上一篇学习了Series与DataFrame这2种数据结构,Series就像array进化了,有了自己的索引值,有了属性。而DataFrame则包含了更广阔的范围,同样也有columns属性和index属性。最重要的一点就是:在运算中,大家只取相重叠的部分,你有我没有的东西就是缺失值NaN。
一、索引对象Index
from pandas import Series,DataFrame import pandas as pd obj = Series(range(3),index=['a','b','c']) index = obj.index index
Index(['a', 'b', 'c'], dtype='object')
index[1:]
Index(['b', 'c'], dtype='object')
索引对象是不能修改的:
index[1] = 'd'
TypeError: Index does not support mutable operations
不可修改的重要:使得Index对象可以在多个数据结构之间安全共享。
import numpy as np index = pd.Index(np.arange(3)) obj2 = Series([1.5,-2.5,0],index=index) obj2.index is index
True
每个索引都有一些方法和属性。
二、重新索引reindex
方法reindex:
obj = Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c']) obj
d 4.5 b 7.2 a -5.3 c 3.6 dtype: float64
调用Series的reindex方法会根据新索引进行重排,索引值要是不存在的话,就是缺失值。
obj2 = obj.reindex(['a','b','c','d','e']) obj2
a -5.3 b 7.2 c 3.6 d 4.5 e NaN dtype: float64
obj2 = obj.reindex(['a','b','c','d','e'],fill_value=0) obj2
a -5.3 b 7.2 c 3.6 d 4.5 e 0.0 dtype: float64
如果需要对序列进行插值处理,则会用到method:
obj3 = Series(['blue','purple','yellow'],index=[0,2,4]) obj3.reindex(range(6),method='ffill')
0 blue 1 blue 2 purple 3 purple 4 yellow 5 yellow dtype: object

对于DataFrame的reindex:
reindex的行与列:
frame = DataFrame(np.arange(9).reshape(3,3),index=['a','c','d'], columns=['Ohio','Texas','California']) frame
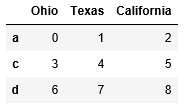
frame2 = frame.reindex(['a','b','c','d']) frame2
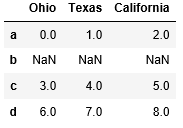
重新索引行。
要是重新索引列,则用columns关键字:
states = ['Texas','Utah','California'] frame.reindex(columns=states)

同时对行、列重新索引,而插值只能按行(轴0)应用:
frame.reindex(index=['a','b','c','d'],method='ffill', columns=states)
报错:
ValueError: index must be monotonic increasing or decreasing
修改:
frame.reindex(index=['a','b','c','d'],columns=states).ffill()

三、丢弃指定轴上的项drop
drop方法返回一个在指定轴上删除了指定值的新对象,只要你给出一个要删除值的索引数组或列表。
obj = Series(np.arange(5.),index=['a','b','c','d','e']) new_obj = obj.drop('c') new_obj
a 0.0 b 1.0 d 3.0 e 4.0 dtype: float64
obj.drop(['d','c'])
a 0.0 b 1.0 e 4.0 dtype: float64
当然,也可以删除DataFrame任意轴上的索引值,给出索引列表:
data = DataFrame(np.arange(16).reshape(4,4), index=['Ohio','Colorado','Utah','New York'], columns=['one','two','three','four']) data.drop(['Colorado','Ohio'])

data.drop('two',axis=1)
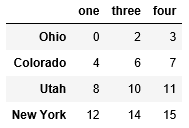
data.drop(['two','four'],axis=1)

四、索引、选取和过滤
DataFrame的索引:
data = DataFrame(np.arange(16).reshape(4,4), index=['Ohio','Colorado','Utah','New York'], columns=['one','two','three','four']) data

data[['three','one']]
切片索引:
data[:2]
布尔型数组选取行:
data['three'] > 5
Ohio False
Colorado True
Utah True
New York True
Name: three, dtype: bool
data[data['three'] > 5]
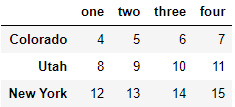
data < 5

