1,线性表两种实现:
1,顺序表;
2,单链表;
2,问题:
1,如何判断某个数据元素是否存在线性表中?
1,遍历线性表;
2,封装这个遍历操作;
3,遗失的操作 - find:
1,可以为线性表(List)增加一个查找操作;
2,int find(const T& e) const;
1,参数:
1,待查找的数据元素;
2,返回值:
1,>= 0:数据元素在线性表中第一次出现的位置;
2,-1:数据元素不存在;
3,遍历中会有相等和不等操作符,当比较对象是类的时候,需要类继承自 Object,并重写相等和不等操作符;
4,数据元素查找示例:

5,find 查找操作实现:
1,见第“线性表的链式存储——单链表的实现”中4的实现;
6,建议:
1,如果需要将 DTLib 用于工程中,最好在类的定义时候继承自 Object,这样可以避免编译的错误;
7,时间复杂度对比分析:
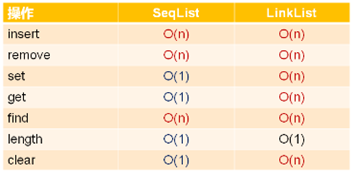
8,顺序表的整体时间复杂度比单链表要低,单链表还有使用的价值吗?
1,效率的深度分析:
1,实际工程开发中,时间复杂度只是效率的一个参考指标:
1,对于内置基础类型,顺序表和单链表的效率不相上下(顺序表稍微高一点点);
2,对于自定义类类型,顺序表在效率上低于单链表;
2,插入和删除:
1,顺序表:涉及大量数据对象的复制操作;
1,基础数据类型不相上下;
2,自定义类类型(非常复杂、深拷贝),顺序表非常低效;
2,单链表:只涉及指针操作,效率与数据对象无关;
3,数据访问:
1,顺序表:随机访问,可直接定位数据对象;
1,原生数组,可以直接定位;
2,单链表:顺序访问,必须从头访问数据对象,无法直接定位;
2,工程开发中的选择:
1,顺序表(类型简单、访问多):
1,数据元素的类型相对简单,不涉及深拷贝;
2,数据元素相对稳定,访问操作远多于插入和删除操作;
2,单链表(类型复杂,插删多):
1,数据元素的类型相对复杂,复制操作相对耗时;
2,数据元素不稳定,需要经常插入和删除,访问操作较少;
9,小结:
1,线性表中元素的查找依赖于相等比较操作符(==);
2,顺序表适用于访问需求量较大的场合(随机访问);
3,单链表适用于数据元素频繁插入删除的场合(顺序访问);
4,当数据类型相对简单时,顺序表和单链表的效率不相上下;