https://www.infoq.cn/article/OQ7hmrRfYE8ih58L_m3q
https://www.infoq.cn/article/vM2_erirO85MMMfkdNyK
https://www.infoq.cn/article/yV6u9zrMX0s3Es*gUYWC
谈到区块链和分布式计算,最重要的是共识算法和智能合约。但是,谈及日常应用程序,这些属性还不足以支持当今世界的需求。如果我们只依靠上述这两项,就难以想象像在 Netflix 上那样观赏喜爱的电影或电视剧、像在脸书上那样存储或分享值得纪念的视频或照片,或在区块链上玩喜爱的在线游戏(如 DOTA)。
我们缺少一个强大、安全和去中心化的内容存储以及分发系统,服务于当今的应用程序。
下面,我们将探索和评估一些最流行的分布式存储平台。
本文为系列文中的《上》篇,主要介绍 Swarm 和 IPFS。系列文的《中》及《下》篇将分别介绍 Sia 和 Storj 以及 MaidSafe。
1.Swarm

状态:
活跃
说明:
Swarm 是分布式存储平台和内容分发服务,是以太坊 web3 栈的本地基础层服务。Swarm 的主要目标是提供充分分散和冗余存储的以太坊公共记录,尤其是存储和分发 DApp 的代码和数据以及区块链数据。从经济角度来看,它允许参与者有效汇集他们的存储容量和带宽资源,以给网络的所有参与者提供这些服务,同时接受以太坊的激励。
目标
Swarm 更广泛的目标,是为去中心化的 web 应用程序(DApp)开发人员提供基础设施服务,特别是:消息传递、数据流、点对点记账、可变资源更新、存储保险、监管扫描和修复、支付渠道和数据库服务。
从终端用户的角度来看,Swarm 和万维网的差别不大,除了上传不托管在特定的服务器上。Swarm 提供了一个点到点的存储和服务解决方案,它具有 DDos 抗性、零停机、容错和审查及自我维持的特性,它内置了激励系统,通过点对点记账,允许用户为交易资源进行支付。Swarm 旨在和以太坊的 devp2p 多协议网络层以及以太坊区块链进行深度集成,以进行域名解析(利用 ENS)、服务支付和内容可用性保证。
请注意:为了解析 ENS 域名,Swarm 节点必须要连接到以太坊区块链上(主网或测试网)。
请参考开发路径图,以获得 Swarm 的进展信息。
概述
Swarm 旨在给新的去中心化互联网提供基础层的基础设施。Swarm 是点对点的节点网络,通过彼此之间贡献资源(存储、消息转发、支付处理)提供分布式数字服务。以太坊基金会运作 Swarm 测试网,可以用来以类似于以太坊测试网络(ropsten)的方式测试功能。每个人都可以通过在自己的服务器、台式机、笔记本电脑或移动设备上运行 Swarm 客户节点加入到网络中。请参阅《Swarm入门(https://swarm-guide.readthedocs.io/en/latest/gettingstarted.html#getting-started)》一文以了解操作方法。Swarm 客户端是以太坊栈的一部分,参考实现是用 golang 编写的,可以在 go-ethereum 存储库中找到它。目前在所有节点上运行的是 POC 0.3 版。
Swarm 提供本地 HTTP 代理 API,DApp 或命令行工具可以用来和 Swarm 进行交互。像消息传递这样的模块只能基于 PRC-JSON API 才可使用。在测试网(testnet)上的基础服务提供公共网关,用于轻松演示功能和允许免费的访问,以便人们无需运行任何自己的节点即可尝试 Swarm。
Swarm 是 devp2p 网络的节点集合,其中的每个节点在同一个网络 ID 上运行 bzz 协议套件。
Swarm 节点也可以连接到一个(或多个)以太坊区块链上,以进行域名解析,并连接到一个以太坊区块链进行带宽和存储补偿。运行相同网络 ID 的节点应该连接到相同的区块链上以进行支付。Swarm 网络由其网络 ID 标识,该网络 ID 是一个任意整数。
Swarm 允许上传(upload)和消失(disappear),这意味着任何节点可以只上传内容给 Swarm,然后就可以下线。只要节点没有丢失或变得不可用,该内容将仍旧可以访问,这是因为有一个“同步”的过程,节点持续地在彼此之间传递可用数据。
公共网关
Swarm 提供本地 HTTP 代理 API,DApp 可以用来和 Swarm 进行交互。以太坊基金会在托管公共网关,该网关允许免费访问,因此,人们甚至无需运行自己的节点即可尝试 Swarm。
Swarm 公共网关可以在http://swarm-gateways.net上找到,上面一直都运行着最新的 Swarm 稳定版。
请注意:目前,该网关只接受限制大小的上传。将来,上传到该网关的功能很可能完全消失。
上传和下载数据
上传内容由这些步骤组成:“上传”内容到本地 Swarm 节点,接着本地 Swarm 节点用其在网络中的对等点“同步”所生成的数据块。同时,下载内容由这些步骤组成:本地 Swarm 节点查询在网络中的对等点以获取相关的数据块,然后在本地重组这些内容。
内容解析器:ENS
请注意:为了解析 ENS 名称,Swarm 节点必须连接到以太坊区块链(主网或测试网)。
ENS是个系统,Swarm 用它来实现以人类可读的名称(如 theswarm.eth)引用内容。它的操作类似于 DNS 系统,把人类可读的名称转换成机器标识符,在此,即你正在引用的内容的 Swarm 哈希。通过注册一个名称,并把它解析成网站的根清单的内容哈希值,用户可以通过 URL(如 bzz://theswarm.eth/)访问该网站。
请注意:目前,主流的浏览器(如 Chrome、Firefox 或 Safari)不支持 bzz 协议。目前,如果要通过这些浏览器访问 bzz 协议,必须使用 HTTP 网关(如https://swarm-gateways.net/bzz:/theswarm.eth/)或者使用支持 bzz 协议的浏览器(如Mist)。
要了解更多在 Swarm 上传、下载和处理内容的信息,请参阅这里。
可变资源更新(Mutable Resource Updates)
可变资源更新是 Swarm POC3 上的一项高度实验性的功能 。它正在积极开发中,因此,有些东西可能会有变化。
我们在这份指南中已经了解到,当我们在 Swarm 中改变数据时,我们上传的数据所返回的哈希值会以无法预料的方式变化。通过可变资源更新,Swarm 提供一种内置方式,可以对更改数据保持一个持久的标识符。
为了保持与更改数据有相同的指针,常用的方法是利用以太坊命名服务 ENS。但是,ENS 是一个链上功能,它限制了其他地方的功能:
-
每个 ENS 解析器的更新都需要 gas 才能进行。
-
更改数据不可能比挖出新区块的速度更快。
-
正确的 ENS 解析方案要求始终同步到区块链。
