声明:本文章是基于老男孩IT教育中Alex老师所上的课程的总结,所用内容基本上都引用自于Alex老师的课程以及他的博客http://www.cnblogs.com/alex3714/ 在此十分感谢Alex老师的精彩课程,能够让我这个小白走上Python的学习道路。
一、初识模块
Pyhon具有非常丰富和强大的标准库与第三方库,几乎能实现你想要的任何功能。python中的模块分为两种类型,一种是标准库,不需要了另外安装,直接在写程序的时候通过import指令导入就行;还有一种是第三方库,必须要下载安装到对应的文件目录下,才能使用。具体的呢下面最下简单的介绍。
1、两个例子
1)Sysm模块
当运行如下代码的时候,sys的path功能输出的结果是python 的全局环境变量,即python调用该模块时进行索引的路径。argv的功能则是打印模块的相对位置,同时可以用来调用参数。
1 import sys 2 print(sys.path)#打印环境变量 3 print(sys.argv)
2)os模块
1 import os #调用模块 2 cmd_res1=os.system("dir") #system线路是让系统执行一条命令,但是这个命令只能执行不能储存 3 cmd_res1=os.popen("dir").read() #popen线路就是可以储存的,但是这里在执行了之后实际上是相当于暂时放在内存的一个地方, #需要通过read()来调用出来,否则是一堆机器码 4 print(cmd_res1) 5 os.mkdir("new_dir")#这个用于创建一个新的目录,mkdirs则是用来创建一个新的多级目录。
2、关于自己创建模块
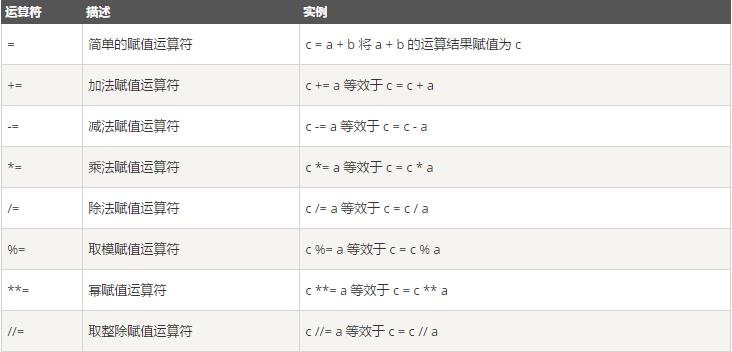


1 a=[1,2,3,4] 2 print(type(a)) 3 type(a) is list
这里最后的输出结果应该为“True”,即表明a确实是一个列表。
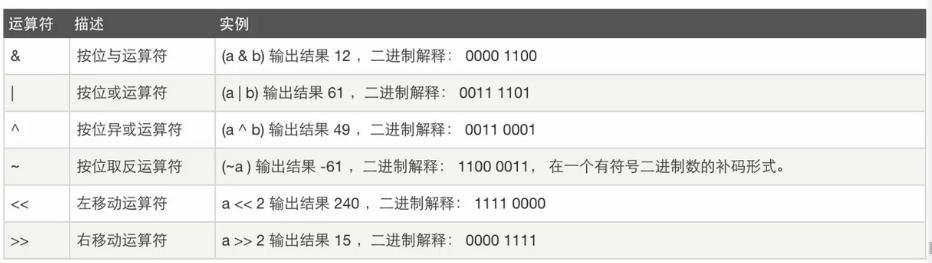
6、二进制位运算
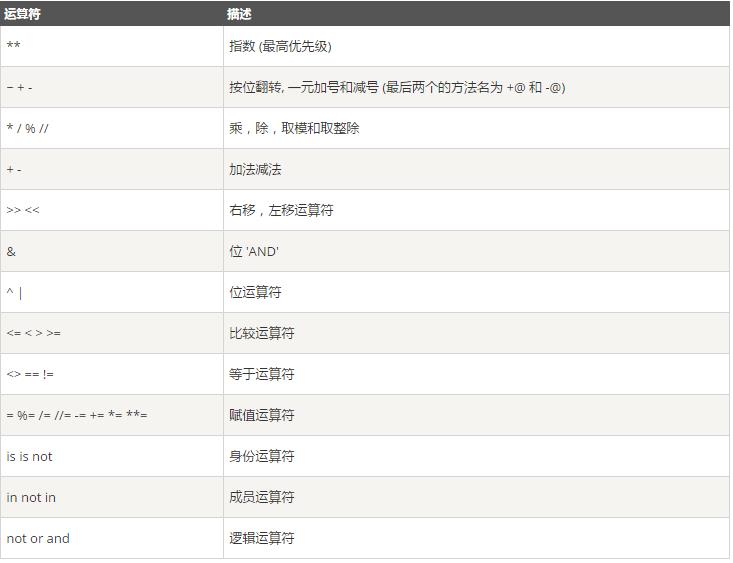
1 a,b,c=3,6,7 2 d=a if a<b else c 3 print(d) 4 #输出结果 5 3
2、进制
- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF
二进制到十六进制的转化:
http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
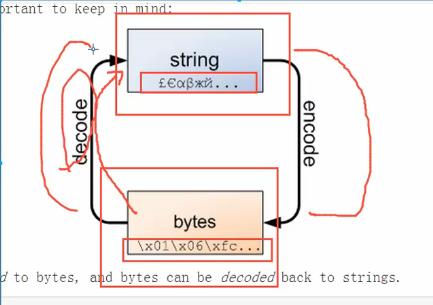
msg="你大爷" print(msg.encode("utf-8")) print(msg.encode("utf-8").decode("utf-8"))
比如上面的代码。
在encode当中,一定要写明原先是哪一种数据类型,如果不写的话,默认是按照utf-8来进行。
1 names=["a","b","c","d","e","b"]
2、对于列表的对象查询
1 print(names[3])#调用列表中的对象,从左到右依次为0,1,2,3... 2 print(names[1:3])#切片,从左边开始的话,顾头不顾尾 3 print(names[-1])#切片,调用最后一位,从右开始数 4 print(names[-3:-1])#切片,按照从最后开始数的方法,但是切片还是从左往右并且顾头不顾尾的。 5 print(names[-3:])#如果要取最后一位,那么:后边应该不写东西 6 print(names[:2])#同理,如果说是从第一个开始,前面是0,也可以不写。 7 print(names[0:-1:2])#跳着切片,最后一个2为步长
3、对于列表的一些拓展功能的使用
1)增加元素
1 names.append("F")#添加元素到后边 2 names.insert(1,"F")#添加元素到指定位置,想到那个位置就写那个位置的下标
2)更改元素
1 names[1]="B" #更改对应位置上的元素
3)删除元素
1 names.remove("c")#这种方式直接写要删除对象的内容 2 del names[2]#这个就是指定位置下标来删 3 names.pop(2) #pop和del起的作用其实基本是一样的,不过要是默认不写下标的话就会删除最后一个对象。
4)查询元素
1 print (names.index("c"))#对于已知内容的对象,打印其位置。 2 print(names.count("b"))#打印相同对象在列表中出现的次数
