记录java面试的每一个瞬间:
一、String、StringBuffer、StringBuilder的区别:
1:首先String的底层是一个被final修饰的字符数组,所以它是不可变的字符序列,拼接字符串的效率低,而StringBuffer、StringBuilder是可变的字符序列,
拼接字符串的效率较高。
2:如果强行使String的内容发生变化,那么将会产生一个新的字符串对象,而StringBuffer、StringBuilder是在其后追加内容。
3:StringBuffer起源于jdk1.0,而StringBuilder起源于jdk1.5。
4:StringBuffer 是线程安全的,相对来说效率较低,而stringBuilder是线程不安全的,相对来说是线程不安全的。
二、请解释overload 与 override的区别:
1.overlode:意为方法的重载,而override意为方法的重写
2.overlode:方法名相同,参数列表一定不同,与返回值的类型无关,
而override分为:基本数据类型以及void、引用数据类型、以及抛出的异常
a:基本数据类型以及void,返回值的类型与被重写的返回值的类型保持一致。
b:引用数据类型,返回值的类型小于等于被重写的返回值的类型。
c:抛出的异常类型小于等于被重写的异常类型。
d:修饰符的类型大于等于被重写的修饰的类型。
三、请解释final、finally、finalize的区别:
a:final可以修饰外部类,成员属性、成员方法,被final修饰的类不可以继承;被final修饰的属性不可以修改,即是常量;被final修饰的方法不可以被重写。
b:finally用于try{}catch(){}finally{}代码块儿中,放在finally中的代码一定会被执行,一般用于释放资源等操作。
c:finalize它是object中的方法,用来jvm的通知jvm的垃圾回收机制,对其进行回收。
四、ArrayList、linkList、Vector的区别:
ArrayList:
a:底层是动态的数组。
b:ArrayList是jdk1.2有的,较vectory晚了一些,是线程不安全的,同时也就意味着效率较高些。
c:当new ArrayList对象时,会调用一个默认的 private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};即是会创建一个空的数组常量,
当其第一次添加元素的时候,会初始化为10,后期会扩容到原来的1.5倍。
d:ArrayList只支持foreach 和迭代器遍历集合。
vectory:
a:底层是动态的数组。
b:vectory是jdk1.0就有的,较Arraylist早了一些,是线程安全的,当然线程安全就意味着效率相对来说低些。
c:vectory初始化的长度为10,可以自定义扩容,也可以按2倍扩容。
d:除了支持foreach和迭代器遍历数组外还支持旧版的迭代器Enumration
linkList:
a:底层是双向列表,jdk1.6之后也是双端序列。
b:它的子类是stack,特点:先进后出。
五、hashmap 和hashtable的区别,以及hashmap的底层是什么?
hashtable:
a:它是jdk1.0就有的,底层是基于哈希表,它是线程安全的,效率相对来说较低。
b:不允许存储null键和null值。
hashmap:
a:它是jdk1.2才有的,底层是基于哈希表的,它是线程不安全的,效率相对来说是比较高的。
b:允许存储null值和null键。
hashmap的底层的实现(jdk1.6):
hashmap的底层是动态的数组加上链表,首先数组会先初始化长度为16的数组,这个数组的元素的类型是Entry类型的数组,当存储一对映射的关系时,取出key,计算它对应的hashcode值,用这个hashcode值与数组的长度做运算,得到index[index的范围是0,table.length - 