可变资源更新允许我们用非变量标识符来更改数据,无需使用 ENS。利用在创建资源时获得的密钥,可以像普通 Swarm 对象一样引用可变资源。
如果同时使用 ENS 解析器合约和可变资源更新,只需要一个初始事务来注册 MRU_MAINFEST_KEY。该密钥将解析到资源的最近版本上(更新该资源不会改变该密钥)。有 3 种和可变资源更新进行交互的方法:HTTP API、Golang API 和 Swarm CLI。
请参阅这里以了解更多情况。
注意事项:
-
只有创建该资源的私钥(地址)可以更新它。
-
在创建可变资源时,必须要提供的参数之一是预期的更新频率。这表明该资源多快(以秒计算)被更新一次。尽管你可以以其他的速率更新该资源,但这么做会减慢索引该资源的处理过程。
Swarm 上的加密
在 POC 0.3 中引入了对称加密技术,现在可以很容易随 Swarm up 上传命令一起使用对称加密了。该加密机制是用来保护信息,并使得在处理任何 Swarm 节点时都不可读分块数据。
Swarm 使用计数器模式加密技术来加密和解密内容。当上传内容到 Swarm 时,该上传的数据被分为 4KB 大小的块。这些块都将用独立的随机生成的加密密钥来编码。这个加密过程在本地 Swarm 节点上发生,没被加密的数据不与其他节点共享。单个块(和整个内容)的引用将是编码数据哈希值和加密密钥的组合。这意味着引用将比标准无加密的 Swarm 引用长一些(不是 32 个字节,而是 64 个字节)。
当你的节点将你的内容的加密块与其他节点同步时,它不与其他节点共享完整的引用(或任何方式的解密密钥)。这意味着其他节点无法访问你的原始数据,此外,它们也无法侦测到同步的块是否经过加密。
检索数据时,只在本地 Swarm 节点上将它解密。在整个检索过程中,这些块以加密的形式遍历网络,参与的对等节点无法解密它们。它们只在用于下载的 Swarm 节点上进行解密和重组。
要了解如何在 Swarm 上处理加密的更多信息,请参阅这里(https://github.com/ethersphere/swarm/wiki/Symmetric-Encryption-for-Swarm-Content)。
注意事项:
-
Swarm 支持加密。由于无法撤销上传,因此强烈建议不上传未加密的敏感和私密数据。用户应该避免上传非法的、有争议的或不道德的内容。
-
Swarm 目前即支持加密也支持未加密的 swarm up 命令,通过使用–encrypt 参数来标识。将来可能有变化。
-
加密功能是非确定性的(因为每个上传请求生成的密钥是随机的),API 的用户不应该依赖结果的幂等性;这样,在启用加密的情况下,同样的内容两次上传到 Swarm 所产生的引用是不同的。
PSS
PSS(Postal Service over Swarm,Swarm 上的 Postal 服务)是 Swarm 上的消息传递协议,具有强大的隐私功能。PSS API 通过在该API Reference中所描述的 JSON RPC 接口公开,我们在这里只解释基本概念和功能。
请注意:PSS 仍然是个实验性的功能,正在积极开发中,可从 Swarm 的 POC3 开始使用。预计有些事情会有所变化。
基础知识
通过 PSS,可以发送消息给 Swarm 网络上的任何节点。消息的路由方式和块的检索申请方式一样。PSS 消息不使用块哈希引用,而是在覆盖地址空间中指定目标,与消息的有效负载无关。如果该目标是一个完整的覆盖地址就可以将其描述为一个特定的节点,或者如果它只部分指定其一,则可以描述为邻居。消息通过 DevP2P 对等连接使用 forwarding kademlia 算法进行转发,forwarding kademlia 算法则通过使用 kademlia 路由的中继节点之间的半永久点对点 TCP 连接传递消息。在目标邻居内,该消息利用 Gossip 进行广播。
由于 PSS 消息是加密的,因此,最终收件人可以解密该消息。可以用非对称或对称加密方式进行加密。
消息有效负载通过接收节点分发给消息处理器,并通过 API 分发给订阅用户。
请注意:目前,PSS 不保证消息的订购(尽最大努力传递),也不保证消息的传递(也即,不缓存和中继给离线节点的消息)。
隐私功能
得益于端到端的加密,PSS 也适合私人通信。
PSS 使用了 forwarding kademlia 算法,对发送者进行匿名化处理。
利用部分寻址,pss 提供收件人匿名的可调范围:目标邻居越多,所显示的预期收件人覆盖地址的前缀越小,就越难识别真正的收件人。另一方面,由于暗路由(dark routing)效率低,因此在匿名性和消息传递延迟及带宽(还有因此产生的成本)之间需要折衷,而这留给应用程序来选择。
如果使用 Handshakes 模块,则提供前向保密。
要了解更多 pss 的使用情况,请参阅这里。
架构
请参阅这里以了解更多 Swarm 的架构。
示例 DApp
请参阅 Swarm 去中心化应用实例的详细内容,请参照这里。
注意事项:
-
敏感内容一定要加密!对于加密内容,上传的数据是“受保护的”,也即,只有那些知道对根块(文件的 Swarm 哈希值和加密密钥)引用的人可以访问该内容。因为发布该引用(在 ENS 上或用 MRU)需要一个额外步骤,只要用户使用加密,就可以轻松地得到保护,防止粗心地发布。Swarm 会删除没有明确受到保护的内容,这是因为 Swarm 中限制了存储容量,Swarm 最终会将这些节点转到垃圾箱内。
-
直到实施存储保险(请参阅路径图以了解更多)之前,测试网不保证持久保存上传的内容。所有参与的节点都被视为没有任何义务的自愿服务,以其意愿删除内容。这样,在激励系统运行之前,用户在任何情况下都不应该将 Swarm 视作安全存储介质。
-
Swarm 是持久数据结构(Persistent Data Structure),因此,在 Swarm 中没有删除或移除操作的概念。这是因为内容被传播到被激励服务它的 Swarm 节点。
Swarm Reddit | Swarm Twitter | Swarm Github
2. IPFS

状态:
活跃(这是一个激励系统,“Filecoin”是不活跃的)
说明:
IPFS(Interplanetary File System,星际文件系统),是点对点(peer-to-peer,简称 p2p)文件共享系统,旨在从根本上改变信息在全球范围内的传播方式。它跟 Swarm 有点类似,或者,我们也可以说 Swarm 跟 IPFS 有点类似。
IPFS 包含了通信协议和分布式系统的几个创新,它们的组合产生了与众不同的文件系统。因此,为了理解 IPFS 所要尝试达到的广度和深度,重要的是,理解使其变得可能的技术突破和所有它在尝试解决的问题。
IPFS 自诩要取代 HTTP。那么,我们来看看如今互联网的工作原理。
简而言之,现在的互联网是协议的集合,这些协议描述了数据是如何在整个网络中移动的。随着时间的推移,开发人员使用着不同的协议,并在该基础设施上构建他们的应用程序。在这些协议中,其中一个是 Web 的骨架,即 HTTP 或超文本传输协议(HyperText Transfer Protocol)。它是由 Tim Berners-Lee 于 1991 年发明的。
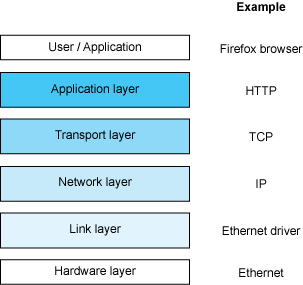
Internet Protocol stack aka. OSI Model
HTTP 是请求-响应协议。客户端(例如 web 浏览器)发送一个请求给外部服务器。该外部服务器随后返回一个响应消息,例如,把谷歌的主页返回给客户端。这是位置寻址协议,这意味着,当在浏览器中键入 google.com 时,它被翻译成某个谷歌服务器的 IP 地址,接着,该服务器启动请求-响应周期。
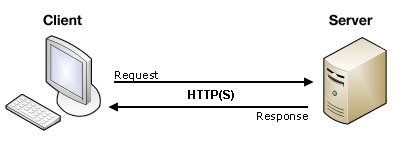
How people talk on Internet
HTTP 的问题
假设你正坐在课堂上,教授要求你访问某个特定的网站。课堂上的每个学生都向该网站发出请求,并获得响应。这意味着,完全相同的数据被单独发送给课堂上的每个学生。如果有 100 个学生,那么就有 100 个请求和 100 个响应。很显示,这不是最有效的方法。理想的话,这些学生将能够利用他们的物理位置接近度以更有效地检索他们所需的信息。
如果网络通信线路有问题,那么 HTTP 也会出大问题,客户端就无法连接服务器。如果 ISP 发生中断、某个国家屏蔽了某些内容,或者,如果内容只是被删除了或移走了,都会发生这样的事情。在 HTTP web 上到处都有这些类型的断连。
HTTP 基于位置的寻址模型鼓励集中化。这便于信任少数拥有我们全部数据的应用程序,但是,因为这个原因,在 web 上的大量数据被浪费了。这也使得这些供应商对我们的信息负有巨大的责任以及拥有巨大的权力(比如脸书)。
HTTP 非常适合加载网站,但是,它不是设计用来传输大量的数据(像音频和视频文件)。这些缺陷可能使得像 Napster(音乐共享软件)和 BitTorrent(电影及几乎任何东西的共享软件)这些文件共享系统的替代品出现并成功成为主流。
时间快进到 2018 年,按需高清视频流和大数据正变得无处不在;我们继续生产/消费越来越多的数据,同时开发越来越强大的计算机来处理它们。云计算中的重大进步有助于维持这种转变,但是,用于分发所有这些数据的基础设施基本没有变化。
解决方案
IPFS 最初是由 Juan Benet 努力构建的系统,该系统可以快速移动版本化科学数据。它是经过互联网技术(DHTs、Git版本系统和Bittorrent)综合测试的综合体。它创造了允许交换 IPFS 对象的 P2P Swarm 。所有的 IPFS 对象形成了加密身份认证的数据结构(Merkle DAG),同时,该数据结构能够用于构建很多其他数据结构。或者,换句话说,就是:
“IPFS 是个分布式文件系统,它旨在用同一个文件系统来连接所有的计算设备。在某些方面,这和 Web 最初的目标类似,但是,IPFS 事实上更类似于一个交换 Git 对象的 Bittorrent Swarm。IPFS 能够成为互联网新的重要子系统。如果构建正确,它能够补充或取代 HTTP。它能够补充或取代更多东西。这听起来很疯狂。没错,它的确很疯狂。”【1】
IPFS 本质上是版本化的文件系统,能够接收文件并管理它们,也可以把它们存储在某个地方,然后随着时间的推移,跟踪它们的版本。IPFS 也记录了这些文件在网络中的移动方式,因此,它也是个分布式文件系统。
IPFS 有管理数据和内容在网络上移动方式的规则,本质上和 Bittorrent 类似。该文件系统层提供了非常有趣的属性,如:
-
网站是完全分布式的。
-
网站没有源服务器。
-
网站可以完全在客户端的浏览器上运行。
-
网站不必和任何服务器有联系。
我们来看看这些不同的技术突破是如何协同工作的。
分布式哈希表(Distributed Hash Tables)
哈希表是一种数据结构,它以键/值对来存储信息。在分布式哈希表(distributed hash tables,简称 DHT)中,数据分布在计算机网络中,以便有效地协调以实现节点之间的有效访问和查找。
DHT 的主要优点在于去中心化、容错和可扩展性。节点无需中心协调,系统能够可靠地运作,即使节点发生故障或下线,并且,DHT 能够扩展以容纳数百万个节点。基于这些特性,使得 Swarm 比客户端-服务器结构更具有弹性。
区块交换(Block Exchanges)
流行的文件共享系统 Bittorrent 能够成功地协调数百万节点之间的数据传输,这是通过依靠创新的数据交换协议完成的,但是,这只限于种子生态系统。IPFS 实现了该协议的通用版本,称为 BitSwap,作为任意类型的数据市场来运营。该市场是Filecoin的基础,Filecoin 是构建于 IPFS 之上的 p2p 存储市场。
Merkle DAG
Merkle DAG 是Merkle树和有向无环图(Directed Acyclic Graph,简称DAG)的混合体。Merkle 树确保在 p2p 网络上交换的数据块是正确的、没有受到损害的和未被修改的。这个验证是利用加密哈希函数数据块来完成的。这只是一个函数,接收输入,计算出与输入相应的一个独一无二的字母数字字符串(哈希)。对于给定的哈希值,容易检查输入是否能得出同样的值,但是,难以从哈希值推算出输入。
单独的数据块被称为“叶节点”,它们被哈希后,形成“非叶节点”。这些非叶节点然后能够组合在一起进行哈希,直到所有的数据块可以用单独一个根哈希值表示。这是更简单的概念化方法:
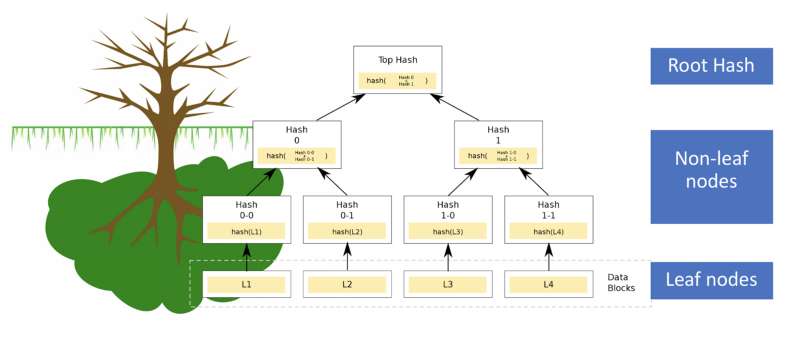
Tree vs Merkle Tree
DAG 是一种无周期拓扑序列信息建模的方法。DAG 的一个简单例子就是家族树。Merkle DAG 基本上是个数据结构,其中哈希被用来在 DAG 中引用数据块和对象。这创造了一些有用的功能:IPFS 上的所有内容能够被唯一地标识,因为每个数据块有独一无二的哈希值。此外,数据是防篡改的,因为数据的更改会改变哈希值,如下图所示:
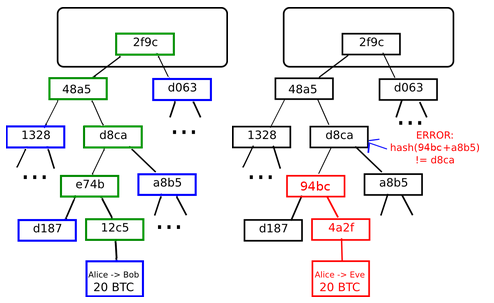
Un-tamperable nature of Merkle tree
IPFS 的核心原则是对生成的 Merkle DAG 上的所有数据建模。这种安全功能的重要性简直难以用言语来形容。打个比方吧,该原则可以保护价值数万亿美元的资产,可见该想法有多么强大了吧。
版本控制系统
Merkle DAG 结构的另一个强大的功能是,它允许构建分布式版本控制系统(version control system,简称VCS)。其典型的一个例子是 GitHub,它允许开发人员轻松地同时协作项目。GitHub 上的文件利用 Merkle DAG 存储和版本化。它允许用户独立复制和编辑一个文件的多个版本,并进行存储,稍后可以把编辑过的版本和原始文件合并。
IPFS 对数据对象使用类似的模型:只要对应于原始数据的对象和任何新版本都可以访问时,就可以检索整个文件历史。鉴于数据块通过网络进行本地存储,并可以无限期缓存,这意味着,IPFS 对象能永久存储。
此外,IPFS 不依赖于对互联网协议的访问。数据可以分布在覆盖网络中,覆盖网络只是构建在另一个网络上的网络。这些功能值得注意,因为它们是抗审查网络的核心要素。它可以成为促进自由言论以对抗全球互联网审查普及制度的工具,但是,我们也应该认识到不良行为者滥用言论的可能性。
自证明的文件系统
我们将要介绍的 IPFS 的最后一个重要组成部分是自证明文件系统(Self-certifying File System,简称SFS)。它是分布式文件系统,无需请求特殊权限进行数据交换。它是“自证明”的,因为提供给客户端的数据是通过文件名来进行身份验证的。结果就是能够利用本地存储的透明度安全地访问远程内容。
IPFS 以此概念为基础,创建了星际命名空间(InterPlanetary Name Space,简称 IPNS)。它是个 SFS,使用公钥加密以自证明通过网络用户发布的对象。我们之前提到,IPFS 上的所有对象可以唯一标识,但是,这也扩展到节点。网络上的每个节点有一套公钥、私钥和节点 ID,节点 ID 是其公钥的哈希值。因此,节点可以使用它们的私钥来“签署”它们发布的任何数据对象,并利用发件人的公钥来验证该数据的真实性。
以下是对关键 IPFS 组成部分的快速回顾:
-
通过分布式哈希表,节点可以存储和共享数据,而无需中央协调
-
IPNS 允许交换的数据立即进行预验证,并使用公钥密码进行验证。
-
Merkle DAG 可实现唯一标识、防篡改和永久存储的数据
可以通过 ConsenSys 写的文章来查看网络中文件是如何被分发的更多细节(深入了解一下)。另外,还可以查看一下 IPFS 的白皮书。
注意事项:
-
始终对敏感内容进行加密!对加密的内容,上传的数据是“受保护的”,也即,只有知道对根哈希值(文件的根哈希值和加密密钥)引用的人才能访问内容。
-
IPFS 是持久性数据结构,因此,IPFS 中没有删除或移除操作的概念。这是因为内容被传播到受激励而服务于它的节点。
-
无法保证上传的数据在网络上持久地存在。所有参与节点应该被视为没有正式义务的志愿服务,并且可以按照它们的意愿删除内容。因此,直到任何激励系统(Filecoin)正常运行之前,用户不应该在任何情况下,把 IPFS 视为安全存储。
IPFS Reddit | IPFS Twitter | IPFS Github
小结
本文是《未来的互联网存储:5 大区块链存储平台深入比较》之《上》篇,介绍的是分布式存储平台 Swarm 和 IPFS。文中详细解读了 Swarm 的主要目标,并对所涉及的公共网关、上传和下载数据、内容解析器 ENS、可变资源更新、Swarms 上的加密、pss 的基础知识和隐私功能、架构及示例 DApp 进行了深入的研究,提供了相应的资源链接。IPFS 实质上版本化,文中除了介绍 IPFS 的目的之外,还通过 HTTP 的问题,引出了解决方案,如分布式哈希表、区块交换、Merkle DAG。版本控制系统是 IPFS 的一个重要组成部分,在文中也做了详细的介绍。
《未来的互联网存储:5 大区块链存储平台深入比较》还有《中》及《下》篇,将分别为大家介绍 Sia 和 Storj 及 MaidSafe。敬请读者们期待。谢谢。
谈到区块链和分布式计算,最重要的是共识算法和智能合约。但是,谈及日常应用程序,这些属性还不足以支持当今世界的需求。如果我们只依靠上述这两项,就难以想象像在 Netflix 上那样观赏喜爱的电影或电视剧、像在脸书上那样存储或分享值得纪念的视频或照片,或在区块链上玩喜爱的在线游戏(如 DOTA)。
我们缺少一个强大、安全和去中心化的内容存储以及分发系统,服务于当今的应用程序。
下面,我们将探索和评估一些最流行的分布式存储平台。
本文为系列文中的《中》篇,我们将接着《上》篇,介绍 Sia 和 Storj。
3. Sia

状态:
活跃
说明:
Sia 为租户提供对去中心化云存储平台的访问,租户得以更便宜、更快地使用对任何人都开放且不受单一权威资源管理的数据中心。Siacoin 基于独立的 Sia 区块链,并且,存储租户和供应商之间达成了协议。
文件在上传之前被分割
在上传之前,Sia 软件把文件分割成 30 个片段,然后把每个片段分发给散布于整个世界的主机上。该分发确保不会存在单点故障主机,并加强整个网络的正常运行时间和冗余。
创建文件片段所用的技术名为Reed-Solomon纠删码,该技术通常用于 CD 和 DVD。纠删码可以使 Sia 以冗余方式分割文件,只要有这 30 个片段中的任意 10 个片段就可以完全恢复整个用户文件。
这意味着,即使这 30 个主机中有 20 个离线,Sia 用户仍然能够下载其文件。
加密每个文件片段
在离开租户的计算机前,每个文件片段都被加密。这确保主机只存储用户数据的加密片段。
这与传统的云存储供应商(如亚马逊)是不同的,亚马逊默认不加密用户的数据。Sia 比现有的解决方案更安全,因为主机只保存加密的文件片段,而不是整个文件。
Sia 采用Twofish算法,该算法是个开源和安全加密标准,是高级加密标准(Advanced Encryption Standard,简称 AES)的竞争对手。
利用智能合约发送文件到主机
利用 Sia 区块链,租户跟主机形成文件合约。这些合约设定价格、正常运行时间承诺以及租户和主机之间关系的其他方面问题。
文件合约是一种智能合约。它们允许我们创建存储在 Sia 区块链上的加密服务级别协议(cryptographic service level agreements,简称 SLAs)。
由于文件合约是由网络自动执行的,因此 Sia 不需要中介或可信赖的第三方。
租户和主机都用 Siacoin 支付
租户和主机都使用 Siacoin,这是基于 Sia 区块链的独特加密货币。租户使用 Siacoin 从主机那里购买存储容量,而主机把 Siacoin 存入每个文件合约作为抵押品。
利用称为支付渠道的技术,微支付在租户和主机之间流通,与比特币的闪电网络类似。租户和主机之间的支付发生在链外,大大提高了网络的效率和可扩展性。
可以点击以下链接,以查看更多关于支付渠道的内容:
侧链与状态通道的区别
两个伸缩方法的完整比较。
(https://hackernoon.com/difference-between-sidechains-and-state-channels-2f5dfbd10707)
由于主机为每个存储合约支付抵押品,因此,它们特别不希望主机离线。
每次用户和托管服务供应商在 Sia 上签署合约时,用户必须提供津贴(以支付托管服务费用),而托管服务供应商必须提供抵押(以确保良好的行为)。合同订立后,软件收取津贴和抵押的 3.9%作为费用,支付给 Siafunds 的持有人,Siafund 是该协议的第二代币。Nebulous Labs 是开发该协议的公司,拥有大约 90%的 Siafund。