5)其他的一些
1 names.clear()#清空整个表格 2 names.reverse()#反转整个表格 3 names.sort()#排序,按照ASCII码的顺序进行排列 4 names2=["1","2","3"] 5 names.extend(names2)#拓展表格 6 print(names)
6)关于list_.copy()的一些用法
1 names=["a","b","c","d","e","b"] 2 names2=names.copy() 3 print(names) 4 print(names2) 5 6 #输出结果: 7 ['a', 'b', 'c', 'd', 'e', 'b'] 8 ['a', 'b', 'c', 'd', 'e', 'b']
b.在这里有两级列表,然后更改原始列表中的第一级的一个元素,names2当中并不会发生变化。
names=["a","b","c",[1,2,3],"d","e","b"] names2=names.copy() names[1]="B" print(names) print(names2) #输出结果: ['a', 'B', 'c', [1, 2, 3], 'd', 'e', 'b'] ['a', 'b', 'c', [1, 2, 3], 'd', 'e', 'b']
c、但是看下边,当二级列表中的元素发生改变时,names2也变了。
names=["a","b","c",[1,2,3],"d","e","b"] names2=names.copy() names[1]="B" names[3][1]="贰" print(names) print(names2) #输出结果: ['a', 'B', 'c', [1, '贰', 3], 'd', 'e', 'b'] ['a', 'b', 'c', [1, '贰', 3], 'd', 'e', 'b']
d、如果不使用copy,直接用前面的赋值:那么最后连最浅的一层也复制不了。
1 names=["a","b","c",[1,2,3],"d","e","b"] 2 names2=names 3 names[1]="B" 4 names[3][1]="贰" 5 print(names) 6 print(names2) 7 8 #输出结果: 9 ['a', 'B', 'c', [1, '贰', 3], 'd', 'e', 'b'] 10 ['a', 'B', 'c', [1, '贰', 3], 'd', 'e', 'b']
e、上面的copy情况呢,就是所谓的浅copy,如果需要进行彻底的deepcopy,就需要调用copy模块。
1 import copy 2 names=["a","b","c",[1,2,3],"d","e","b"] 3 names2=copy.deepcopy(names) 4 names[1]="B" 5 names[3][1]="贰" 6 print(names) 7 print(names2) 8 9 #输出结果: 10 ['a', 'B', 'c', [1, '贰', 3], 'd', 'e', 'b'] 11 ['a', 'b', 'c', [1, 2, 3], 'd', 'e', 'b']


1 import copy 2 person=["name",["saving",100]] 3 4 pres1=copy.copy(person) 5 pres2=person[:] 6 pres3=list(person) 7 8 pres1[0]="Dad" 9 pres2[0]="Mun" 10 pres3[0]="Daughter" 11 12 pres1[1][1]=50 13 14 print(pres1) 15 print(pres2) 16 print(pres3) 17 18 #输出结果 19 ['Dad', ['saving', 50]] 20 ['Mun', ['saving', 50]] 21 ['Daughter', ['saving', 50]]
g、关于列表的循环
1 names=["a","b","c","d","e","b"] 2 for i in names: 3 print(i) 4 5 #输出结果: 6 a 7 b 8 c 9 d 10 e 11 b
七、元组
1 names=("lilei","hanmeimei","xiaoming")
八、购物车练习
作业要求:创建一个购物车程序
- 启动程序后,让用户输入工资,然后打印商品列表
- 允许用户根据商品编号购买商品
- 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