1],先判断table[index]是否为空,如果为空,那么就将映射关系封装成Entry的对象,存储到table[index],如果table[index]不为空,那么就要用key与table[index]中的所有映射关系的key进行equals比较,如果返回的结果为true,此时说明该key已经存在,那么就用新的key对应的value来替换旧的key对应的value,如果table[index]下面的映射关系的key与新添加的映射关系的key进行equals比较返回的值为false,说明要添加的key在原来的映射关系中不存在,那么就将新的key对应的映射关系封装进Entry对象中,连接到table[index]的下面的链表head部,此时注意添加映射关系时,如果table[index]不为空,并且size已经到达临界值,即阈值(阈值 = table.length * 0.75(负载因子:所谓的负载就是到达容量的极限))时,数组table就会扩容,扩容到原来的2倍,如果一旦扩容的话,所有的映射关系要用hashCode值来计算存储位置。
hashmap的底层的实现(jdk1.8):
hashmap的底层是动态的数组加上链表/红黑树,首先也是先创建长度为16的数组,这个数组的类型是Node类型,当存储映射关系时,取出key的值,并计算它对应是hashcode值,用这个hashcode值与数组做运算,可以的出index[index的范围是0 - table.length - 1],然后判断table[index]的值是否为空,如果为空,那么就将映射关系封装成Node类型的对象,存储到table[index]中,如果table[index]不为空的话,那么就要用key与table下面的映射关系的key进行equals比较,如果返回的结果是 true,说明此key已经存在,那么就用新的key对应的value去覆盖返回为true的key对应的value的值。
如果返回的结果是false的话,那么就要分情况了:
a:如果table[index]的下面是一个红黑树,那么新的映射关系的对象封装到TreeNode对象上,然后连接在叶子的节点上。
b:如果table[index]的下面不是一个红黑树,而链表的长度没有超过8个,那么新的映射关系封装成Node类型,连接到链表的尾部。
c:如果table[index]的下面不是一个红黑树,而链表的长度超过了8个,此时还要判断table的长度有没有超过64,如果没有的话,那么需要先扩容,然后先把map中的所有的映射关系重新调整位置,然后在根据hash值与数组做运算,然后重复上面的操作。
d:如果table[index]的下面不是一个红黑树,而链表的长度超过了8个,而此时table数组的长度超过了64,那么把table[index]下面的链表变成一个红黑树,然后新的映射关系封装为TreeNode,连接到叶子结点上。
e:当size达到临界值值,table数组就会扩容,扩容到原来的2倍,一旦扩容,所有的映射关系就需要重新用hashcode值来计算存储的位置。
六、preparedStatement和statement的区别:
preparedStatement是statement的子类,也就是说prepareStatement是statement的扩展,延伸,所以preparedStatement相对于statement来说有一些优势:
1.preparedStatement拼接sql简单。
2.preparedStatement可以防止sql注入。(也是拼接sql的问题)
3.preparedStatement效率比statement执行效率高(在oracle中是这样的,但是在mysql中却不一定)。
4.preparedStatement支持blob类型的数据。 七、where和having的区别:
where和having都是对结果进行过滤的。但是使用的时候,他们是由区别的:
1.首先在直观的位置上来说的话,having位于where的位置的后面。
2.having后面可以跟聚合函数(sum(),max(),min(),avg()等)而且可以使用select字段中的别名,而where不可以。
3.where一般使用于分组前数据的筛选,having一般用于分组后数据的筛选。
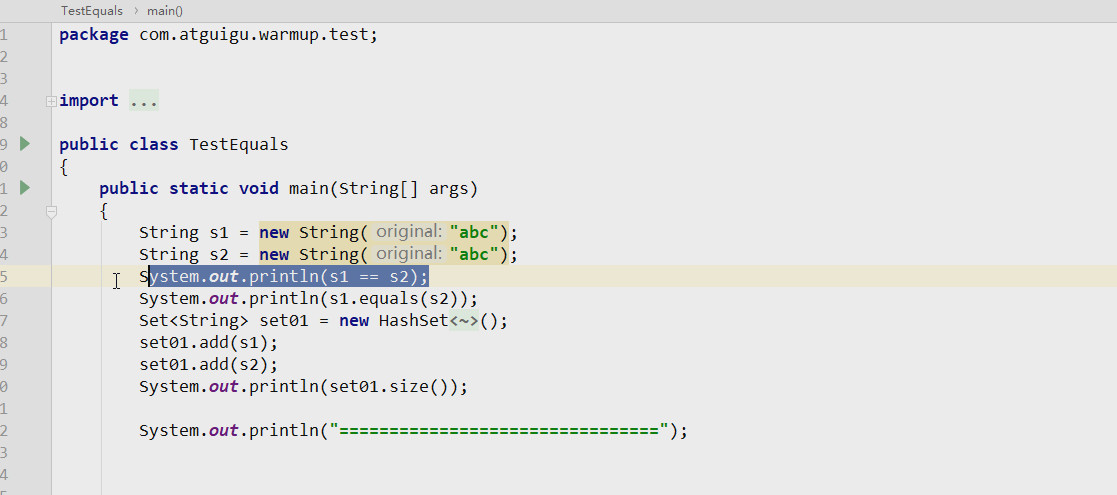
七:java中的传值与传引用的问题,如下代码:
而Person类中是一个简单的javaBean类,然后在这个类中有一个构造方法:(Person类就不再写了,知道大概的含义就好)
public Person(String personName){ this.personName = personName; }
要求:就是判断出依次打印的结果是什么?