data[data < 5] = 0
data
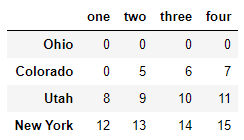
选取行列:逗号前为行,逗号后为列:
data.loc['Colorado',['two','three']]
two 5 three 6 Name: Colorado, dtype: int32
data.loc[['Colorado','Utah'],['four','one','two']]
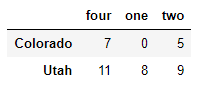
data.ix[2]
.ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing
更改:
data.iloc[2]
one 8 two 9 three 10 four 11 Name: Utah, dtype: int32
data.loc[:'Utah','two']
Ohio 0 Colorado 5 Utah 9 Name: two, dtype: int32
取完行了,再取列:
先拿出three>5的那些行,再拿出第0,1,2列:
data.ix[data.three > 5,:3]
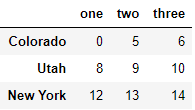
总之,就是通过索引选取你要的数据(某几行某几列)或者是重排数据。
五、算术运算和数据对齐
s1 = Series([7.3,-2.5,3.4,1.5],index=['a','c','d','e']) s2 = Series([-2.1,3.6,-1.5,4,3.1],index=['a','c','e','f','g'])
s1 + s2
a 5.2 c 1.1 d NaN e 0.0 f NaN g NaN dtype: float64
索引标签一样的会自动进行算术运算,索引标签会取并集,不重叠(overlapping)的地方为NaN值。会在算术过程中传播。
DataFrame同理:索引取并,不重叠是Na:
df1 = DataFrame(np.arange(9).reshape(3,3), index=['Ohio','Texas','Colorada'], columns=list('bcd')) df2 = DataFrame(np.arange(12.).reshape(4,3), index=['Utah','Ohio','Texas','Oregon'], columns=list('bde'))
df1 + df2

六、在算术方法中填充值:fill_value
df1 = DataFrame(np.arange(12.).reshape(3,4), columns=list('abcd')) df2 = DataFrame(np.arange(20.).reshape(4,5), columns=list('abcde'))
df1 + df2

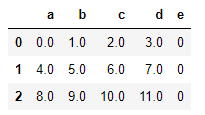
可以选择填充值,就没有NaN了:
df1.add(df2,fill_value=0)

df1.reindex(columns=df2.columns,fill_value=0)
七、DataFrame和Series之间的运算
我们称之以下为广播:
arr = np.arange(12.).reshape(3,4)
array([[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]])
arr[0]
array([0., 1., 2., 3.])
arr - arr[0]
array([[0., 0., 0., 0.],
[4., 4., 4., 4.],
[8., 8., 8., 8.]])
DataFrame与Series也是如此:
frame = DataFrame(np.arange(12.).reshape(4,3), columns=list('bde'), index=['Utah','Ohio','Texas','Oregon']) series = frame.iloc[0]
frame
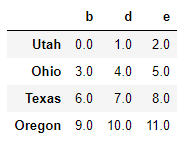
series
b 0.0 d 1.0 e 2.0 Name: Utah, dtype: float64
frame - series
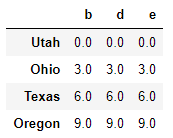
所有的行都会跟着减。
series2 = Series(range(3),index=['b','e','f']) frame + series2
先取索引并集,不重叠的为NaN:

