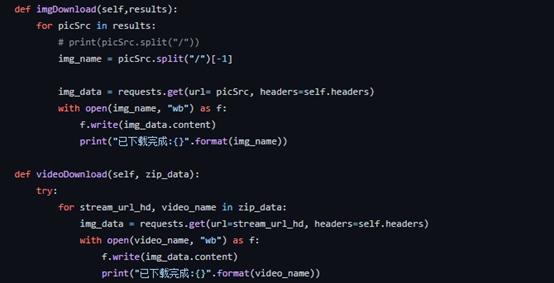
最后我们看看效果:
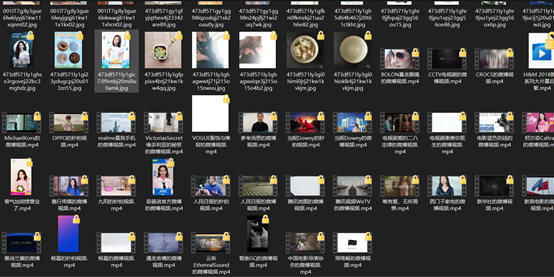
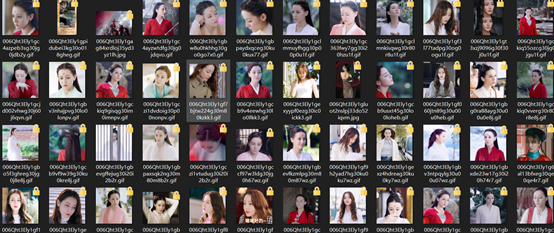
最后就没了,源码:
https://github.com/samxu1993/Reptile/blob/main/weibo_new.py ,上文如有错误或者疏漏之处欢迎指出,万分感谢。