- 可随时退出,退出时,打印已购买商品和余额
我初次编写的程序如下:
1 money=int(input("Your salary:"))#需要改进:需要先判断输入的是否为数字,然后再进行转换,而非一开始就转换,, 2 commodities=[[1,"iphone",int(5800)],[2,"mac book",int(10000)],[3,"Unicolo",int(200)],[4,"bicycle",int(2000)]] 3 #需要改进:1、商品编号不够灵活 2、应该用嵌套模型,即元组。 4 shoppingmart=[] 5 while True: 6 print(commodities) 7 i=int(input("The code of what you want:")) 8 9 if commodities[i-1][2]<=money: 10 money=money-commodities[i-1][2] 11 shoppingmart.append("{commodity},¥{price}".format(commodity=commodities[i-1][1],price=commodities[i-1][2])) 12 print("Add {commodity} to your shopping cart!".format(commodity=commodities[i-1][1])) 13 print("Your balance:",money) 14 else: 15 print("Your balance is insufficient!") 16 17 question=input("Do you wanna quit?") 18 if question=="Y": 19 print("You have bought:",shoppingmart) 20 print("Your balance:",money) 21 break
事实上上述程序存在如下问题:
1、虽然能够实现输入编号选择商品,但不够灵活,加入商品增加并且商品名称、编号发生变化,那么会涉及到较大的改动。
2、没有验证用户输入的数据类型以及输入的数据范围是否合理,一旦错误,程序就会报错导致无法运行。
3、无法真正实现“随时都能退出”的要求。
经过老师讲解后,程序改正如下:
1 # Author DingRenpeng 2 commodities=[ 3 ("iphone",5800), 4 ("mac book",10000), 5 ("Unicolo",200), 6 ("bicycle",2000) 7 ] 8 shoppingmart=[] 9 money=input("Your salary:") 10 if money.isdigit(): 11 money=int(money) 12 while True: 13 for index,item in enumerate(commodities): 14 print(index,item) 15 16 user_choice=input("The code of what you want:") 17 if user_choice.isdigit(): 18 user_choice=int(user_choice) 19 if user_choice<len(commodities) and user_choice>=0: 20 p_item=commodities[user_choice]#这一步走的好啊,直接就定义了p_item是个嵌入的元组。 21 if p_item[1]<=money: 22 shoppingmart.append(p_item) 23 money=money-p_item[1] 24 print("已添加%s至您的购物车,您的账户余额为�33[31:1m%s�33[0m"%(p_item,money)) 25 else: 26 print("�33[41:1m您的余额只剩%s,无法支付本商品!�33[0m"%money) 27 else: 28 print("您输入的编号不存在,请重新输入。") 29 30 elif user_choice=="q": 31 print("------购物车商品列表------") 32 for shpping_item in shoppingmart: 33 print(shpping_item) 34 print("您目前的余额为%s"%money) 35 exit() 36 else: 37 print("编号格式输入错误!请重启页面输入!")
