一、概述
zookeeper主要分为:文件系统和通知机制。
Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储, Zookeeper 作用主要是用来维护和监控存储的数据的状态变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理。由于工程师不能很好地使用锁机制,以及基于消息的协调 机制不适合在某些应用中使用,因此需要有一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。
二、元素介绍
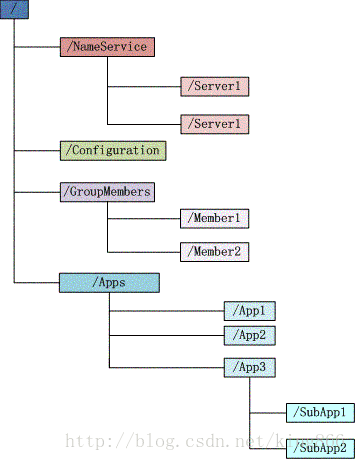
1、znode节点
有四种类型的znode:
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、 PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
2、NameService 命名服务
这个似乎最简单,在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现
这个主要是作为分布式命名服务,通过调用zk的create node api,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
3、configuration 配置管理
现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
4、GroupMembers 集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道了。新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了。
对于第二点,所有机器创建临时顺序编号目录节点,通过master选举算法选举出来。
三、使用场景
ZooKeeper是一个高可用的分布式数据管理与系统协调框架。基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基 于这样的特性,使得zookeeper能够应用于很多场景。
数据发布与订阅
发布与订阅即所谓的配置管理,顾名思义就是将数据发布到zk节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,地址列表等就非常适合使用。
1. 索引信息和集群中机器节点状态存放在zk的一些指定节点,供各个客户端订阅使用。
2. 系统日志(经过处理后的)存储,这些日志通常2-3天后被清除。
3. 应用中用到的一些配置信息集中管理,在应用启动的时候主动来获取一次,并且在节点上注册一个Watcher,以后每次配置有更新,实时通知到应用,获取最新配置信息。
4. 业务逻辑中需要用到的一些全局变量,比如一些消息中间件的消息队列通常有个offset,这个offset存放在zk上,这样集群中每个发送者都能知道当前的发送进度。
5. 系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息。以前通常是暴露出接口,例如JMX接口,有了zk后,只要将这些信息存放到zk节点上即可。
分布通知/协调
ZooKeeper 中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对 ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能 够收到通知,并作出相应处理。
1. 另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。
2. 另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改 了ZK上某些节点的状态,而zk就把这些变化通知给他们注册Watcher的客户端,即推送系统,于是,作出相应的推送任务。
3. 另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到zk来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。
总之,使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合。
分布式锁
分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性,即用户只要完全相信每时每刻,zk集群中任意节点(一个zk server)上的相同znode的数据是一定是相同的。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
基于ZooKeeper分布式锁的流程:
0:保证锁根节点存在,若不存在则创建它
1:在zookeeper指定节点(locks)下创建临时顺序节点node_n
2:获取locks下所有子节点children
3:对子节点按节点自增序号从小到大排序
4:判断本节点是不是第一个子节点,若是,则获取锁;若不是,则监听比该节点小的那个节点的删除事件
5:若监听事件生效,则回到第二步重新进行判断,直到获取到锁
通过实现Watch接口,实现process(WatchedEvent event)方法来实施监控,使CountDownLatch来完成监控,在等待锁的时候使用CountDownLatch来计数,等到后进行countDown,停止等待,继续运行。
WatchEvent有三种类型:NodeDataChanged、NodeDeleted和NodeChildrenChanged。
调用setData()时会触发NodeDataChanged;
调用create()时会触发NodeDataChanged和NodeChildrenChanged;
调用delete()时上述三种event都会触发。
//stat为node的状态结构
Stat stat = zk.exists(LOCK_ROOT, false); if (stat == null) { zk.create(LOCK_ROOT, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); }
//创建时序持久节点 lockId = zk.create(LOCK_ROOT + "/", data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 获得锁根节点下的各锁子节点,并排序 List<String> nodes = zk.getChildren(LOCK_ROOT, true); SortedSet<String> sortedNode = new TreeSet<String>(); for (String node : nodes) { sortedNode.add(LOCK_ROOT + "/" + node); } String first = sortedNode.first();
//选出比lockId小的节点 SortedSet<String> lessThanMe = sortedNode.headSet(lockId); //-------------------------------------------------------------- // 检查是否有比当前锁节点lockId更小的节点,若有则监控当前节点的前一节点 //-------------------------------------------------------------- if (lockId.equals(first)) { System.out.println("thread " + Thread.currentThread().getName() + " has get the lock, lockId is " + lockId); return true; } else if (!lessThanMe.isEmpty()) { String prevLockId = lessThanMe.last(); zk.exists(prevLockId, new LockWatcher()); //-------------------------------------------------------------- // 阀门等待sessionTimeout的时间 // 当等待sessionTimeout的时间过后,上一个lock的Zookeeper连接会过期,删除所有临时节点,触发监听器 ,执行process方法将闭锁cutDown放开锁获取机会。此时当前节点就是最小的节点了,所以会获得锁 //await()等待计数器到0,(也就是等待持有锁的线程执行cutDown操作),直到超时。
latch.await(sessionTimeout, TimeUnit.MILLISECONDS); System.out.println("thread " + Thread.currentThread().getName() + " has get the lock, lockId is " + lockId); }
class LockWatcher implements Watcher { @Override public void process(WatchedEvent event) { //-------------------------------------------------------------- // 监控节点变化(本程序为序列的上一节点) // 若为节点删除,证明序列的上一节点已删除,此时释放阀门让当前的lock获得锁 //-------------------------------------------------------------- if (event.getType() == Event.EventType.NodeDeleted) latch.countDown(); } }
public void unlock() { try { System.out.println("释放锁 " + CURRENT_LOCK); zk.delete(CURRENT_LOCK, -1); CURRENT_LOCK = null; zk.close(); } catch (InterruptedException e) { e.printStackTrace(); } catch (KeeperException e) { e.printStackTrace(); } }
集群管理
1. 集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。 这种做法可行,但是存在两个比较明显的问题:1. 集群中机器有变动的时候,牵连修改的东西比较多。2. 有一定的延时。
利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统:a. 客户端在节点 x 上注册一个Watcher,那么如果 x 的子节点变化了,会通知该客户端。b. 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
2. Master选举则是zookeeper中最为经典的使用场景了。
在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行, 其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。
利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。