一、数据特征提取
1、安装依赖库
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple Scikit-learn 注意:安装Scikit-learn前需先安装numpy和pandas
2、字典特征数据抽取
from sklearn.feature_extraction import DictVectorizer data = [{"name":"nick","age":12},{"name":"mile",'age':23},{'name':'jack','age':34}] def dictvec(): #将sparse设置为false,返回数组数据而不是sparse矩阵 dict = DictVectorizer(sparse=False) tans_data = dict.fit_transform(data) print(dict.feature_names_) print(tans_data) if __name__ == "__main__": dictvec()
返回的数据集采用one-hot编码形式
['age', 'name=jack', 'name=mile', 'name=nick'] [[12. 0. 0. 1.] #001表示nick [23. 0. 1. 0.] [34. 1. 0. 0.]]
3、文本特征抽取以及中文问题
from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer import jieba def cutword(): text1 = "床前明月光,疑是地上霜" text2 = "一二三四五,上山打老虎" cut_text1 = jieba.cut(text1) cut_text2 = jieba.cut(text2) l1 = list(cut_text1) l2 = list(cut_text2) return [" ".join(l1)," ".join(l2)] if __name__ == "__main__": countvac = TfidfVectorizer(); trans_data = countvac.fit_transform(cutword()) print(countvac.get_feature_names()) print(trans_data.toarray())
说明:
1.文本特征抽取函数没有sparse的参数,所以可自己转化为数组
trans_data.toarray()
2.由于中文文本单词之间没有间隔,所以需要借助分词库jieba来将文本分词
3.使用TfidfVectorizer可以抽取重要性高的词
返回结果:
['一二三四五', '上山', '地上', '床前', '明月光', '疑是', '老虎'] [[0. 0. 0.5 0.5 0.5 0.5 0. ] [0.57735027 0.57735027 0. 0. 0. 0. 0.57735027]]
二、数据特征预处理
特征处理:通过特定的统计方法(数学方法),将数据转换成算法需要的数据
预处理用到的库:sklearn.preprocessing
1、归一化
把数据变成(0,1)或者(1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
目的:使得某一特征值对最终结果不会造成更大影响。
公式:
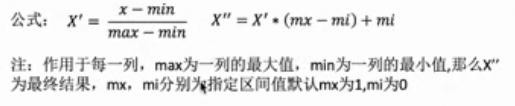
代码:
from sklearn.preprocessing import MinMaxScaler, StandardScaler def guiYiHua(): data = [[12., 0., 0., 1.], [23., 0., 1., 0.], [34., 1., 0., 0.]] minmaxScaler = MinMaxScaler() trans_data = minmaxScaler.fit_transform(data) print(trans_data) return None if __name__ == "__main__": guiYiHua()
返回:
[[0. 0. 0. 1. ] [0.5 0. 1. 0. ] [1. 1. 0. 0. ]]
2、标准化

在机器学习中,我们可能要处理不同种类的资料,例如,音讯和图片上的像素值,这些资料可能是高维度的,资料标准化后会使每个特征中的数值平均变为0(将每个特征的值都减掉原始资料中该特征的平均)、标准差变为1,这个方法被广泛的使用在许多机器学习算法中(例如:支持向量机、逻辑回归和类神经网络)。
代码:
def biaoZhunHua(): data = [[12., 0., 0., 1.], [23., 0., 1., 0.], [34., 1., 0., 0.]] standardScaler = StandardScaler() trans_data = standardScaler.fit_transform(data) print(trans_data) return None if __name__ == "__main__": biaoZhunHua()
返回:
[[-1.22474487 -0.70710678 -0.70710678 1.41421356] [ 0. -0.70710678 1.41421356 -0.70710678] [ 1.22474487 1.41421356 -0.70710678 -0.70710678]] #每列相加平均值为0
3、结合归一化和标准化总结
为什么要归一化/标准化?
如前文所说,归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。比如有一个很重要的性质:线性变换不会改变原始数据的数值排序。
如前文所说,归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。比如有一个很重要的性质:线性变换不会改变原始数据的数值排序。
区别:
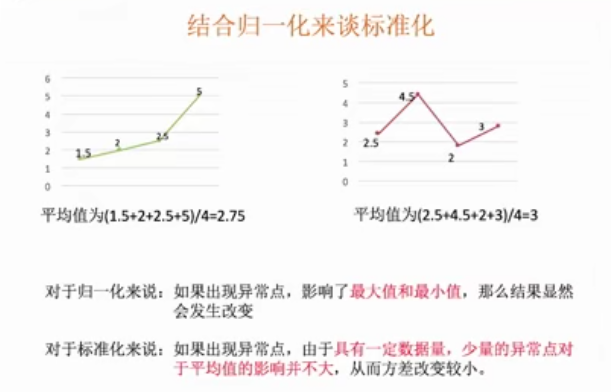
4、缺失值插补

代码:
import numpy as np from numpy import nan as NA from sklearn.impute import SimpleImputer #axis默认为0,即按列填充 imputer = SimpleImputer(missing_values=NA, strategy = "mean") data = [[12., 0., 0., NA], [23., 0., 1., 0.], [34., 1., 0., 0.]] trans_data = imputer.fit_transform(data) print(trans_data)
说明:安装了最新版的sklearn,发现在preprocessing里没有Imputer函数,最后的解决方法是调用imputer里面的SimpleImputer函数。
三、数据降维
1、特征抽取

代码:
from sklearn.feature_selection import VarianceThreshold def feaSel(): data = [ [0,2,0,3], [0,1,4,3], [0,1,1,3] ] #threshold控制低方差值 var = VarianceThreshold(threshold=0.0) trans_data = var.fit_transform(data) print(trans_data) return None if __name__ == "__main__": feaSel()
返回:
[[2 0] [1 4] [1 1]]
2、主成分分析

n_components
- 意义:PCA算法中所要保留的主成分个数n,也即保留下来的特征个数。也可以是设置解释变量的比例。[6]如:
pca =PCA(n_components=0.98) - 类型:int或者string,缺省时默认为None,所有成分保留。赋值为int,比如n_components=1,将把原始数据降到一个维度。赋值为string,比如n_components='mle',将自动选取特征个数n,使得满足所要求的方差百分比。
代码:
from sklearn.decomposition import PCA def pcaFun(): data = [ [2,8,4,5], [6,3,0,8], [5,4,9,1] ] pca = PCA(n_components=0.9) trans_data = pca.fit_transform(data) print(trans_data) return None if __name__ == "__main__": pcaFun()
返回:
[[ 1.28620952e-15 3.82970843e+00] [ 5.74456265e+00 -1.91485422e+00] [-5.74456265e+00 -1.91485422e+00]]