该表格的提升在于:
1、使用了表格的嵌套模型;
2、利用字符串操作 isdigit来判断输入的数据类型
3、高亮部分直接定义了p_item为一个列表中的元祖,后边的列表扩展就显得很简单。
4、没了。
九、字符串操作
具体所有的操作如下:
1 name="MY name is Dingtou" 2 print(name.capitalize())#首字母大写 3 print(name.casefold())#大写全部变小写 4 5 print("Dingtou".center(50,"-")) #保证打印出来满50个字符,不够用横线补足,前面字符放中间 6 #输出结果:---------------------Dingtou---------------------- 7 print("Ding".count("D")) #统计某个字符出现次数 8 print("Ding".encode()) #把字符串编译成bytes格式 9 print("Ding".endswith("g") ) #判断是否以某个特定字符结尾,可用于判断邮箱是否以》com结尾 10 print("Din g".expandtabs(10) ) #输出“Din g”,把 转化成此相昂应长度的空格 11 print("My name is {name}".format(name="ding")) 12 print("My name is {name},my age is {age}".format_map({'name':'ding','age':23}))#用于放入字典,但不常用 13 14 print("Ding".index("i") ) #返回i在字符串里边的索引 15 print("Ding123".isalnum() )#如果是数字或者字母,都能返回true 16 print("Ding".isalpha() )#如果是数字,则返回true 17 print("Ding".isdecimal() )#p判断字符串是否为十进制 18 print("123".isdigit() )#如果全部为数字,则返回true 19 print("Ding".isidentifier() )#判断是不是一个合法的标识符,就是一个合法的变量名 20 print("ding".islower() ) #判断字符串是否全部为小写 21 print("ding".isupper())#判断是否是全部大写 22 print("Ding".istitle()) #判断是否为标题,即每个单词首字母大写 23 print("+".join(['1','2','3']))#输出结果为’1+2+3‘ 24 print("Ding".ljust(50,"*"))#在右边用*补齐50 25 print("Ding".rjust(50,"*"))#左边用*补齐50 26 print("Ding".lower())#全部转化为小写 27 print("Ding".upper())#全部转化为大写 28 print(" Ding".lstrip())#删除字符串左边的空格或回车 29 print("Ding ".rstrip())#删除右边的空格或回车 30 print(" Ding ".strip())#删除两边的空格或回车 31 32 p=str.maketrans("abcdefghijklmn","123456789!@#$%") 33 print("Ding".translate(p)) #使用相应的密码来进行翻译 输出结果:D9%7 34 print("Ding".replace("D","P"))#对字符串中的某个字符进行替换 35 print("Ding Renpeng".replace("n","N",1))#数字表示想要替换当中的第几个目标 36 print("Ding Renpeng".rfind('n'))#找到最右边对应字符的下标并返回 37 print("1+2+3+4".split("+")) #输出结果按照括号中的对应字符进行列表的划分。 输出:['1', '2', '3', '4' 38 print("Ding".swapcase()) #输出结果:dING rENPENG 大小写全部转化 39 print("Ding tou".title())#转化为标题格式 40 print("Ding".zfill(10)) #输出结果:000000Ding
十、字典的使用
1、字典的基本格式如下面代码所示:
字典是无序的,不存在下标,因此打印出来的结果中,顺序也是随机的。
1 #key-value 2 info={ 3 "stu01":"Li lei", 4 "stu02":"Hanmeimei", 5 "stu03":"Lidan" 6 } 7 print(info)
2、增加对象
下面的代码中,字典还是为上面已有的info。
1 info["stu01"]="李雷"#修改 2 info["stu04"]="Ding"#添加对象
setdefult:
比如下面代码:
1 info.setdefault("stu01","李雷") 2 print(info) 3 #输出结果 4 {'stu01': 'Li lei', 'stu02': 'Hanmeimei', 'stu03': 'Lidan'} 5 6 info.setdefault("stu09","李雷") 7 print(info) 8 #输出结果 9 {'stu01': 'Li lei', 'stu02': 'Hanmeimei', 'stu03': 'Lidan', 'stu09': '李雷'}
3、删除对象
1 del info["stu01"] 2 info.pop("stu01")#也是删除 3 info.popitem()#随机删
4、更改对象内容
首先是单个对象的更改:
info["stu01"]="李雷"#修改
下边是合并列表,并更新交叉的信息。
1 b={ 2 "stu01":"Xiaogang", 3 1:2, 4 3:3 5 } 6 info.update(b)#合并并且更新交叉的信息 7 print(info)
