buffer
用于更好操作二进制数据,他是一个全局变量。类似数组。
var a=new Buffer();
buffer类的三种实现
- 第一种创建方式 new Buffer(size);size[Number]
// new Buffer(size);size[Number]创建一个buffer对象,并分配大小 //当我们为一个buffer对象分配空间大小之后,长度不固定,不可更改 var bf=new Buffer(5); //bf[6]=10是不可行的。 console.log(bf);
- 第二种 new Buffer(array);
var bf=new Buffer([1,2,3]); console.log(bf); bf[10]=10;//无效 console.log(bf);
- 第三种 new Buffer(string,[encoding])
var bf=new Buffer('dangjingtao','utf-8');
console.log(bf);
对应的编码就以UTF-8的个格式打印到了控制台。
var bf=new Buffer('dangjingtao','utf-8');
console.log(bf);
for (var i=0;i<bf.length;i++){
//console.log(bf[i].toString(16));//转16进制编码
console.log(String.fromCharCode(bf[i]));//转换为可见字符
}
注意:bf.length是字节长度而不是字符串长度
var str1='一二';
var bf1=new Buffer(str1);
console.log(str1.length);//输出2
console.log(bf1.length);//输出6,一个中文占据3个字节
buf.write
buf.write(字符串, 从buffer对象的第几位开始写入,长度, 编码格式)
根据参数 offset 偏移量和指定的encoding编码方式,将参数 string 数据写入buffer.
- 第一个参数是字符串,
var bf=new Buffer(5);
var str='djtao123'
bf.write(str)//只写入了字符串前5个数值,受到了长度的限制。
console.log(new Buffer(str));//不受限制
- 第二个参数是偏移量
var bf=new Buffer(5);
var str='djtao123'
bf.write(str,1)//向右偏移一位,也就是说从第1位而不是第0位开始算起:自动生成的code+‘djta’
console.log(bf);
- 第三个参数:截取的长度
var bf=new Buffer(5);
var str='djtao123';
bf.write(str,1,3)//向右偏移一位,截取三位
console.log(bf);//自动生成的code+’djt‘+自动生成的code。
var str2='';
for(var i=0;i<bf.length;i++){
str2+=String.fromCharCode(bf[i]);
}
console.log(str2);
- 第四个参数(可选):要写入字符串的编码
toString用法
var bf=new Buffer('djtao');
/*
var str=bf.toString()类似于:
var str='';
for(var i=0;i<bf.length;i++){
str+=String.fromCharCode(bf[i]);}
不同的是支持不太好。参见bf.length处的说明
而后面的两个参数又相当于substring方法,比如说:
console.log(bf.toString('utf-8',1,3));截取第1个字符串起,到第3个字符串之前的字符段
*/
console.log(bf.toString('utf-8',1,3));//输出jt
toJSON
就是以json的方式输出出来
var bf=new Buffer('djtao');
console.log(bf.toJSON())
输出如下:

slice
buf.slice([start], [end]) : 返回一个新的buffer,这个buffer将会和老的buffer引用相同的内存地址,注意:修改这个新的buffer实例slice切片,也会改变原来的buffer。跟字符串一样,只能重写。
var bf=new Buffer('djtao');
console.log(bf.slice(1,3));//截取输出第1位和第2位的字符串(jt)的编码
实现方式和字符串的slice方法极其类似。
copy
buf.copy(targetBuffer, 目标buffer起始位数, 拷贝对象的起始位数 拷贝对象的终止位数) : 进行buffer的拷贝
var bf=new Buffer('djtao');
var bf2=new Buffer(5);
bf.copy(bf2)//bf拷贝到bf2
console.log(bf2);
buffer的类方法(静态方法)
- Buffer.isEncoding(encoding) : 如果给定的编码 encoding 是有效的,返回 true,否则返回 false。
console.log(Buffer.isEncoding('utf-8'));//true
console.log(Buffer.isEncoding('gbk'));//false
console.log(Buffer.isEncoding('hex'));//true
- Buffer.isBuffer(obj) : 测试这个 obj 是否是一个 Buffer.
var arr=[];
Buffer.isBuffer(arr)//false
- Buffer.byteLength(string, [encoding]) : 将会返回这个字符串真实byte长度。 encoding 编码默认是: 'utf8'
var str='呵呵';
console.log(str.length);//2
console.log(Buffer.byteLength(str));//6
- Buffer.concat(list, [totalLength]) : 返回一个保存着将传入buffer数组中所有buffer对象拼接在一起的buffer对象.
list{Array} 用来连接的数组
totalLength{Number 类型} 数组里所有对象的总buffer大小(长度)
var bf1=new Buffer('djtao');
var bf2=new Buffer('tao');
var list=[bf1,bf2]
console.log(Buffer.concat(list));//返回拼接后的字节buffer:<Buffer 64 6a 74 61 6f 74 61 6f>
现在回到process的对象中来,看一个案例:
process.stdout.write('请输入内容:');
process.stdin.resume();//开启
process.stdin.on('data',function (chunk) {
console.log(chunk);
});
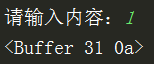
可见chunk实际上返回的是一个buffer对象。31表示1,0a表示回车
当你把字符串和chunk相连之后,会自动调用chunk.toString()方法。所以你在前面的例子看到chunk是一个字符串。而且看不到回车(换行)。