字符串:
字符串表示两种方式:
1)" "双引号 可以包含控制字符
2)`` 反引号 所有字符都是原样输出
字符串的常用操作:
长度:len(str)
拼接:+ , fmt.Sprintf()
分割:strings.Split()
包含:strings.Contains()
前缀或后缀判断:strings.HasPrefix, strings.HasSuffix
子串出现的位置:strings.Index(), strings.LastIndex()
join操作:strings.Join(a[ ]string,sep string)
字符串索引比较常用的有如下几种方法:
- strings.Index:正向搜索子字符串。
- strings.LastIndex:反向搜索子字符串。
- 搜索的起始位置可以通过切片偏移制作。
tracer := "死神来了, 死神bye bye"
comma := strings.Index(tracer, ", ")
pos := strings.Index(tracer[comma:], "死神")
fmt.Println(comma, pos, tracer[comma+pos:])
- Go 语言的字符串是不可变的。
- 修改字符串时,可以将字符串转换为 []byte 进行修改。
- []byte 和 string 可以通过强制类型转换互转。
angel := "Heros never die"
angleBytes := []byte(angel)
for i := 5; i <= 10; i++ {
angleBytes[i] = ' '
}
fmt.Println(string(angleBytes))
bytes.Buffer 是可以缓冲并可以往里面写入各种字节数组的。字符串也是一种字节数组,使用 WriteString() 方法进行写入。
将需要连接的字符串,通过调用 WriteString() 方法,写入 stringBuilder 中,然后再通过 stringBuilder.String() 方法将缓冲转换为字符串。
hammer := "吃我一锤"
sickle := "死吧"
// 声明字节缓冲
var stringBuilder bytes.Buffer
// 把字符串写入缓冲
stringBuilder.WriteString(hammer)
stringBuilder.WriteString(sickle)
// 将缓冲以字符串形式输出
fmt.Println(stringBuilder.String())
Go 语言的字符有以下两种:
- 一种是 uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。
- 另一种是 rune 类型,代表一个 UTF-8 字符。当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型实际是一个 int32。
var a byte = 'a'
fmt.Printf("%d %T
", a, a)
var b rune = '你'
fmt.Printf("%d %T
", b, b)
可以发现,byte 类型的 a 变量,实际类型是 uint8,其值为 'a',对应的 ASCII 编码为 97。
rune 类型的 b 变量的实际类型是 int32,对应的 Unicode 码就是 20320。
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
str := "hello "
fmt.Printf("len:%d
", len(str))
fmt.Println(utf8.RuneCountInString("忍者"))
fmt.Println(utf8.RuneCountInString("龙忍出鞘,fight!")) //计算UTF-8的字符个数。
str2 := str +"world"
fmt.Printf("str2:%s
", str2)
str3 := "the,character,represented,by,the corresponding Unicode code point"
result := strings.Split(str3, ",")
fmt.Printf("result:%v
", result) //数组的格式
str4 := strings.Join(result, ",")
fmt.Printf("str5:%s
", str4)
isContain := strings.Contains(str3, "represented33") //返回布尔值
fmt.Printf("contain:%t
", isContain)
str5 := "baidu.com"
index := strings.Index(str5, "du")
fmt.Printf("index:%d
", index)
if ret := strings.HasPrefix(str4, "http://"); ret == false {
str4 = "http://" +str4
}
fmt.Printf("str4:%s
", str4)
数组类型
1、定义
var 变量名 [len]type
2、举例
var a [5]int
var a [5]string
var a [5]float32
var a [15]bool
3、使用下标访问,比如:a[0]访问第一个元素
4、数组的内存布局是连续的内存布局
package main import( "fmt" ) func main() { var a [25]int8 length := len(a) for i := 0; i < length; i++ { fmt.Printf("%p ", &a[i])//打印内存地址 } }
5、数组的长度
var a [10]int
length :=len(a)
6、数组遍历
下标遍历
for……range
package main import( "fmt" ) func main() { var a [25]int8 for index, value := range a { fmt.Printf("a[%d]=%d ", index, value) } }
7、数组也是指类型
package main import( "fmt" ) func test2() { var a [5] int = [5]int {1,2,3,4,5} var b [5] int b = a fmt.Printf("b=%v ", b) b[0] = 200 fmt.Printf("b=%v ", b) fmt.Printf("a=%v ", a) }
8、初始化
var a [5] int = [5]int{1,2,3,4,5}
var a = [5]int{1,2,3,4,5}
var a = [5]int{1,2,3}
var a = [...]int{1,2,3,4,5}
var a = [5]string{1:'abc',4:'efg'}


package main import( "fmt" ) func main() { var a [5] int = [5]int{1,2,3,4,5} fmt.Printf("%v ", a) var b = [...]int{1,3,4,5,7, 8} fmt.Printf("%v ", b) var c = [5]int{1,3,4} fmt.Printf("%v ", c) var d [5]string = [5]string{1:"abc", 4:"efg"} fmt.Printf("%#v ", d) }
9、二维数组
var a[8][2]int
package main import( "fmt" ) func main() { var a [4][2]int for i := 0; i < 4; i++ { for j := 0; j < 2; j++ { a[i][j] = (i+1)*(j+1) } } for i := 0; i < 4; i++ { for j := 0; j < 2; j++ { fmt.Printf("%d ", a[i][j]) } fmt.Println() } }
练习:
- 写 一个程序, 生成100个随机数,并存放到数组中。最后把数组打印到屏幕上。
-
写 一个程序,随机生成100个字符串,并存放到数组中。最后输出到屏幕上。
package main import( "fmt" "math/rand" ) func mian() { var a [100]int for i := 0; i < len(a); i++ { //赋值 a[i] = rand.Int() } for i := 0; i < len(a); i++ { //取下标=i的元素的值 fmt.Printf("%d ", a[i]) } }
package main import( "fmt" "math/rand" ) func main() { var a [100]string var b string = "0123456789我爱中国" //var runeArr = []rune(b) for i := 0; i < len(a); i++ { var str string for j := 0; j < 4; j++ { index := rand.Intn(len(b)) //格式化并返回格式化后的字符串 str = fmt.Sprintf("%s%c", str, b[index]) //%c 相应Unicode码点所表示的字符 } a[i] = str fmt.Printf("a[%d]=%s ", i, a[i]) } }
切片类型
1、定义
var 变量名 []type
举例:
var a []int
var a []string
var a []float32
var a []bool
默认值, a的长度等于0
2、切片初始化
var a [5]int
var b[]int= a[0:2]
举例:数组的下标没有负数
var a [5]int
var b []int = a[0:1]
var b []int = a[0:5]
var b []int = a[0:]
var b []int = a[:3]
var b []int = a[:]
var b []int= []int{1,2,3,4,5}
3、遍历
下标遍历
for … range
练习:
1、
var a [5]int var b = a[1:3] a[0] = 100 a[1] = 200 b[0] = ? b[1] = ?
2、
var a [5]int
var b = a[1:3]
b[0] = 100
b[1] = 200
a[0] = ?
a[1] = ?
package main import( "fmt" ) func test1(){ var a [5]int b := a[1:3] a[0] = 100 a[1] = 200 fmt.Printf("b:%#v ", b) } func test2(){ var a [5]int b := a[1:3] b[0] = 100 b[1] = 200 fmt.Printf("b:%#v ", a) } func main(){ test1() test2() }
4、切片的内存布局(引用类型数据)
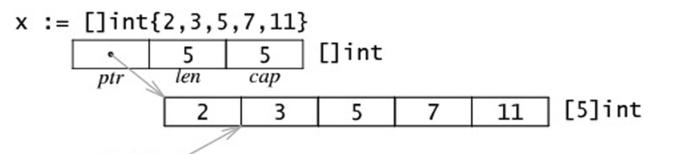
5、切片的好处
package main import( "fmt" ) func Sum(b []int) int { var sum int for i := 0; i < len(b); i++ { sum = sum + b[i] } b[0] = 100 return sum } //传数组求和,数组容量变化,就得修改代码,代码重用性差,所以一般传切片进行操作
func SumArray(b [100]int) int { var sum int for i := 0; i < len(b); i++ { sum = sum + b[i] } b[0] = 100 return sum } func main(){ var a [100]int = [100]int{1,2,3,4,5} //result := Sum(a[:]) result := SumArray(a)
fmt.Printf("sum=%d ", result) fmt.Printf("a:%#v ", a) }
6、切片的创建
make([]type, len, cap)
make([]type, len) 不指定容量,容量就是切片长度
var b []int
b = make([]int, 5, 10) 底层是数组
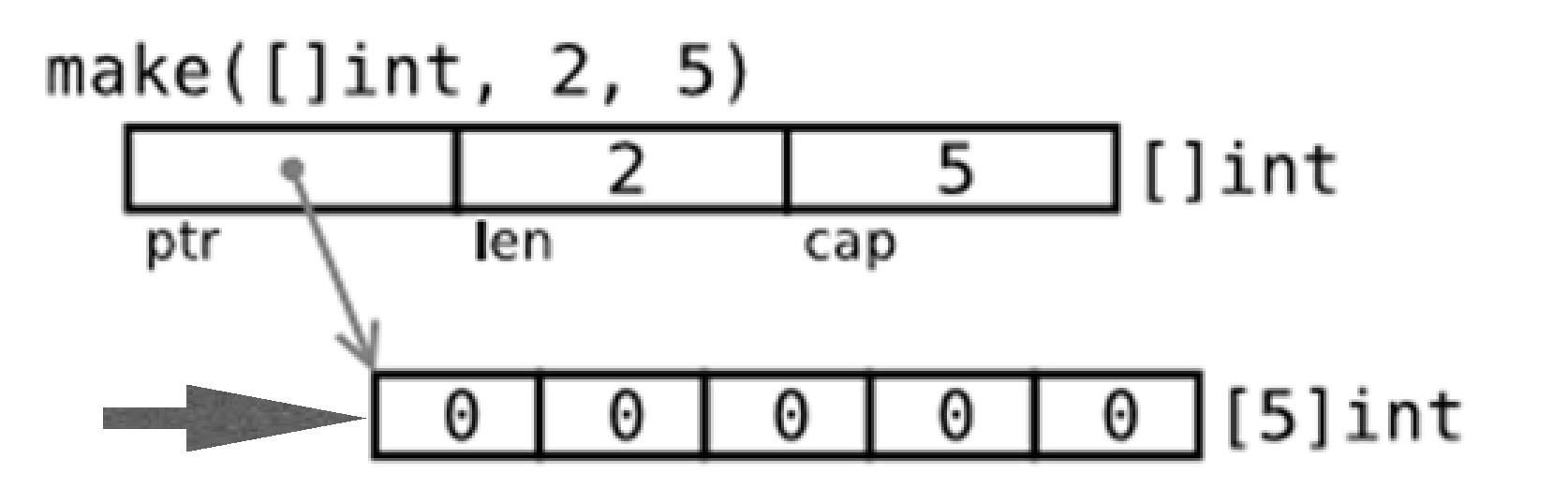
参数len和cap的理理解
package main import( "fmt" ) func testSliceCap() { a := make([]int, 5, 10) a[4] = 100 b := a[1:3] fmt.Printf("a=%#v, len(a) = %d, cap(a)=%d ", a, len(a), cap(a)) fmt.Printf("b=%#v, len(b) = %d, cap(b)=%d ", b, len(b), cap(b)) }
内置函数, cap和len
var ar = [10]int{0,1,2,3,4,5,6,7,8,9} b = ar[5:7] b的各个元素的以及值长度和容量分别是多少? //{5.6} 5 b = ar[0:4] b的各个元素的值以及长度和容量分别是多少 //{0,1,2,3} 6
reslice, 在切 片的基础上再切片,用来扩容和缩容
package main import "fmt" func main() { var a []int = make([]int, 5, 10) a[4] = 100 b := a[0:10] b[9] = 100 fmt.Printf("%v", a) fmt.Printf("%v", b) }
7、切 片copy和append操作
copy
package main import "fmt" func main() { sl := []int{1,2,3} s2 := make([]int, 10) copy(s2, s1) }
append(切片扩容)
package main import( "fmt" ) func main() { var a []int a = make([]int, 5) var b []int = []int{10,11,12,13,14}
//a = append(a,10,11,12,13,14)
a = append(a, b...) //b...切片的解压
fmt.Printf("a:%#v ", a) }
package main import ( "fmt" ) func main() { var a []int = make([]int, 10) var b [10]int = [10]int{1, 2, 3, 8: 100} a = b[:] a = append(a, 10, 30, 40) fmt.Println(a) a[0] = 2000 fmt.Println(b) fmt.Println(a) //切片虽然是值引用类型,但是扩容后切片指向的地址发生了变化,不再指向原来的数组,而是另拷贝了一份。 /* [1 2 3 0 0 0 0 0 100 0 10 30 40] [1 2 3 0 0 0 0 0 100 0] [2000 2 3 0 0 0 0 0 100 0 10 30 40] */ }
8、字符串的内存布局
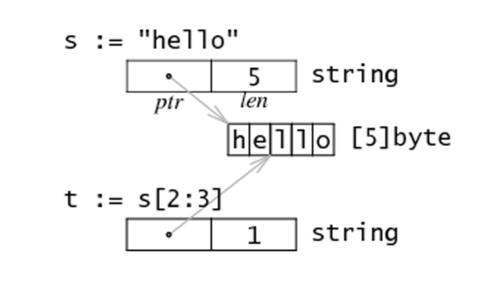
底层是用切片实现的
//字符串的替换
package main import( "fmt" ) //字符串的额替换 func main() { var str = "hello world" var b []byte = []byte(str) b[0] = 'a' str1 := string(b) fmt.Printf("str1:%s, %d ", str1, len(str)) }
//字符串的反序
package main import( "fmt" ) func main() string{ str := "hello world" b := []byte(str) //以字节为单位的切片
for i := 0; i < len(b)/2;i++ { b[i], b[len(b)-i-1] = b[len(b)-i-1], b[i] } str1 := string(b) fmt.Println(str1) }
package main import( "fmt" ) func main() string{ str := "hello world我们爱中国" b := []rune(str) //以字符为单位切片
for i := 0; i < len(b)/2;i++ { b[i], b[len(b)-i-1] = b[len(b)-i-1], b[i] } str1 := string(b) fmt.Println(str1) fmt.Printf("len(str)=%d, len(rune)=%d ", len(str), len(b))
}
数组、切片排序和查找操作
排序操作主要都在 sort包中,导入就可以使用了
import(“sort”)
sort.Ints对整数进 行行排序, sort.Strings对字符串串进 行行排序, sort.Float64s对浮点数进 行行排序
sort.SearchInts(a []int, b int) 从数组a中查找b,前提是a必须有序
sort.SearchFloats(a []float64, b float64) 从数组a中查找b,前提是a必须
sort.SearchFloats(a []float64, b float64) 从数组a中查找b,前提是a必须有序
sort.SearchStrings(a []string, b string) 从数组a中查找b,前提是a必须有序
map
1. map简介
key-value的数据结构, 又叫字典或关联数组
a.声明
var map1 map[keytype]valuetype
var a map[string]string
var a map[string]int 声明是不会分配内存的,初始化需要make
var a map[int]string
var a map[string]map[string]string
2、map相关操作
初始化:var a map[string]string = map[string]string{"hello":"world"}
初始化:a = make(map[string]string, 10)
a["hello"] = "world" 插入和更新
Val, ok:= a[“hello”] 查找
for k, v := range a { 遍历
fmt.Println(k,v)
}
delete(a, “hello”) 删除
len(a) 长度
View Code3、map是引用类型
func modify(a map[string]int) {
a[“one”] = 134
}
4、 slice of map
func testMapSlice(){
s := make([]map[string]int, 10) //map切片的初始化
for i := 0;i <len(s); i++{
s[i] = make(map[string]int, 100) //map的初始化
}
s[0]["abc"] = 100
s[5]["abc"] = 100
fmt.Println(s)
}
func main(){
testMapSlice()
}
5、map排序
a.先获取所有key,把key进行排序
b.按照排序好的key,进行遍历
6、Map反转
a. 初始化另外一个map,把key、value互换即可