5、查询对象
1 print(info["stu01"])#这个在找不到的时候会报错 2 print(info.get("stu05"))#正经查找,而且找不到的时候不会报错 3 print("stu05" in info) #查询某对象是否处于列表当中,打印true or false
6、关于item
item 的作用是 把字典转化成为一个大的列表。
1 print(info.items())#把字典转化成一个大的列表 2 #输出结果 3 dict_items([('stu01', 'Li lei'), ('stu02', 'Hanmeimei'), ('stu03', 'Lidan')])
7、关于fromkeys
1 c=dict.fromkeys([6,7,8],"Yo!")#初始化一个新的字典 2 #输出结果 3 {6: 'Yo!', 7: 'Yo!', 8: 'Yo!'}
这里有一点需要提及的地方。看下面代码:
1 d=dict.fromkeys([6,7,8],{"name":"Ding"}) 2 print(d) 3 #输出结果 4 {6: {'name': 'Ding'}, 7: {'name': 'Ding'}, 8: {'name': 'Ding'}} 5 6 d[7]["name"]="Jack" 7 print(d) 8 #输出结果 9 {6: {'name': 'Jack'}, 7: {'name': 'Jack'}, 8: {'name': 'Jack'}}
我们发现当第二级的字典当中内容更改之后,整个最后输出的列表也改了,这其中的道理其实和前面提到的浅copy是一样的。
8、字典的循环
1 info={ 2 "stu01":"Li lei", 3 "stu02":"Hanmeimei", 4 "stu03":"Lidan"} 5 for i in info: 6 print(i,info[i]) 7 #或者 8 for k,v in info.items(): 9 print(k,v)
上面两种循环,看起来效果似乎是一样的,但是
1 av_catalog = { 2 "欧美":{ 3 "www.youporn.com": ["很多免费的,世界最大的","质量一般"], 4 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], 5 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], 6 "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] 7 }, 8 "日韩":{ 9 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] 10 }, 11 "大陆":{ 12 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] 13 } 14 } 15 16 av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来" 17 print(av_catalog["大陆"]["1024"]) 18 #ouput 19 ['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
十一、这里有一个三级菜单的作业
作业要求如下:
- 三级菜单
- 可依次选择进入各子菜单
- 所需新知识点:列表、字典
首先画出该作业的流程图,大致如下:

具体代码如下:
1 # Author DingRenpeng 2 data={ 3 "江苏省":{ 4 "南京市":{"玄武区","秦淮区","建邺区"}, 5 "无锡市":{"崇安区","南长区","滨湖区"}, 6 "苏州市":{"姑苏区","吴中区","相城区"}}, 7 "浙江省":{ 8 "杭州市":{"西湖区","滨江区","萧山区"}, 9 "宁波市":{"海曙区","镇海区","慈溪市"}, 10 "温州市":{"鹿城区","龙湾区","瑞安市"}}, 11 "广东省":{ 12 "广州市":{"荔湾区","白云区","越秀区"}, 13 "深圳市":{"南山区","宝安区","盐田区"}, 14 "汕头市":{"龙湖区","金平区","潮阳区"}} 15 } 16 exit_flag=False 17 18 while not exit_flag: 19 for i1 in data: 20 print(i1) 21 choice1=input("请选择>>>") 22 if choice1 in data: 23 while not exit_flag: 24 for i2 in data[choice1]: 25 print(i2) 26 choice2=input("请选择>>>") 27 if choice2 in data[choice1]: 28 while not exit_flag: 29 for i3 in data[choice1][choice2]: 30 print(i3) 31 choice3=input("请选择>>>") 32 if choice3 in data[choice1][choice2]: 33 choice4=input("选择完毕,请输入b返回或输入q退出") 34 if choice4=="b": 35 pass 36 elif choice4=="q": 37 exit_flag=True 38 if choice3=="b": 39 break 40 elif choice3=="q": 41 exit_flag=True 42 if choice2=="b": 43 break 44 elif choice2=="q": 45 exit_flag=True 46 elif choice1=="q": 47 exit_flag=True
整个三级菜单的程序当中: