An edge creation history retrieval based method to predict links in social networks
关键词:在线社交网络;数据挖掘;图挖掘;链接预测(Online social networks; Data mining; Graph mining; Link prediction)
摘要:链接预测是一个图形挖掘任务,旨在预测非链接节点对在未来是否会连接。它在社交网络中有许多有用的应用,如朋友推荐、在合著网络中识别作者之间的未来合作、发现隐藏的恐怖分子和罪犯团体等。通常,最先进的链路预测方法考虑从网络的当前状态(即,最近和可用的快照)提取的拓扑数据。它们没有考虑描述现有边创建时网络拓扑结构的信息。因此,这些方法抓住机会忽略了可能影响旧边缘外观的环境信息,这可能有助于预测新边缘的创建。因此,本研究提出并评估了恢复这些数据可能有助于改善链路预测的假设。这一假设是合理的,因为这些数据通过实例丰富了应用程序上下文的描述,这些实例准确地表示了要预见的事件类型:新连接的创建。为此,本文提出了一种新的基于边生成历史检索的链接预测方法。通过对四个真实合著社交网络的二十个场景的实验,给出了统计证据,表明了所提出方法的有效性,并验证了所提出的假设。
1、介绍
下图就是所谓的链路预测
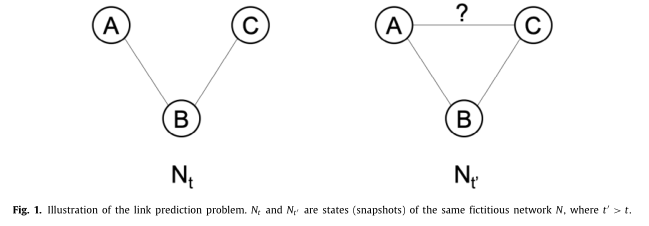
当最先进的无监督链路预测方法在网络的当前状态下计算非连接节点之间的相似度时,当信息每个现有的边(以前从未连接过的节点之间)都被添加到图中时它们不考虑描述网络的拓扑是如何形成的。因此,他们趁机忽略了实际上可能影响非连接节点之间连接的环境信息,而这些信息可能有助于预测新链路的激增。基于这一观察,目前的工作提出了以下假设:如果,现有的边缘被添加到过去的结构时,它考虑的信息描述了网络的状态时,无监督的链接预测可以得到改善。这个假设是合理的,因为考虑这样的信息可以用过去的例子来丰富链路预测输入数据,这些例子准确地描述了要预测的事件的类型:非连接节点之间的边缘的出现。这种丰富可以带来关于链接外观的见解,这些见解可以通过机器学习算法来学习。
因此,本文旨在验证提出的假设是否有效。为此,提出了一种基于历史信息检索的无监督链接预测方法,该方法描述了当表示两个节点之间的第一个连接的每个边被插入到图中时社交网络的拓扑。一旦检索到这种信息,就对其进行聚类,以便在超空间中找到包含拓扑相似元素(成对的连接节点)的区域,这些元素代表过去出现的连接(即现有的边)。聚类后,每对非连接节点被分配到其最相似的聚类。然后,所提出的方法计算这种对的节点之间的得分。分数计算中会考虑找到的集群和所有节点对的最终分配。所提出的方法的基本原理是,属于具有较高数量的过去连接的节点对的集群的非连接节点对在将来有更多的机会连接,因此,必须具有较高的分数。通过对四个不同合著网络的二十个场景的实验,给出了统计证据,表明了该方法的有效性,并验证了提出的假设。
2、背景
2.1 链路预测

已经提出了几项研究来预测社交网络中的链接[6,12]。总的来说,这些研究分为两种主要方法[13–15]:有监督和无监督。2在有监督的方法中,表示社交网络的原始图被转换为具有两类的分类问题:连接节点和非连接节点。然后用决策树或概率方法等算法建立分类模型。如前所述,无监督方法使用相似性函数来计算节点对之间的分数,然后基于递减的分数排名,选择前n对作为将来有更多机会连接的节点对。
虽然最先进的链接预测没有揭示哪种方法在社交网络中表现更好的常识,但与非监督方法相比,监督方法存在一个重要的缺点[15,16]。社交网络通常呈现高等级流行性(即,高度不平衡的等级分布,其中非连接节点对比连接节点对多得多),这可能导致有偏的分类模型。相反,不平衡的数据分布对于无监督链接预测方法来说不是问题。因此,在本文中,我们将重点关注这种方法。
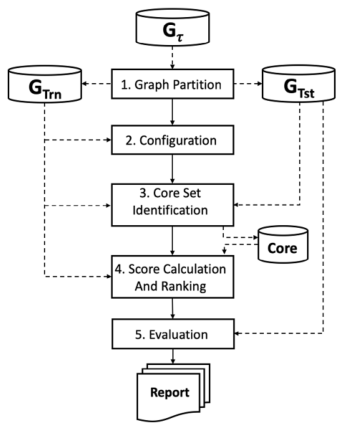
从无监督链接预测方法实验评估方法P的基本过程遵循[2]首先提出的任务序列。如图2所示,该过程包括以下阶段:


