一、程序结构分析
1、第一次作业
(1)类图
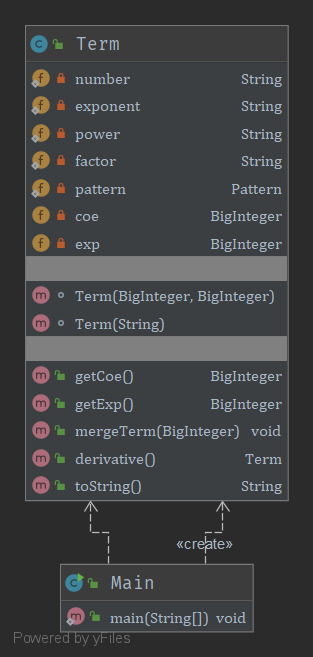
第一次作业大致思路是,用Term类存储幂函数和求导,再用ArrayList存储Term对象。由于需求简单,我在设计和编写时也就没有考虑迭代需求,最后把所有代码塞进了Main和Term两个类中,让主类起到了多项式类的作用。第一次作业的设计是比较失败的,虽然能解决当时的需求,但几乎没有任何可迭代性,一旦添加新东西就要重新设计架构;代码的层次化结构也不好,大量的方法集中在一个类中,完全可以将一些方法提取到一个新的类。
(2)复杂度分析
方法复杂度如下:
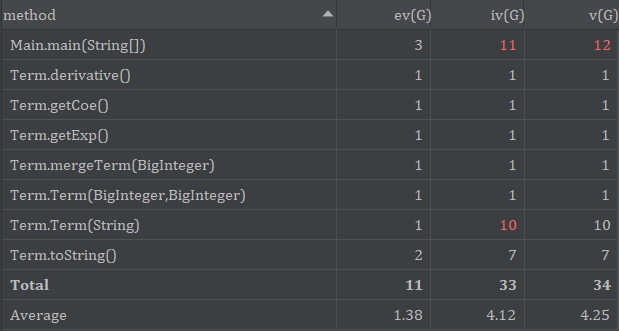
main方法和Term类构造方法过于复杂,前者是因为架构设计不好,大量代码集中在主函数中;后者是在处理“+/-”符号时过于依赖if-else,导致分支过多。
类复杂度如下:
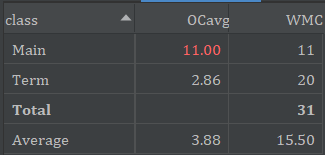
主要问题还是main函数过于复杂。
2、第二次作业
(1)类图

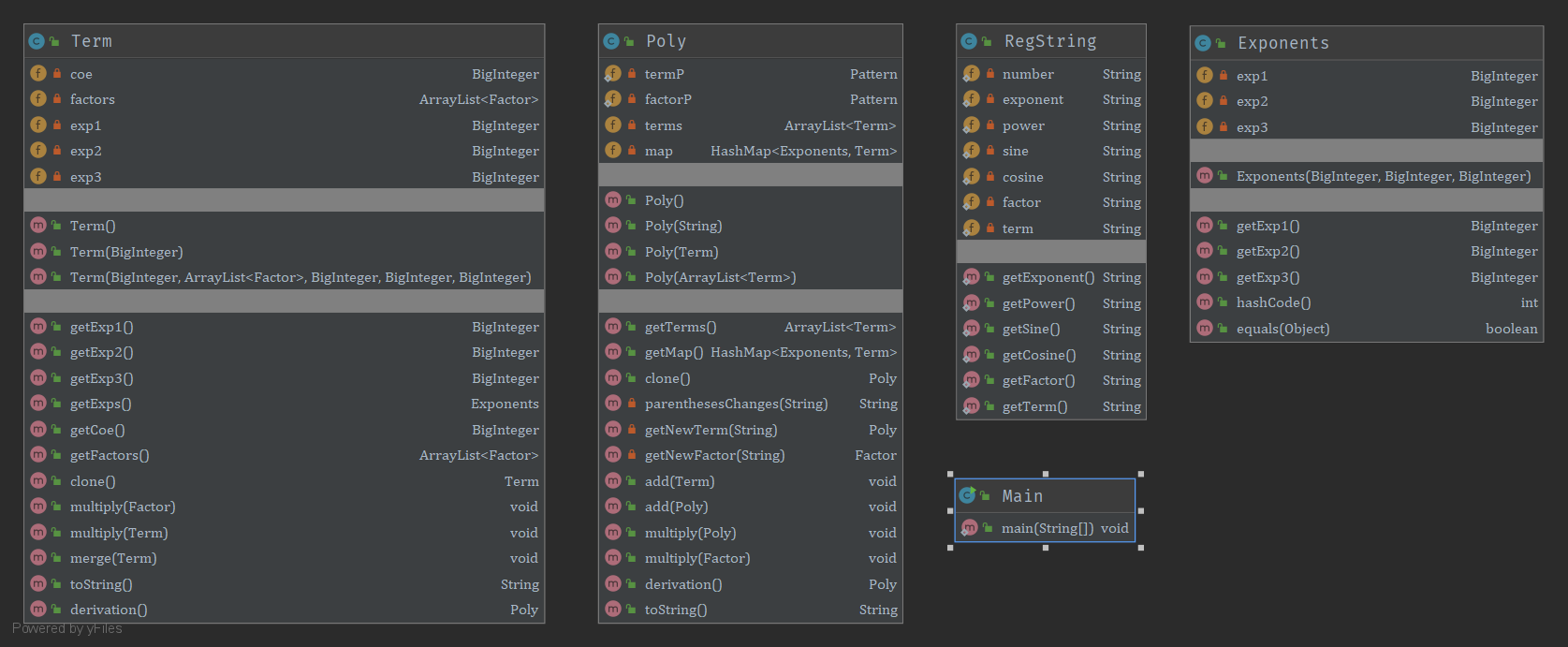
第二次作业的设计吸取了第一次作业的教训,设计架构时考虑到了第三次作业的三角函数的嵌套。大致的设计架构是:多项式类存储多个项对象,项类存储多个因子对象,因子类有多个子类,各自设计不同的toString方法和求导方法;由于存在表达式的嵌套,为了让正则表达式能正确地捕获,每次输入的表达式会进行处理,将最外层的括号替换成方括号保证括号能正确地匹配。此架构的设计优点在于思路清晰,输入的字符串会通过多项式、项、因子逐层解析,得到表达式;可拓展性良好,各个ToString方法和求导方法只需处理自己的数据,并调用下一层的方法,如果要添加新的因子类型,只需要继承Factor类并设计自己的ToString方法和求导方法即可。