在列上广播:
frame
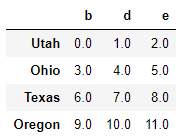
series3 = frame['d'] series3
Utah 1.0 Ohio 4.0 Texas 7.0 Oregon 10.0 Name: d, dtype: float64
frame.sub(series3,axis=0)
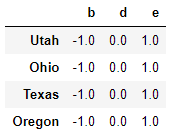
传入的轴号就是希望匹配的轴。目的是匹配DataFrame的行索引并进行广播。
匹配行就是往右拽?匹配列索引就是往下拽?
八、函数应用与映射
一些简单的函数:
frame = DataFrame(np.random.randn(4,3),columns=list('bde'), index=['Utah','Ohio','Texas','Oregon']) frame
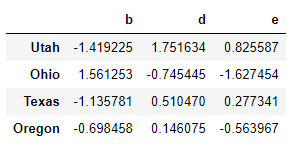
np.abs(frame)
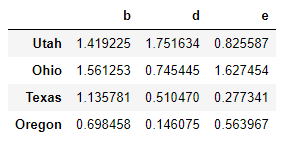
DataFrame中的apply方法:将函数应用到由各列或行所形成的一维数组上。
f = lambda x:x.max() - x.min()
上面定义了一个函数,求最大值与最小值之差。f为函数名。
frame.apply(f)
b 2.980478 d 2.497079 e 2.453041 dtype: float64
看来是对每一列进行操作的。若要求每一行最大最小差值:
frame.apply(f,axis=1)
Utah 3.170859 Ohio3.188707 Texas1.646251 Oregon0.844533 dtype: float64
下一个例子,它说:传递给apply的函数还可以返回由多个值组成的Series:
def f(x): return Series([x.min(),x.max()],index=['min','max'])
frame.apply(f)
其中:frame原本是这样的:
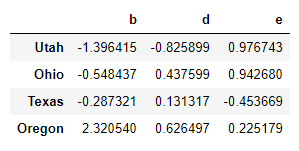
结果是这样的:
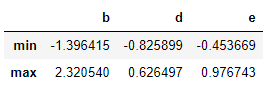
九、排序和排名
sort_index方法:给索引排序,索引对应的值也跟着走啦。
obj = Series(range(4),index=['d','a','b','c']) obj.sort_index()
a 1 b 2 c 3 d 0 dtype: int64
当然也可以对DataFrame的任意一个轴上的索引进行排序:
frame = DataFrame(np.arange(8).reshape(2,4), index=['three','one'], columns=['d','a','b','c']) frame.sort_index()
你猜,它对那个轴排序了?

是横轴!
frame.sort_index(axis=1)
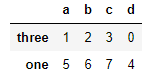
这回就是列轴了。
frame.sort_index(axis=1,ascending=False)
这回是列轴降序排序。
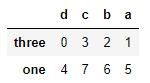
对Series值排序:
obj = Series([4,7,-3,2])
obj.order()
AttributeError: 'Series' object has no attribute 'order'
更改:sort_values这个就顾名思义啦。
obj.sort_values()
2 -3 3 2 0 4 1 7 dtype: int64
索引和对应值永远不分离!
排序时,要是由NaN值的话,都是把它排在最后边。
当你只想给DataFrame的某一列排序时:
frame = DataFrame({'b':[4,7,-3,2],'a':[0,1,0,1]})

用by来传递:
frame.sort_values(by='b')
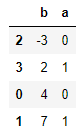
多个列都想排序,传入名称的列表即可:
frame.sort_values(by=['a','b'])
可是这样排,a的大小顺序和b的大小顺序所对应的索引值不一定是一样的啊?
结果a倒是按大小排了,b就不是从小到大排的。
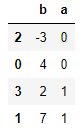
rank方法:一点没看懂
obj = Series([7,-5,7,4,2,0,4])
obj.rank()
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
根据数据值在原数据中出现的顺序给出排名:
obj.rank(method='first')
0 6.0
1 1.0
2 7.0
3 4.0
4 3.0
5 2.0
6 5.0
dtype: float64
降序排名:
bj.rank(ascending=False,method='max')
0 2.0
1 7.0
2 2.0
3 4.0
4 5.0
5 6.0
6 4.0
dtype: float64
当然,DataFrame的我更看不懂了:
frame = DataFrame({'b':[4.3,7,-3,2],'a':[0,1,0,1],
'c':[-2,5,8,-2.5]})
frame
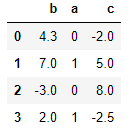
frame.rank(axis=1)
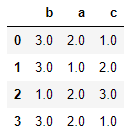
十、带有重复值的轴索引
obj = Series(range(5),index=['a','a','b','b','c']) obj
a 0 a 1 b 2 b 3 c 4 dtype: int64
索引index的is_unique属性:
obj.index.is_unique
False
选取如果索引对应于多个值,则返回一个Series,单个值返回标量:
obj['a']
a 0 a 1 dtype: int64
obj['c']
4
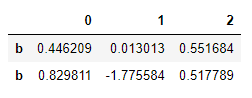
df = DataFrame(np.random.randn(4,3),index=['a','a','b','b'])
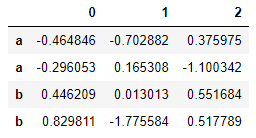
df.loc['b']
2019.10.31 14:54:00