这道题考察的就是,值传递? or 引用传递的问题?
1.值传递:程序的入口是main(),然后走到17行的代码,然后到18行,声明一个变量 int age = 20;
然后调用test.changeValue1(age)的方法,如下图:
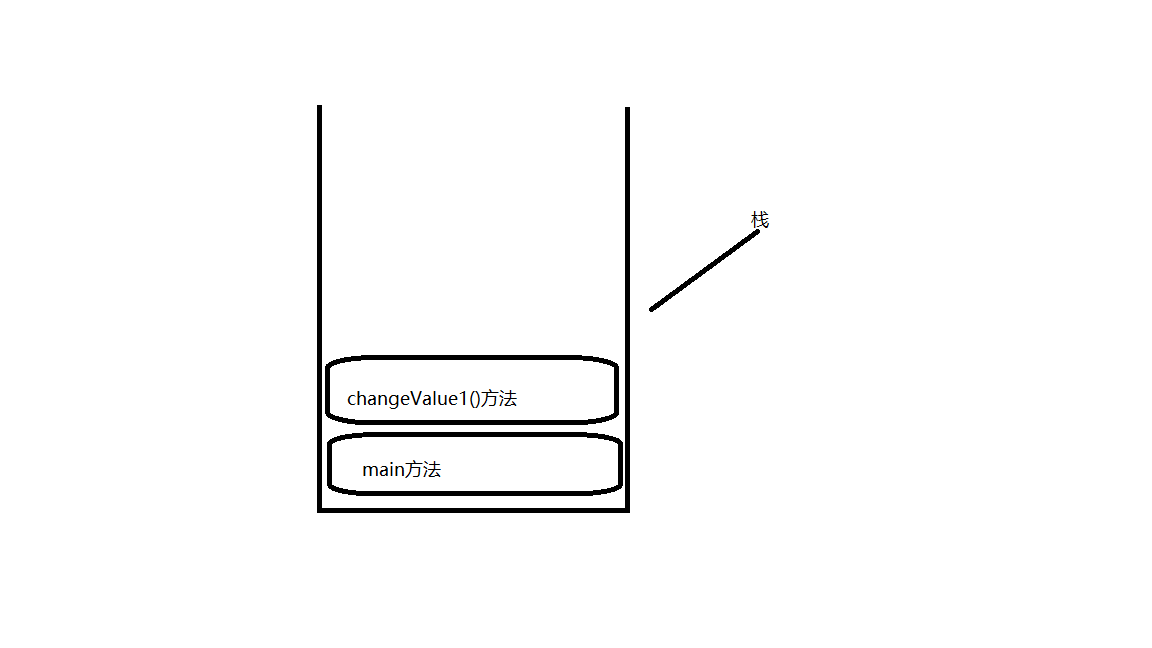
然后将20传递到changeValue1()的方法中,然后age=30,然后方法弹栈,该方法的生命结束,然后打印输出age,现今存在的age=20,所以打印的结果:20
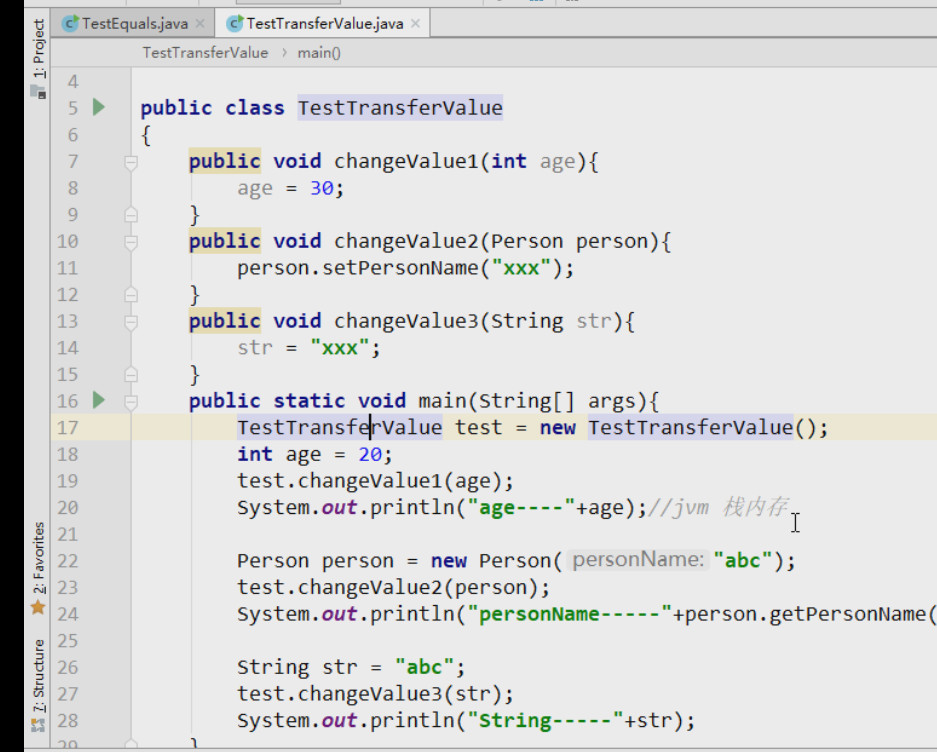
2.对于传递引用:
代码就向下走的话,那么调用test.changeValue2();如下图:
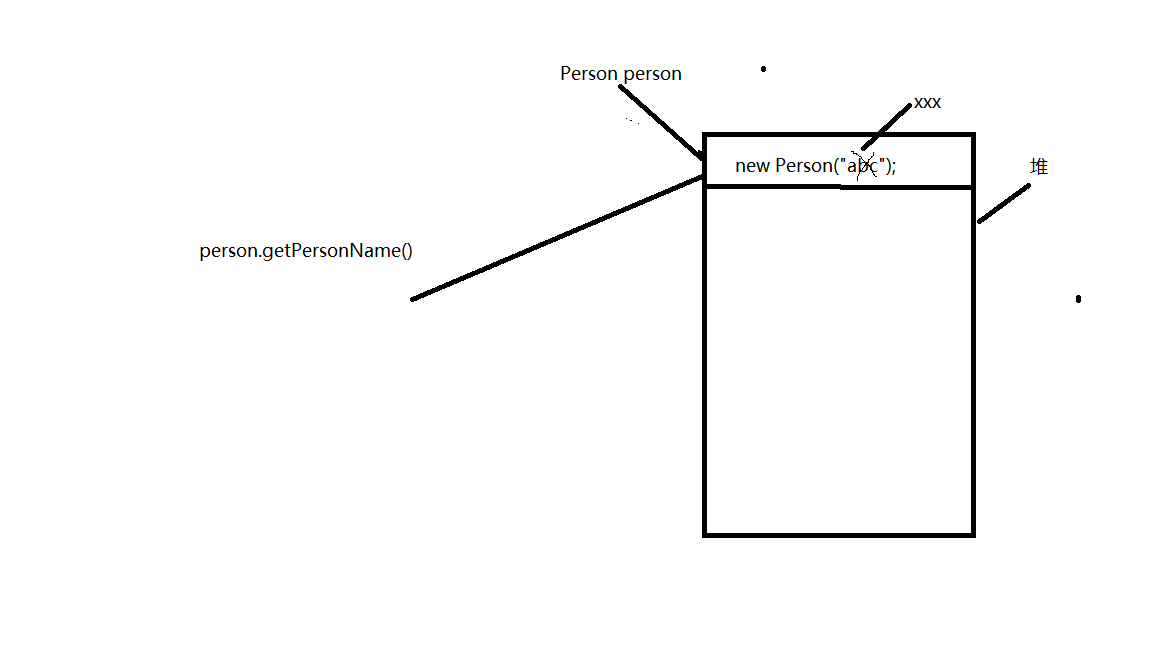
所以打印出:person.getPersonName():xxx
3.对于String来说的话,又是不一样,原因是String字符串的常量,public static final String str = "abc";
在常量的池中首先是要判断该字符串在常量池中是否已经存在,如果存在的话,那么就不在创建,将引用指向它就好,
如果在该常量池中不存在该字符串的常量,那么就要在该常量池中创建这个常量,所以当调用test.changeValue3();
判断“xxx”这个字符串在字符串的常量池中不存在的,那么就要创建字符串“xxx”,由于str仍然指向“abc”,所以
输出的结果仍然是"abc";
八、考察的是equals与==的区别,以及hashset的底层: