https://blog.csdn.net/wang_8101/article/details/83067860
https://blog.csdn.net/a724888/article/details/80290276
https://www.jianshu.com/p/8f4f58b4b8ab
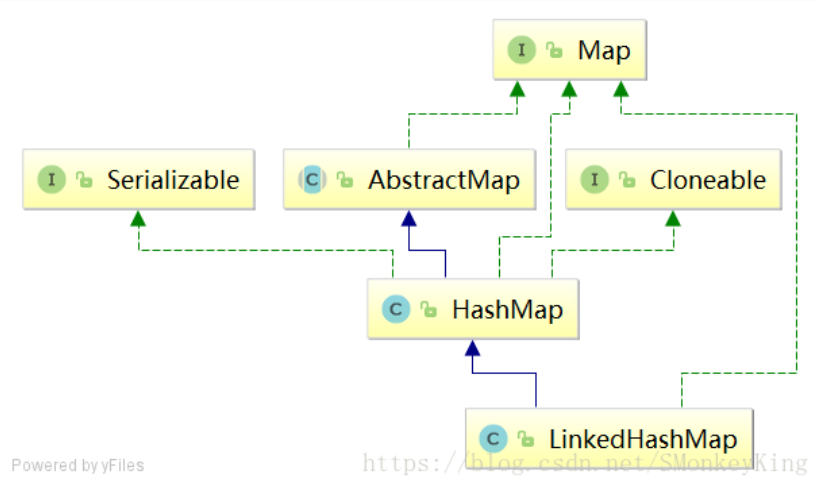
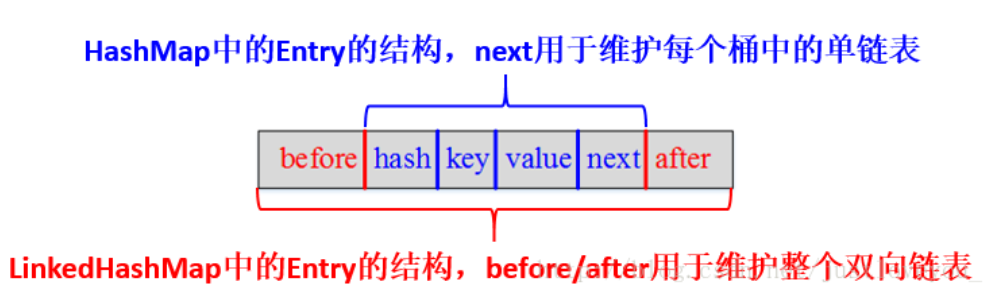
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。LinkedHashMap支持两种顺序插入顺序 、 访问顺序
插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
访问顺序:所谓访问指的是get/put操作,对一个键执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
指定按照访问顺序排序
LinkedHashMap有5个构造方法,其中4个都是按插入顺序,只有一个是可以指定按访问顺序
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
其中参数accessOrder就是用来指定是否按访问顺序,如果为true,就是访问顺序。
LinkedHashMap 存取小结
LinkedHashMap的存取过程基本与HashMap基本类似,只是在细节实现上稍有不同,这是由LinkedHashMap本身的特性所决定的,因为它要额外维护一个双向链表用于保持迭代顺序。
在put操作上,虽然LinkedHashMap完全继承了HashMap的put操作,但是在细节上还是做了一定的调整,比如,在LinkedHashMap中向哈希表中插入新Entry的同时,还会通过Entry的addBefore方法将其链入到双向链表中。
在扩容操作上,虽然LinkedHashMap完全继承了HashMap的resize操作,但是鉴于性能和LinkedHashMap自身特点的考量,LinkedHashMap对其中的重哈希过程(transfer方法)进行了重写。在读取操作上,LinkedHashMap中重写了HashMap中的get方法,通过HashMap中的getEntry方法获取Entry对象。在此基础上,进一步获取指定键对应的值。
使用LinkedHashMap实现LRU算法
public class LRU<K,V> extends LinkedHashMap<K, V> implements Map<K, V>{ private static final long serialVersionUID = 1L; public LRU(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor, accessOrder); } /** * @description 重写LinkedHashMap中的removeEldestEntry方法,当LRU中元素多余6个时, * 删除最不经常使用的元素 * @author rico * @created 2017年5月12日 上午11:32:51 * @param eldest * @return * @see java.util.LinkedHashMap#removeEldestEntry(java.util.Map.Entry) */ @Override protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) { // TODO Auto-generated method stub if(size() > 6){ return true; } return false; } public static void main(String[] args) { LRU<Character, Integer> lru = new LRU<Character, Integer>( 16, 0.75f, true); String s = "abcdefghijkl"; for (int i = 0; i < s.length(); i++) { lru.put(s.charAt(i), i); } System.out.println("LRU中key为h的Entry的值为: " + lru.get('h')); System.out.println("LRU的大小 :" + lru.size()); System.out.println("LRU :" + lru); } }