https://baijiahao.baidu.com/s?id=1633305649182361563&wfr=spider&for=pc
序列化是将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。
什么情况下需要序列化
当我们需要把对象的状态信息通过网络进行传输,或者需要将对象的状态信息持久化,以便将来使用时都需要把对象进行序列化。
或许你会问,我在开发过程中,实体并没有实现序列化,但我同样可以将数据保存到mysql、Oracle数据库中,为什么非要序列化才能存储呢?
我们来看看Serializable到底是什么,跟进去看一下,我们发现Serializable接口里面竟然什么都没有,只是个空接口。
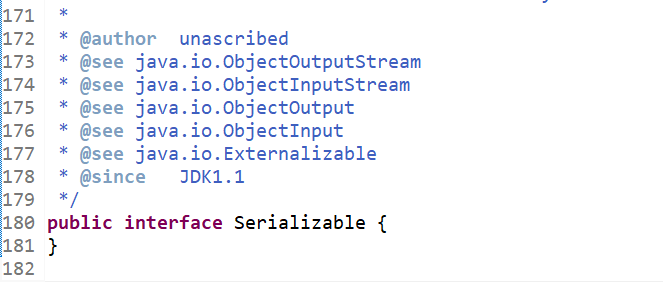
一个接口里面什么内容都没有,我们可以将它理解成一个标识接口。
在Java中的这个Serializable接口其实是给jvm看的,通知jvm,我不对这个类做序列化了,你(jvm)帮我序列化就好了。
Serializable接口就是Java提供用来进行高效率的异地共享实例对象的机制,实现这个接口即可。
为什么要定义serialversionUID变量
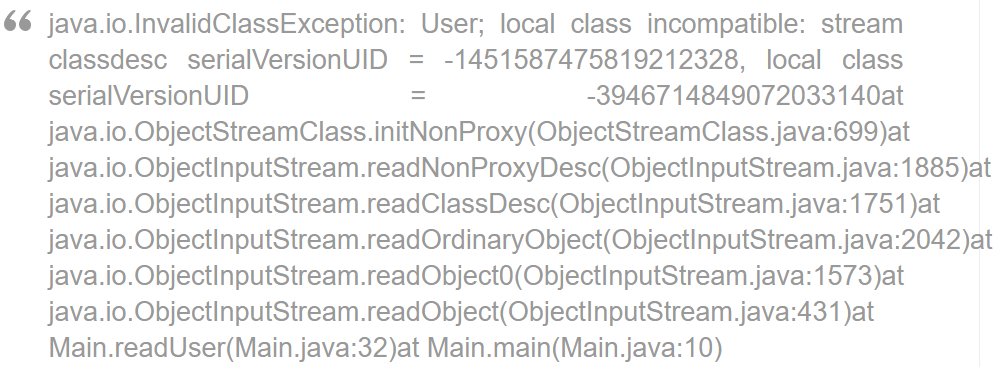
从说明中我们可以看到,如果我们没有自己声明一个serialVersionUID变量,接口会默认生成一个serialVersionUID,但是强烈建议用户自定义一个serialVersionUID,因为默认的serialVersinUID对于class的细节非常敏感,反序列化时可能会导致InvalidClassException这个异常。
serialVersionUID的详细的工作机制是:在序列化的时候系统将serialVersionUID写入到序列化的文件中去,当反序列化的时候系统会先去检测文件中的serialVersionUID是否跟当前的文件的serialVersionUID是否一致,如果一直则反序列化成功,否则就说明当前类跟序列化后的类发生了变化,比如是成员变量的数量或者是类型发生了变化,那么在反序列化时就会发生crash,并且回报出错误:
显式定义serialVersionUID主要有两种用途:
- 在某些场合,希望类的不同版本对序列化兼容,故需确保类的不同版本具有相同的serialVersionUID;
- 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
序列化为什么可以实现深拷贝?
答:若一个对象的属性引用其他对象,则序列化该对象时引用对象也会同时被序列化,这即是序列化能够实现深拷贝的本质。