不过我第二次作业最终的实现也有很大的问题。由于我设计架构时考虑了迭代问题,设计了三角函数的嵌套,但第二次作业三角函数内部只能为x,我在处理表达式时也将表达式因子乘开了,所以项其实可以用四个BigInteger对象表示出来(系数和x、sin(x)、cos(x)的指数),处理时会方便。于是我既保留了为第三次作业预留的设计,又添加了为简化第二次作业做的设计,两者混杂在一起,造成代码冗长;另外,我在实现架构时图一时的方便,将逐级解析表达式的几个方法集中在了Poly一个类里,虽然没有导致bug的出现,但也让Poly类显得十分臃肿,后期debug时也带来了一些麻烦。
(2)复杂度分析
方法复杂度如下(只挑选了较复杂的方法):

Term类的multiply方法主要是第二次作业和第三次作业的设计混杂在一起,导致方法过于复杂;Poly类的toString方法主要是为了输出能最短,做了许多优化和判断;其他方法主要是过于依赖if-else。
类复杂度如下:
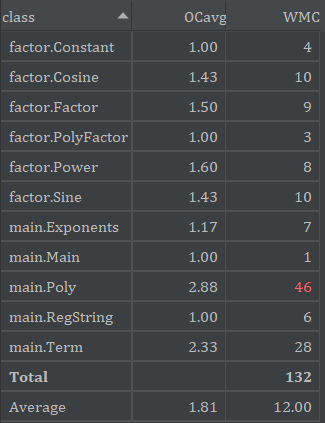
主要是Poly类过于复杂,原因也在前面提到过。
3、第三次作业
(1)类图
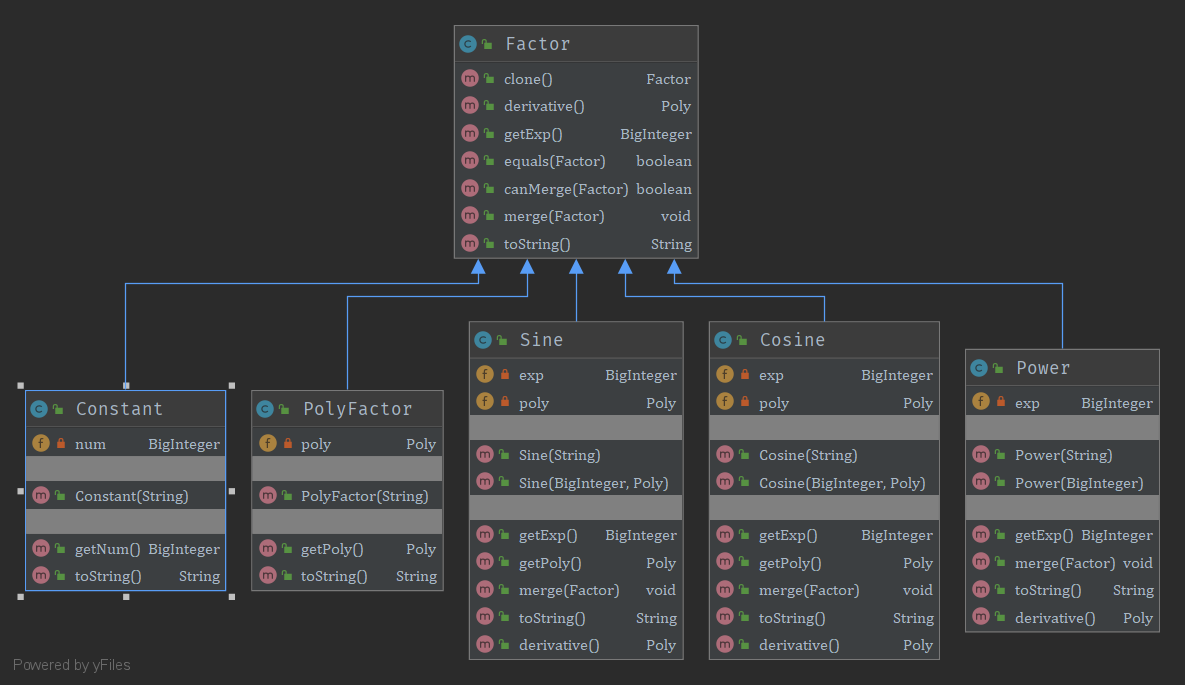
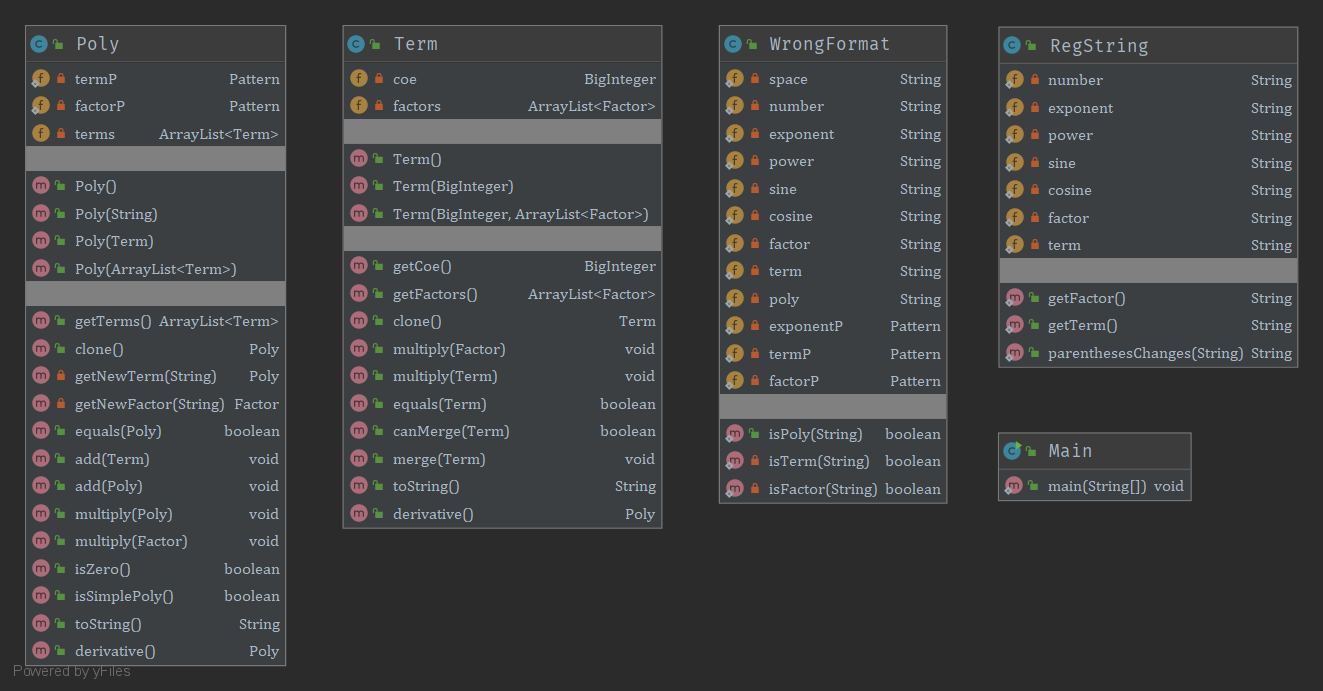
第三次作业新增的内容主要是格式正确性检查和三角函数的嵌套,后者我在第二次作业设计时就已经考虑到并基本实现了,所以此次作业我只需添加一个WrongFormat类用于格式检查即可。格式检查的过程其实和表达式解析过程基本一致,只不过解析过程可以提前取出所有空白符,便于后续处理,格式检查时加上空白符即可。另外,由于第三次作业的数据限制更严格,一些本来可能导致TLE的优化方法可以在本次作业放心使用,所以我设计了表达式、项、因子的比较方法和合并方法,将同一个项内能合并的因子都合并,同一个表达式内能合并的项都合并,尽可能缩短最后的输出。
第三次作业的架构和第二次作业基本一致,所以问题也和第二次作业基本一致。
(2)复杂度分析
方法复杂度如下(只挑选了较复杂的方法):
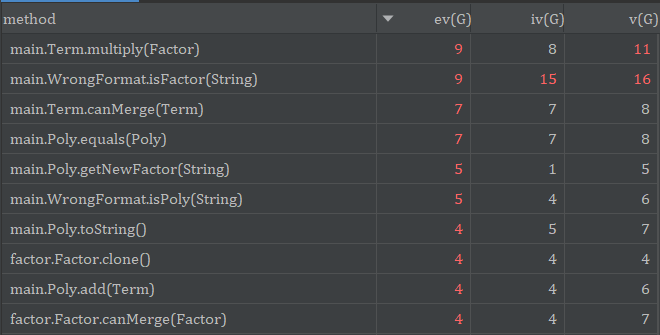
最严重的是WrongFormat类的isFactor方法(用于判断单个因子是否合法),主要是因为因子的种类繁多,不同的因子需要的处理和判断都不一样,最终导致复杂度过高,其实可以针对不同的因子各自设计判断合法的方法,而不必挤在一个方法里;Term类的multiply方法虽然删去了第二次作业中多余的设计,但由于添加了sin(0)/cos(0)的优化,if-else分支增加了不少;Term类的canMerge方法(判断两个项是否能合并)主要是项合并的条件比较严格,必须除常数外所有因子都相同,而每个项中的因子顺序也不固定,最终写出来的方法略显复杂。
类复杂度如下:
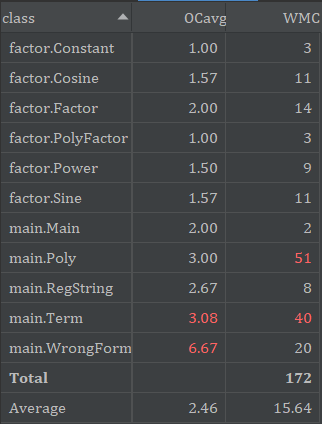
复杂度过高的原因在方法的复杂度中已有所解释。
二、对于自己程序bug的分析
本单元我最终提交的作业并没有在强测和互测中发现bug。
不过我在设计实现的过程中发现过一些比较严重的bug:
1、没有设计clone方法。在多个因子相乘的求导过程中,同一个因子需要在不同的项中出现多次,它们本应该是相同内容的不同对象,但由于我没有设计clone方法,在求导过程中传给各个项的都是同一个因子对象,当某个项发生改变时其他项也会受牵连,导致bug的出现;
2、格式检查时的正则表达式设计问题。我的设计架构对于嵌套的处理是:将最外层的括号替换成方括号,遇到左方括号时再用非贪婪匹配找到最近的右方括号,里面的表达式递归调用进行判断即可(举例,表达式因子的正则表达式:\[.+?\] );但这存在一个隐患:如果表达式因子内部的表达式格式不正确,正则表达式会尝试匹配下一个方括号,再看看格式是否正确,而括号不匹配会导致其他地方出现bug。处理方式是将表达式因子写成:\[[^\[\]]+\],这样可以保证每次括号的匹配都是正确的。
第一个bug的出现是设计上的问题,不好判断bug属于哪个类;但第二个bug毫无疑问是出现在WrongFormat类里的。而上文类复杂度、方法复杂度分析中,WrongFormat在标红的几个类/方法中占有一席之地。这或许也能侧面反映出,越复杂的方法/类中,在设计和实现时需要考虑的事情就越多,出现bug的几率也越大。
三、分析他人的bug
本单元我在第一次作业和第三次作业中都发现过其他人的bug。我采取的测试策略主要是根据作业需求来构造测试样例。例如第一次作业中,我在构造样例时会尽可能全面地设计不同情况的项(+/-符号省略/不省略,系数为1、-1、0、其他数,指数为1、0、其他),以验证程序是否覆盖所有情况;也会涉及一些边界情况,例如第三次作业中指数大于/不大于50;由于输出结果的优化也在作业考核要求中,我也会大致观察他人的代码做了什么优化,设计各种可供优化的数据,验证优化程序是否出现bug。最终发现的bug有:第一次作业没有考虑到系数、指数的大小不受限制;第三次作业中0的0次方当作了0(虽然互测中无法提交)。
另外,我在和其他同学交流时也尝试了一些特殊的样例,如构造“((((((((((x))))))))))”测试程序是否会爆栈,构造多个多项式相乘的数据(如果全部展开项数会上万)测试程序是否将括号展开,且使用了时间复杂度较高的算法(如暴力轮询查找可合并的项),但没有测出bug。
四、重构经历的总结
第一次作业结构简单,我只花了大概一下午的时间去解决,但完全没有考虑为之后的迭代做准备;第二次作业直接加入了三角函数和嵌套规则,难度提升了一个大档次,并且我在设计架构时还考虑第三次作业可能出现的情况,几乎花了两天整的时间才勉强实现;第三次作业由于第二次作业架构设计的好,即使难度依然提升了不少,但我只花了大概半天的时间就完成了迭代,并根据第三次作业的需求做了优化。由此可见,一个好的框架,能帮助我们在迭代开发时节省大量时间和精力,因为好和架构不会因为添加了新东西就让原有的代码完全失效,只要对原有框架做极少量的修改,便可进行新功能的添加。
从上文中的类图也可以看出,第一次作业只设计了两个类,虽然简单,但和之后的作业几乎没有任何联系;第二次作业和第三次作业虽然架构相对复杂,但相比之下,第三次作业只删去了一个Exponents类(用于第二次作业的优化),添加了一个WrongFormat类,其他的架构除了针对第三次作业做的特殊优化,基本没有变动。
五、心得体会
本单元我最大的感悟还是,深刻体会到迭代开发过程中可拓展性的重要程度了。第一次作业需求简单,为了图一时的方便,我只用了两个类,以为能帮助自己更快地完成作业,没成想这其实是在给后面的作业挖坑。第二次作业虽然是我最累的一次,但也正是有了第二次作业的好架构,我才能在第三次作业快速完成迭代。
另外一点体会是,编程是一门实践的课程。课上学的理论知识,只有真正在实践中用到了,你才能感受到它的力量,你才能影响深刻。比如课上讲的深拷贝和浅拷贝,我在实践时真正遇到了需要用到clone方法时,才切身体会到它们的区别;再比如HashMap容器,提供了很多功能,但我实际要使用时才发现,如果要用可变类作为Key,它不会根据可变对象中的成员变量去对应Value值,我在查阅资料后才理解了HashMap的工作原理和hashCode的存在。
总而言之,虽然本单元我的作业完成程度并没有达到自己的预期,但依然有新的收获和理解,希望自己能后面几个单元的作业中吸取教训,持续进步。