之前课程中学习了栈、队列、二叉树这样一些典型的数据结构,这节课学习一些查找算法,所谓查找算法就是在一个数据结构当中找到我们想要的那个元素,由于二级公共基础所有的只是都是点到为止的,所以这里的查找算法也局限在线性查找这个部分。

所以假设一个线性表中存储了6个数据,现在我们的任务是找74在哪个位置,查找到它在第4个位置,那么是怎么查找出来的呢?我们放慢刚才查找的动作,慢动作是从左往右一个一个看,比如第一个13不是,第二个25还不是,第三个9也不是,第四个74是的,这种查找方法非常普通没什么特别的,所以它的名字就叫做顺序查找。对于任何一种编程语言来说想完成这个算法都非常容易,如果是数组的话就对数组做一个循环遍历,然后都每个数组元素做if语句的判断就可以了。


讲了它的原理现在来思考一个问题,使用顺序查找一个线性表,最坏情况下要比较多少次?我们想一想什么是最坏情况,从左往右查找,如果我们要找的数字刚好在线性表的最右端,这个就是最坏情况,所以要比较n次,所以说顺序查找是一种最简单也是效率最低的算法,它的时间复杂度是O(n),也就是说它是一种线性查找算法。

接下来介绍一种效率更高的算法——二分查找,也叫对分查找,要想使用这种查找算法必须要有两个前提:第一个所有的数据都必须存储在顺序存储结构当中,比如数组,也就是说如果你使用的是一个线性链表的话就不能使用二分查找,第二个问题所有的数字必须从小到大或者从大到小排列好,也就是说这个线性表必须是一个有序的线性表。

现在假设我们有一个数组,里面有1000个数是从小到大排列的,假设要找一个数字T,首先和第500个数比较,如果T>中间数,那么前面的一半就没有比较的必要了,如果T<中间数,那么后面的一半就没有比较的必要了。接下来就重复前面的操作,无论剩下的是前面的500个还是后面的500都和这500个数中间的那个比较,


即使数据量很大有1000个也仅需要比较10次

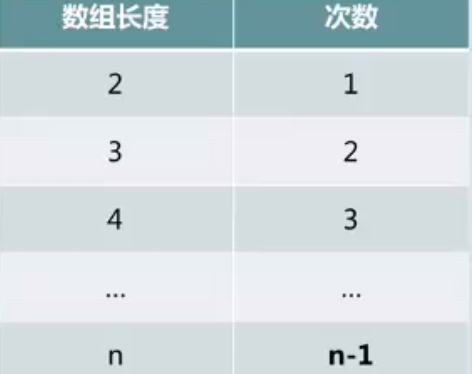
在查找算法中除了要查找一个指定的元素之外,还有一种情况就是查找整个线性表中最大的元素

刚才是拿一个指定的数字和线性表中每一个数据比较,现在是没有数据,直接找出线性表中的最大数,这个时候怎么做呢?一般来说当我们遇到一个复杂的问题的时候首先要对问题进行简化,我们想一想如果n=2,也就是线性表中只有两个元素,这个时候要找最大项要比较多少次呢?显然只需要比较一次就可以了。如果n=3,比较2次。