然后,将P的性能与基线随机链路预测器R的性能进行比较,基线随机链路预测器R简单地随机选择在训练间隔中没有交互的节点对。随机预测是正确的,概率表示为:
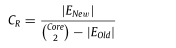
P相对于随机的改善因子计算如下(其中|ECorrect|是链路预测器正确预测的链路数量):
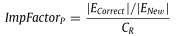

2.2 相关工作
监督方法包括基于上下文特征和/或与网络的节点和边缘相关的拓扑数据来构建分类或概率模型以预测新链接的方法
3、提出方法
设N是一个由同类多重图G(V,E)表示的社会网络,其中每个e ∈ E包含一个属性e.t,表示E加到N的时刻,设C是一个数据聚类算法,D = {di/di: V ×V → R}i=1,...,na相似性函数集和δ : Rm× Rm→ R a相似性度量。
本文提出的方法被称为基于边缘创建历史检索的链接预测器(简称H),它遵循图2所示的无监督链接预测方法的通常过程。在阶段4 -分数计算和排名中,h不同于其他无监督链接预测方法。图3和下一小节详细描述了这一阶段。表2提供了用于描述H及其实验的主要符号的概述。
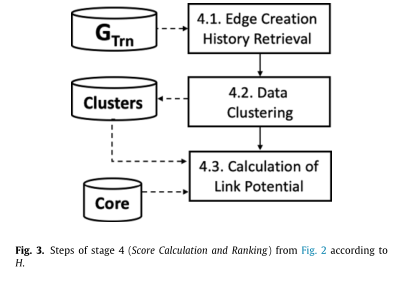

3.1 边缘创造历史检索
该步骤负责从GTrn(V,EOld)(训练子图-视图第2.1节)中检索拓扑数据,这些数据描述了非连接节点连接时的网络状态。为此,它首先确定 S
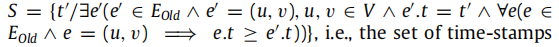 ,即对应于未连接节点之间的新边被添加到网络中的时刻的一组时间戳。
,即对应于未连接节点之间的新边被添加到网络中的时刻的一组时间戳。
它还确定了 ,即在连接先前未连接的节点的t′(t′∈S)处出现的 一组边。请注意,不同对的非连接节点可能在同一时间戳t’连接。Et‘包含代表这些连接的所有边。
,即在连接先前未连接的节点的t′(t′∈S)处出现的 一组边。请注意,不同对的非连接节点可能在同一时间戳t’连接。Et‘包含代表这些连接的所有边。
然后,对于每个时间戳t′∈s,该步骤检索子图Gtrn′(v,Eold′),其中∀a ∈ EOld,(a.t ≤ t′)→(a∈Eold′)。换句话说,当一条边(或一组边)出现时(即Gt′),GTrn' 包含在时刻t′的G′状态。
之后,对于每个Gt′和e∈Et′,该步骤将每个相似性函数从D应用到由e连接的节点u和v,产生具有以下结构的数据记录:(d1(u,v),d2(u,v)。。。,dn(u,v))。这样的数据记录总结了当u和v之间的连接被添加到结构中的时刻t’的网络拓扑。它代表了e的出现。
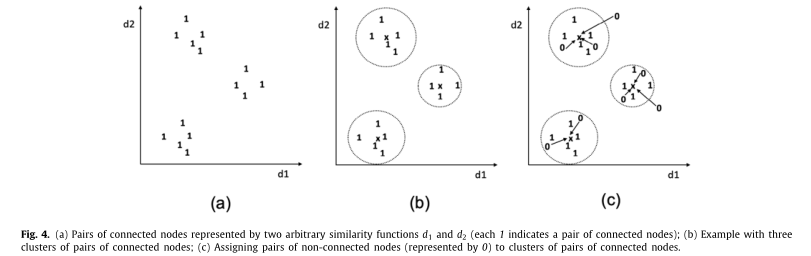
最后,该步骤输出数据集h(d1,d2,...dn),称为边创建历史。它包含关于G的拓扑的数据记录,这些数据记录表示当边被添加到G直到t’时的时刻。图4(a)示出了二维虚拟数据集h(d1,d2),其中d1和D2是任意相似性函数。每个点对应一个代表一对相连节点的数据记录。
3.2 数据簇
该步骤将数据聚类算法C应用于h(d1,d2,...,dn),以便识别一组群集{s1,s2,.。。}其中每个簇Sj包含代表网络演进期间出现的来自G的旧边缘的数据记录。每个Sj在超空间中划出一个区域,这个区域的特征是旧链接的创建。该区域的人口越多,边外观越具有代表性,并且图中出现的新边落在该聚类中的期望越高。
数据聚类步骤还计算并存储聚类中元素的数量,以便后续步骤可以使用它们来识别新边的外观。情商。(4)提供了任意聚类Sj中元素的归一化数量。|s|表示由簇s包围的数据记录数。

图4(b)示出了给定图4(a)中描述的数据集的数据聚类步骤的输出。它显示了三个球状星团和相应的质心,每个质心用一个x表示
3.3 计算连接可能性
最初,该步骤将相似性函数d ∈ D应用于来自GTrn(V,EOld)的所有非连接节点对。因此,对于每个非连接对(u,v),该步骤产生数据记录p=(d1(u,v),d2(u,v)。。。,dn(u,v)),因此p总结了在当前时间戳τ处关于节点u和v的网络拓扑。
此后,此步骤决定了p必须属于哪个群集。为此,它计算p和每个簇sk的质心。根据Eq。(5)然后,p被分配给聚类s,聚类s的p与其质心之间的相似度最高

图4(c)通过扩展图4(b)的示例来说明该过程。由0表示的点表示成对的非连接节点。每个箭头表示一个集群的配对分配
在下面的步骤中,该步骤通过等式计算每个非连接节点对的链接可能Score(u,v)。(6),其中:NormPop(s)是聚类s中元素的归一化数;QtdCN和QtdNCN分别是s中连通和非连通的节点对的数量;质心(s)是s的质心;δ(p,质心(s))是向量p和质心(s)之间的相似性度量。根据该等式,分配在具有较高数量的过去出现的边并且具有比未连接的节点更多的连接的区域中的未连接的节点对获得较高的分数,这表明在未来变得连接的可能性较高。这个等式也有利于节点对与其集群具有更高的兼容性。与聚类质心更相似的对得分更高。

在对所有非连接的节点对进行分数计算后,这些节点对按分数降序排列。
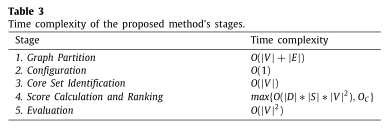
3.4 复杂性分析
4、实验
5、结论和今后的工作
社交网络分析中最相关的问题之一包括预测两个不连接的节点是否很快会连接。通常,大多数现有的链路预测方法应用相似性函数来描述所分析的网络的当前状态的拓扑。因此,这些方法不考虑在将旧边添加到结构中时代表网络拓扑的信息。面对这种情况,本文提出了一个假设,即检索这种信息可以用样本丰富数据,说明要预见的事件类型:新边缘的出现。这种丰富可能导致链接预测模型比最先进的模型更精确。
为了调查提出的假设是否有效,我们提出并评估了一种链接预测方法(H),这是本文的主要贡献。它通过相似性函数检索描述当现有边出现在结构中时网络拓扑的信息。四个社交网络的实验结果提供了统计证据,表明与不检索此类信息的方法相比,H增强了无监督链接预测,从而证实了提出的假设。我们还运行了一组实验,将H与[15]中提出的主要方法进行比较,相关工作与我们最相似。总的来说,从这组实验中获得的结果表明,我们在链路预测中处理时间维度的方法比[15]中提出的方法产生了更好的结果。
我们未来的工作包括以下举措:在合作作者身份的背景下对社交网络进行实验,使用其他相似性函数和度量标准,探索基于密度的数据聚类算法(以便生成具有不同形状的聚类),检测和处理异常值,将社区检测方法(例如[50]中描述的方法)与我们的链接预测方法相结合,研究监督链接预测方法中提出的假设(包括用不同方法处理类别流行度的实验), 处理新节点的出现,搜索最大化H性能的训练间隔,监控H的性能以建议何时重新运行数据聚类步骤,评估与连接节点相关的拓扑变化如何损害H在非实验场景中的性能,等等。