这确实是个有趣的长期融资模式,是如今流行的“一次性”ICO 模式的替代品;但是,该功能可能会给系统带来结构性成本,使之比竞争对手更昂贵。文件存储似乎会成为一个高度竞争的市场,这将驱使价格大幅度地降低(与目前的集中式存储的选择相比)。一旦数个不同的去中心化云存储平台部署完毕,这些协议将不仅与集中式替代方案竞争,而且相互之间也要竞争。Sia 对津贴和押金都收取 3.9%的费用,但是,在大多数合约中,是用户支付了这些费用。其他协议没有该结构性成本,这让它们没有那么昂贵,从长期来看,对用户更有吸引力。
价格会发生变化,但是,你可以预期每 TB/月的费用约为 109 个 Siacoin 或 1 美元。
合约随着时间的推移而更新
Renter 为文件合约中的存储预先付费,留出固定数量的 Siacoin 用于支付存储和传输数据。文件合约通常持续 90 天。
Sia 在合约处于过期的特定窗口时会自动更新合约。如果合约没有更新,在合约到期时,Sia 把没有使用的代币退回给 renter。
当单个主机离线时,Sia 自动把 renter 的数据移到新主机,这个过程叫文件修复。
主机提交存储证明
在文件合约到期时,主机必须证明其存储着 renter 的数据。这被称为存储证明。如果该存储证明在特定时间范围内出现在区块链上,那么主机获得付款。如果没有,那么主机被罚款。
存储证明是通过被称为 Merkle 树的技术实现的。Merkle 树可以证明一小段数据是一个较大文件的一部分。这些证明的优点是,它们总能保持在很小的尺寸,无论文件有多大。这非常重要,因为证明是永久存储在区块链上的。
最后,Sia 面临着进入的重要障碍。目前,人们必须先购买比特币,然后用它来购买 Siacoin,再把 Siacoin 发送到 Sia 客户端软件以开始使用网络。对那些日常用户来说,如果没有加密货币,就无法使用网络,这是个大的障碍。它也给企业客户带来问题,因为大多数企业出于监管和金融风险的缘故,不愿意持有和交易加密货币。到目前为止,Sia 团队没有优先考虑设计、可访问性或使用的能力,也没有表明这是一个重要的优先事项。
注意事项:
-
不像 Swarm 和 IPFS,Sia 是分布式云存储系统。它不专注于创建替代 HTTP 的基础设施,而是专注于创建分布式、自我维持且便宜的云存储市场。
-
与 Swarm 和 IPFS 不同,Sia 为存储用户和存储供应商都提供了全面的激励系统。因此,你对数据有更多的控制权(因为为之付出了代价)。你完全可以保证你提供给网络的数据会被存储而不会丢失(在 Swarm 和 IPFS 中会丢失)。另外,你可以从网络中删除内容,并确保已从网络中完全清除。
关于更多 Sia 技术的内容,请参阅这里。
Sia Reddit | Sia Twitter | Sia Github
4. Storj

状态:
活跃
说明:
Storj(跟单词 stroage 的发音一样)旨在成为抗审查、抗监控或不会停机的云存储平台。它是第一批去中心化、端对端的加密云存储平台之一。
Storj 是一大堆互锁件组成,这些互锁件合作创建了统一的系统。由于人们与系统中不同的部分进行交互,导致他们对 Storj 的理解都不同。家庭用户不需要任何关于 Bridge 或协议的相关知识,就可以共享存储空间,而开发人员不需要知道任何家庭用户的情况下,就可以使用 Storj API。每个人和这个系统交互会有截然不同的体验。那么,什么是 Storj?它是协议,是一套软件,还包括那些设计、构建和使用它的人们。
Storj 协议
Storj 的核心技术是可执行的、点对点的存储合约。它是两个人(或两台计算机)同意在不知道对方的情况下,用钱交换一定数量的存储空间的方式。我们把出售空间的计算机成为“farmer”,而把购买空间的计算机称为“renter”。Renter 和 farmer 会面,协商一个合约,把数据从 renter 那里移到 farmer 那里进行保管。
合约和审计
合约有一定的期限。在此期间,renter 定期检查 farmer 是否可用。Farmer 用加密证明回答其仍然有该文件。最终,renter 为每个其收到和验证的证明支付费用给 farmer。这个挑战->证明->支付的过程被称为审计,因为 renter 在审计 farmer 的存储。在合约到期时,farmer 和 renter 可以自由地重新协商或结束彼此之间的关系。
虽然核心技术允许任何种类的支付,但是某些种类比其他的更合适。传统的支付系统(如 ACH 或 SEPA)不适合按审计付费。它们很慢,难以验证,费用经常很昂贵。最理想的 Stroj 协议的支付方式是加密微支付通道。它允许以极低的费用立即进行可验证和安全的极小支付。这意味着,支付和审计可以尽可能地配对。
执行遵循一个简单的针锋相对的方式:如果 farmer 未通过审计,也即下线或不能证明其仍然有数据,那么 renter 就无需付费。毕竟,renter 不再获得其为之付费的服务。类似的,如果 renter 下线,或未能按时付费,那么 farmer 可以扔掉数据,或者从其他人那里寻求新的合约。只要双方遵循合约的条款,每个人最终都可以享受到各自应有的权益。
将审计和支付之间配对可以最大限度地减小与陌生人交易的风险。如果在合约期内,文件被半途丢弃,那么 renter 只支付实际完成的服务(由审计来证明)。其需要找一个新的 farmer,但是不需要大笔的资金。如果 renter 消失了,或停止付费给 farmer,那么 farmer 也获得了其所有之前服务的费用。Farmer 只少了一笔审计费以及需要再花时间寻找购买那个空间的新 renter 而已。
Storj 网络
为了让 renter 和 farmer 能够彼此会面,合约和协商系统是建立在分布式哈希表上(distributed hash table,简称 DHT)。DHT 基本上是一大堆节点自组织成一个有用网络的方法。我们在使用称为kademlia算法的修改版。
DHT 不是让中央服务器注册每个节点和协调所有合约,而是让 farmer 和 renter 广播它们的合约给一大群节点。感兴趣的节点能够轻松地联系提供合约的人。通过这种方式,farmer 和 renter 可以找到任意数量的潜在合作者,在广泛的无许可市场上购买或出售存储空间。
为了寻找合作伙伴,节点可以签署一个不完整的合约,并发布到网络上。网络上的其他节点可以订阅某种类型的合约(也即,它们也许感兴趣的)并响应这些已被发布的合约。该模型被称为发布-订阅或 pub/sub。节点可以轻松地决定哪些合约是它们感兴趣的,并转发给其他它们认为会对此感兴趣的节点。
合约系统和网络一起形成了我们所谓的 Storj 协议。它描述了网络上节点的行为、节点之间通信的方式、合约协商和执行的方式,以及其他和在分布式系统上购买和销售存储空间有关的一切。任何人可以用任何他们喜爱的方式实施 Storj 协议。
Storj 工具包
该协议包含所有安全地制定存储合约的必需工具,但是,它也缺少很多东西。它能工作,但没有用。为了对 renter 有用,系统需要可用性、带宽和以服务等级协议(Service Level Agreement,简称 SLA)形式出现的任何数量的其他承诺。Farming 软件需要管理功能以避免使用过多的资源及自动功能以高效地部署到多个主机。Storj 不是试图把所有这些功能放入核心协议,而是选择在一个额外的软件层解决这些问题。为了让该网络有用和易于交互,Storj 发布了两个工具:Storj Share 和 Bridge。
StorjShare
StorjShare 是引用的 farming 客户端。它允许用户在任何机器上轻松地设置和运行一个 farm。StorjShare 可作为命令行接口(command-line interface,简称 CLI)提供给更高级的用户,还可以实现自动化。该 CLI 允许用户设置参数(如共享的存储空间数量)、存储位置和支付地址。它也处理合约协商、审计响应和其他所有网络通信。
Storj 也发布了 StorjShare 图形化用户接口(GUI)为我们的非技术用户简化 farming 过程。任何人都可以下载 StorjShare GUI,填写几个字段,就加入网络。该 GUI 是 CLI 的包装,可以完成所有的繁重工作。在初始设置之后,用户很少需要与 StorjShare GUI 交互。他们要做的就是设置、最小化,然后让它在后台运行。
如果用户选择进行数据收集,StorjShare 也将收集系统遥测数据。该数据可能包括硬盘容量和利用率,以及网络连接质量的信息。遥测数据被发送回 Storj Labs,因此,Storj 开发人员能够用来改进网络和我们的软件。将来,StorjShare 甚至能够让人们选择特定的服务和程序。
Bridge
为了帮助 renter 使用网络,Storj 还创建了 Bridge。Bridge 被设计成部署到生产服务器,以处理合约协商、审计、支付、可用性和大量其他需求。Bridge 通过应用程序接口(API)和客户端,并通过扩展开放了这些服务和存储资源。该客户端被设计成可以集成到其他应用程序中,因此,任何应用程序可以使用 Bridge 服务器在 Storj 网络上存储数据,而无需成为网络的一部分。
顾名思义,Bridge 是去中心化 Storj 网络的集成桥梁。它的目标是允许传统的应用程序与 Storj 网络进行交互,就像它们使用其他任何对象存储一样。它提炼了 p2p 通信和存储合约协商的所有复杂性以推送和拉取请求。与大多数对象存储不同,Bridge 不直接处理对象,而是引用对象。它存储指针,那些指针指向分布式网络上对象的位置,以及审计这些对象所必需的信息。理想情况下,数据不会通过 Bridge 传输,而是直接传给网络上的 farmer。
Bridge 客户端处理所有客户方面的工作,以有效地使用网络。它在文件进入网络时进行加密,保护隐私和安全。为了确保可用性,它将文件分片,应用擦除编码,并将这些分片分散到多个 farmer 中。然后,客户端与 Bridge 进行通信,以管理网络上的每个分片的地址,并帮助用户在本地管理他们的加密密钥。尽管 Bridge 客户端最初的实现是 Node.js 包,其最终目标是用多种其他语言实现。
Storj API
Storj 核心服务是对象存储,与 Amazon S3 类似。该对象存储是通过一组公共 Bridge 节点管理的。我们维护基础设施来协商合约、管理支付、审计等等。我们的客户通过 Bridge 客户端与我们的 Bridge 进行交互,甚至不必知道他们正在使用分布式网络。该 API 是为可用性而设计的,因此,在幕后处理一切复杂的事物,以提供流畅、可扩展的开发体验。
Storj 利用广泛的网络知识,提供一流的服务质量。其 Bridge 基于与无数 farmer 的历史互动做出决策。Storj 使用与其性能有关的数据及其自报告的遥测数据,以在网络中智能化地分布数据。Storj 优化了高正常运行时间和快速检索。
账户管理功能通过 Bridge 客户端或者 Storj 出色的 web 应用程序可用。同样,GUI 的功能是用来让体验尽可能地流畅。Storj 认为,用户体验(UX)被大多数开发人员导向的服务策略性地忽略了,并且,因为这个原因,他们在设计产品时以简单有用的想法为主导。他们的目标不是提供广泛的云计算和存储服务,而是提供一种优雅的用户体验。
通过 Storj API,他们在尝试为像我们这样的开发人员构建理想工具,我们这些开发人员关心原型开发的时间、高质量的代码和快速迭代。他们希望为小型开发团队、快速扩展的产品和单个开发人员提供工具和支持。他们理解每个开发人员事实上是为自己工作,为其关心的项目工作。这是对我们的爱。Storj 希望构建一个对象存储平台,以便开发人员不必在对象存储上分心,能够专注于构建他们热爱的项目。
可以从 Stroj Labs 了解更多 Storj 的细节。
Storj Reddit | Storj Twitter | Storj Github
小结
本文是《存储百科全书:5 大区块链存储平台的百科全书 所有主要分布式存储平台的深入比较》之《中》篇,介绍的是 Sia 和 Storj。Sia 是分布式云存储系统,专注于创建分布式、自我维持且便宜的云存储市场。文中详细介绍了 Sia 的一些特点,如:文件在上传之前被分割、每个文件片段都被加密、发送文件到主机则是利用智能合约、租户和主机都用 Siacoin 进行支付、合约随着时间的推移而更新。而 Storj 属于第一批去中心化、端对端的加密云存储平台,是由互锁件组成的。文中对 Storj 协议、合约和审计、Storj 网络、Storj 工具包、StorjShare 及 Bridge 进行了详细的说明。
谈到区块链和分布式计算,最重要的是共识算法和智能合约。但是,谈及日常应用程序,这些属性还不足以支持当今世界的需求。如果我们只依靠上述这两项,就难以想象像在 Netflix 上那样观赏喜爱的电影或电视剧、像在脸书上那样存储或分享值得纪念的视频或照片,或在区块链上玩喜爱的在线游戏(如 DOTA)。
我们缺少一个强大、安全和去中心化的内容存储以及分发系统,服务于当今的应用程序。
下面,我们将探索和评估一些最流行的分布式存储平台。
本文为系列文中的《下》篇,我们将接着《上》和《中》篇,介绍 MaidSafe。
5. MaidSafe

状态:
活跃
说明:
SAFE 网络是用于数据存储和通信的自治分布式网络。它为每个人提供安全访问(Secure Access For Everyone,简称 SAFE)。网络上所存储的数据具有极高的可用性、耐用性、隐私性和安全性。该网络可以有效地扩展,而随着网络的扩展,存储在网络上数据的安全性也随之提高。
为什么要使用 SAFE 网络?
现有的基于服务器-客户端的互联网把数据的所有权给了操作这些服务器的人,而不是创造了这些数据的人。操作者可以限制、修改、移除或出售这些数据,而创造数据的人没有追索权。在有利于创建者的条款上,用以分发用户数据的联合协议的接受度差和可用性不强,从而催生了 SAFE 网络的创建。
客户在 SAFE 网络上存储数据,在默认情况下,受到强大的加密保护,可用通过灵活的权限控制层控制访问。
在 SAFE 网络上检索数据的客户端受安全路由和寻址系统的保护。
客户端受益于安全默认设置,包括内置的端到端加密和安全身份验证。
该网络由一组独立操作的节点(被称为 vault)组成的,这些节点可以验证、存储和传输数据。Vault 运营商可以通过提供磁盘空间和带宽供用户使用,有助于通过网络保留网络数据和网络性能。Vault 运营商可以在任何时候加入或离开网络,不会影响存储在网络上的数据安全性。
该网络的代币被称为 Safecoin,为了激发这些资源的供给,由网络分发给 vault 运营商。然后,这些代币可以用于购买网络存储空间供其使用,或使用网络上的其他资源。这激发了 vault 运营商的善意行为,使网络免受恶意行为的攻击。该网络利用 SHA3-256 标识符来保存 vault 和数据,并结合这些标识符之间的汉明距离来匿名并在全球范围内分发所有的数据和流量。
SAFE 网络改进了很多现有的互联网基础设施,包括寻址、域名系统、传输层安全、分组路由、服务器软件(如 HTTP web 服务器和 imap 邮件服务器)、验证层(如 oauth 和 openid);这些都被默认安全模块取代,这些模块结合起来使 SAFE 网络可以运作。
SAFE 在现有的物理互联网基础设施上运行,但取代了所有来自那里的网络层。它主要针对 OSI 的第 3 层到第 7 层。
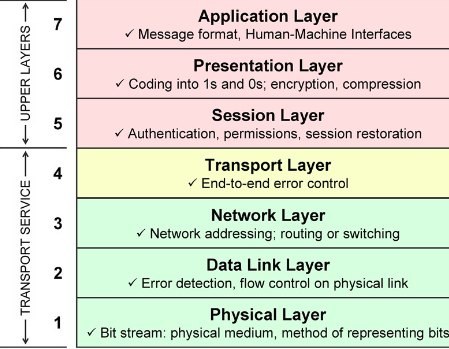
The OSI Model
客户端操作(Client Operations)
客户端可用上传数据到 SAFE 网络上,也可以从该网络下载数据。这个部分概述了这些操作是如何进行的。
资源表示符(Resource Identifiers)
想要从 SAFE 下载数据的客户端,需要可以把安全资源标识符翻译成安全网络端点的软件,这跟浏览器把 HTTP 网址翻译成服务器的端点很像。下载数据不需要特殊的许可或访问,只是需要可以定位和解释网络上数据的软件。
资源作为内容可寻址的资源存储在网络上。用于这些资源的标识符是资源内容的 SHA3-256 哈希值。这个 256 位的标识符用于从网络检索资源(因此类似于 IP 地址),允许客户端指定网络的哪个部分可以为其请求服务。
256 位资源标识符可以用内置的 SAFE DNS(如 safe://www.userX/video.mp4)以人机友好的形式表示。使用能够解释 SAFE DNS 记录的软件,通过在 SAFE 网络上进行查找,可以将文件转换为 256 位标识符。
自加密(Self Encryption)
SAFE 网络上的资源上限是每个 1MB。对于大于 1MB 的文件,客户端将自动把它们的数据分成 1MB 大小的块,随后分发到全网。
这意味着在网络上的典型文件包含几个部分:在文件被分解后,包含 1MB 大小的数据的块,以及存储该文件各部分标识符的数据映射。该网络把数据映射看成是另一个数据块。
客户端保存数据映射资源标识符的记录。因此,尽管文件被分散到很多单个的资源上,也可以通过检索单个资源(也即,数据映射),实现检索整个文件。这样一来,任何资源都可以通过单个资源标识符来寻址。
数据映射也充当其所引用的数据块的加密密钥。数据块通过该密钥加密,因此 vault 不能读取单个的数据块以窥视原始数据的部分信息。这就是自加密(Self Encryption)。
此外,利用客户端软件内置的加密选项,在上传文件之前,用客户端对文件进行加密。这使用了从用户对网络进行身份验证派生出来的唯一安全密钥。这意味着,可以解密文件的密钥永远不会离开客户端,也永远不对网络公开,从而使极其安全地数据存储成为可能,就算通过数据映射访问,也无法通过网络上的任何 vault 解密。
通过自加密分割数据有很多好处:
-
块本身是没有用的,因此,所有的块都是可替换的,对网络来说,具有同等价值
-
客户端可以并行下载用于文件的块,提高了性能
-
块具有独特且广泛分布的名字,因此,不容易相互关联。
-
广泛分布的块大大降低了单个 vault 脱机时,数据丢失的可能性
-
基于内容的黑名单是不可能存在的
不可变数据(Immutable Data)
资源标识符是由资源的内容决定的。这意味着,一个资源的两个相同副本将有相同的标识符(也即,电话和笔记本上保存着相同的照片)。这带来几个好处:
-
资源标识符是通用的、唯一的和永久的(与目前互联网上的网址不同)
-
资源不能在网络上复制,提高了存储效率
-
资源的缓存规则是极其简单有效的
-
加密资源对加密它们的密钥是唯一的,因此,不能通过存储它们的 vault 来解密
网络遍历(Network Traversal)
当客户端连接到网络时,网络为其分配会话标识符。这个会话标识符决定哪个 vault 充当其进入网络的入口点。
当客户端请求资源时,该请求被发送到其入口点 vault,然后,通过在网络上的其他 vault 进行路由,最终到达存有被请求资源的 vault。接着,数据沿着该路由传回客户端。
此路由机制通过最近的汉明距离,逐步遍历 256 位的命名空间。
所请求的资源有唯一的 256 位标识符,该标识符由自加密过程确定。充当客户端入口点的 vault 也有唯一的 256 位标识符(和所有的 vault 一样)。
块标识符与入口点 vault 标识符进行异或。产生的结果是块和 vault 之间的汉明距离。
如果相邻 vault 的标识符离开块有更小的汉明距离,那么请求被传递到那个 vault。
持续遍历下去,直到没有离块有更近汉明距离的 vault。
该块将被存储在离块标识符最近(用距离的异或值衡量)的 vault 中。
该 vault 检查其是否有所请求块的副本,并按照请求来路返回响应。
该过程形成一个请求链,其中每个 vault 只知道链中一步之遥的节点的细节。原始请求和存储块的该 vault 通过该 vault 链隔开,以使请求匿名化。
存储块时会发生相同的网络遍历。块通过其进入口点 vault 进入网络,然后进行传递,直到到达最近的 vault,然后该 vault 存储块。
路由上的节点可以缓存块,因此,如果稍后有另一个这样的请求,可以通过不同的路由,这能更快地响应,无需将请求一直延伸到最终的存储 vault。
消息传递(Messaging)
电子邮件和即时消息是当今互联网上无处不在的体验。SAFE 促进了消息传递,它可以取代 imap/smtp/xmpp 服务器。
消息可以与存储任何资源相同的方式存储在网络上。为了确保消息保持私密,发送消息前可以用接收密钥(该密钥也被当作资源存储在 SAFE 网络上)进行加密。通过同样的方法,联系人之间的连接(如 gpf 信任网)也可以通过资源在网络上表示。这个资源的集合构成了安全消息传递平台的基础。
唯一剩下的步骤是,在收到消息时,通知接收人。在当前的互联网上,新消息通常是通过给用户的收件箱添加新消息来呈现给用户的。因为,收件箱只是消息列表,所以该列表可以表示为网络上的资源。但是,在 SAFE 网络的情况下,该收件箱不是作为不可变数据创建的,而是作为可变数据创建的。后一种数据类型有固定的标识符,其不取决于资源的内容。它结合了权限系统后,允许对该标识符的数据进行更新。
该数据类型允许通过更新位于收件人的收件箱标识符的数据,来通知收件人有新消息。允许创建该收件箱资源,任何人都可以追加新数据。消息的发送方可以将标识符附加到收件人的收件箱,这样,收件人能够定位新消息。
该消息传递系统促进了像电子邮件和即时消息这样的功能的实现,而且也为其他基于消息传递的系统提供了基础,如支付、智能合约、社交网络、进程间信令、动态 web 内容、用于 webRTC 的 STUN 服务器……
可变数据(Mutable Data)
可变数据是网络上呈现的第二种也是最后一种数据类型。它允许修改处于网络上固定位置的数据。
强大的权限层允许可变数据的所有者指出谁可以修改数据以及怎样修改数据。
所有权的验证和可变数据的修改是由网络利用数字签名来实现的。可变数据的所有者可以指明哪些密钥是被允许或被拒绝用来修改数据。
允许或拒绝每个密钥对现有内容的操作。这些操作不是“更新(update)”,就是“追加(append)”。
通过明确定义的权限和加密安全签名的结合,所有者可以严格控制对可变数据的修改。
可变数据的内容可以指向另外的可变数据,允许可变数据链的创建,可变数据链可以用于许多目的,例如版本控制和分支、可验证的历史和数据恢复。
网络操作(Network Operations)
有几个由网络实施的操作允许客户端安全可靠地存储和检索数据。这些操作产生了一个抵抗攻击的自主自愈网络。
密切团体共识(Close Group Consensus)
网络上的节点(称为 vault)主要负责存储数据块。块的可用性对网络的成功来说是至关重要的。
因为任何人在任何时刻都可以添加他们的 vault 到网络或从网络中删除 vault,网络必须能够侦测到恶意行为,并在其引起数据丢失前做出响应。这需要实施一套管理 vault 可接受行为的规则。不符合该规则的 Vault 将被网络拒绝,并且不对客户数据负责。
该规则的实施通过被称为“密切团体共识(Close Group Consensus)”的过程进行。
Vault 形成彼此之间协调的团体,以便就网络上的数据状态达成共识。任何不遵守团体共识的 vault 被拒绝,并由不同的 vault 取代。
团体强制执行的规则是数据:
-
可以存储
-
可以检索
-
尚未修改
这取决于团体中具有以下性质的 vault:
-
有可用空间以存储新数据
-
有可用带宽以在被请求时转发该数据
-
有充分的参与以和团体中的其他 vault 达成共识
Vault 命名
所有 vault 在加入或重新加入网络时,会被网络随机分配一个唯一的 256 位标识符。那些彼此靠近的 Vault(通过其标识符之间的汉明距离衡量)形成团体。团体中的 vault 合作以形成网络上数据的共识,因此可以存储和检索数据。团体以 8 到 22 个彼此靠近的 vault 形成。网络上的 vault 越多,网络上团体的数目就越多。
如果团体中的大多数 vault 是不诚实的,那么该团体中的数据就容易被破坏。
这意味着,团体的大小要进行权衡,既要足够大到难以控制团体中的大多数 vault,也要小到能够快速达成共识。
网络的安全性问题主要是,因为攻击者可能不为其 vault 选择标识符。他们必须反复地加入和离开网络,直到网络给他们的 vault 在团体中分配标识符,该团体是他们试图控制的。他们必须为团体中的大多数 vault 执行该操作,以控制该团体的共识。
因此,控制团体的难度是由网络的规模大小来决定的,随着网络规模的增长,难度成比例地增加。网络越大,团体就越多;而团体越多,就越难加入一个特定的团体。
克服新 vault 的网络分配标识符问题是尝试滥用共识机制的困难的主要来源。
不相交的部分(Disjoint Sections)
实际要考虑的团体的形成是,团体内部消息传递的效率(也即,团体成员的共识,而不是单个 vault 行为的共识)。
团体的形成基于其标识符的前导位的相似性(标识符的该部分被称为该 Section 的前缀)。
这让 vault 的离开或加入团体的协调更简单。
如果团体保持成员数量是 8 个 vault,那就需要在新 vault 加入和离开的时候,重新组织团体之间的独立 vault。这也许会对附近的团体产生连锁反应。
与其做这个连锁的重新组织,不如把团体的规模控制在 8 到 22 个 vault 之间。如果团体成员超过 22 个 vault,它就分成两个新团体,如果它的成员小于 8 个 vault 时,那么就和最近的团体合并。
这种组织团体的方法被称为不相交的部分(Disjoint Section)。
流失(Churn)
在网络上随机位置上建立 vault,以防止对团体共识机制的攻击。这个安全性通过间歇性的 vault 重定位得到进一步的强化。必须发生了对团队的攻击后,才能重定位。
一个 vault 通过网络重新分配一个新的随机标识符进行重定位。这导致了其离开现在的团体,并成为新团体的一部分。它之前存储的所有块变成不同 vault 的责任,并由团体共识机制自动处理。该重定位的 vault 现在必须存储离它的新标识符最近的块,并继续与新的 vault 团体构建共识。
该机制被称为流失(churn),是在新 vault 加入网络或现有 vault 离开时发生的相同过程的延伸。
耕作(Farming)
Vault 运营商加入网络和为安全数据存储而合作的动机是由网络代币激发的。该代币(称为 safecoin)可以兑换网络上的资源或用来与网络上提供的其他资源进行交互。该代币的激发作用和区块链上的代币类似,以确保合作参与比不合作参与更合理。
代币是由网络上的不可变数据表示。网络定义了总共 232 个不可变数据资源作为 safecoin 对象,最初不存在拥有者,因此不存在要考虑的代币经济。
网络通过资源证明机制间歇性地分配无归属的 safecoin 给网络的参与者,这引起了代币的总体数量随着时间的推移而增长,充当了代币和网络存储经济的引导机制。
用 safecoin 交换网络资源时,分配的 safecoin 的总体数量也可能缩减。用户必须交换 safecoin 以在网络上存储数据。这涉及向网络提交 safecoin,然后,网络删除 safecoin 的拥有者,并分配网络存储空间给该用户使用。这个机制被称为代币回收,通过资源证明为分配的 safecoin 的增长提供了平衡。
通过数字化签名,把 safecoin 可变数据资源的所有权转移到接收者的密钥上,实现在用户之间的 safecoin 的转移。利用存储在可变数据资源中的现有拥有者的密钥,可以轻松地验证数字化签名。一旦所有者的信息被更新,转移过程就完成了,这使得 safecoin 的转移极其快速、有效和安全。
资源证明(Proof Of Resource)
当网络观察到 vault 的合作行为时,vault 就有权要求拥有一个 safecoin。每个声明的特定 safecoin 标识符是网络随机生成的。
如果该标识符的 safecoin 当前没有归属,那么网络就把它分配给该 vault 的所有者,从而将“铸造(minting)”一个新 safecoin 到该经济体系中。
如果该标识符的 safecoin 已经有归属,那么不会有进一步的行动。从这个意义上说,与区块链工作证明非常类似,safecoin 的 farming 有个机会因素,其会导致与所提供的资源成比例的均匀分布。
分配 safecoin 的速率的调整方式和区块链难度机制类似。该调整旨在平衡网络上的资源可用性。在需要的时候,它鼓励提供更多资源,并在过度供应的时候,通过降低奖励来减少过度的浪费。
Safecoin 支付算法尚未正式指定或实施。
网络把合作行为定义为带宽和存储空间的可靠供应,并继续参与达成共识。与区块链工作证明不同,其最终用户从挖矿能力的进一步增长中得到的收益递减,资源证明机制持续为最终用户提供与网络资源增长成比例的效用。
结论
SAFE 网络是用于可靠数据存储和通信的自治网络。健壮的数据存储和消息传递系统的组合形成了互联网大多数的现有基础设施的安全和私有替代方案。
利用内容可寻址资源标识符和自加密,可以有效且可靠地把数据存储在网络上。
数据能得以保存而不会遭到破坏,可以在任何时候通过密切团体共识(close group)和不相交部分(disjoint sections)进行检索。
在所达成的系统阻止恶意行为的规则范围内,网络分配代币以激励资源的供应,并确保对未来的客户持续的资源供应。该分布基于资源证明机制,该机制难以作弊,并表现出积极的外部性。
该网络随着更多 vault 的加入,提高了速度、安全性和可靠性,使得规模的快速增长成为优势而非问题。
最终用户受益于默认安全模块和灵活的权限层,以最适合其需要的方式控制访问。SAFE 网络将很多独立模块组合在一起,为所有人创建具有安全访问的网络。
MaidSafe Reddit | MaidSafe Twitter | MaidSafe Github
小结
本文是《未来的互联网存储:5 大分布式存储平台深入比较》之《下》篇,介绍的是 MaidSafe。SAFE 网络是用于数据存储和通信的自治分布式网络。它强调为每个人提供安全访问,并且随着网络的扩展,安全性也会提高。文中解释了为什么使用 SAFE 网络,并对以下概念进行了详细的说明介绍:客户端操作、资源表示符、自加密、不可变数据、网络遍历、消息传递、可变数据、密切团体共识、Vault 命名、不相交的部分、流失、耕作、资源证明等。