魔法常数magic constant、黄金数值的来历及讨论: mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225] 在前文已经讨论:
在深度学习的视觉VISION领域数据预处理的魔法常数magic constant、黄金数值: mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]
===============================================
首先声明这个常数其实就是针对ImageNet的,准确说就是针对ImageNet2012的,这个常数并不适用所有数据集,有很多地方并没有区分这一点是因为在VISION领域很多人使用的数据集都是ImageNet,但是这一点对于新人来说则有些难度。
pytorch教程中对magic constant做了简单的描述:
https://pytorch.org/vision/stable/models.html

对这个magic constant的讨论最多还是以GitHub上的issues呈现的:
预处理细节问题的最早提出:
地址:https://github.com/pytorch/vision/issues/39

那么在ImageNet2012数据集上数据的预处理操作具体为什么?下面给出了答案:
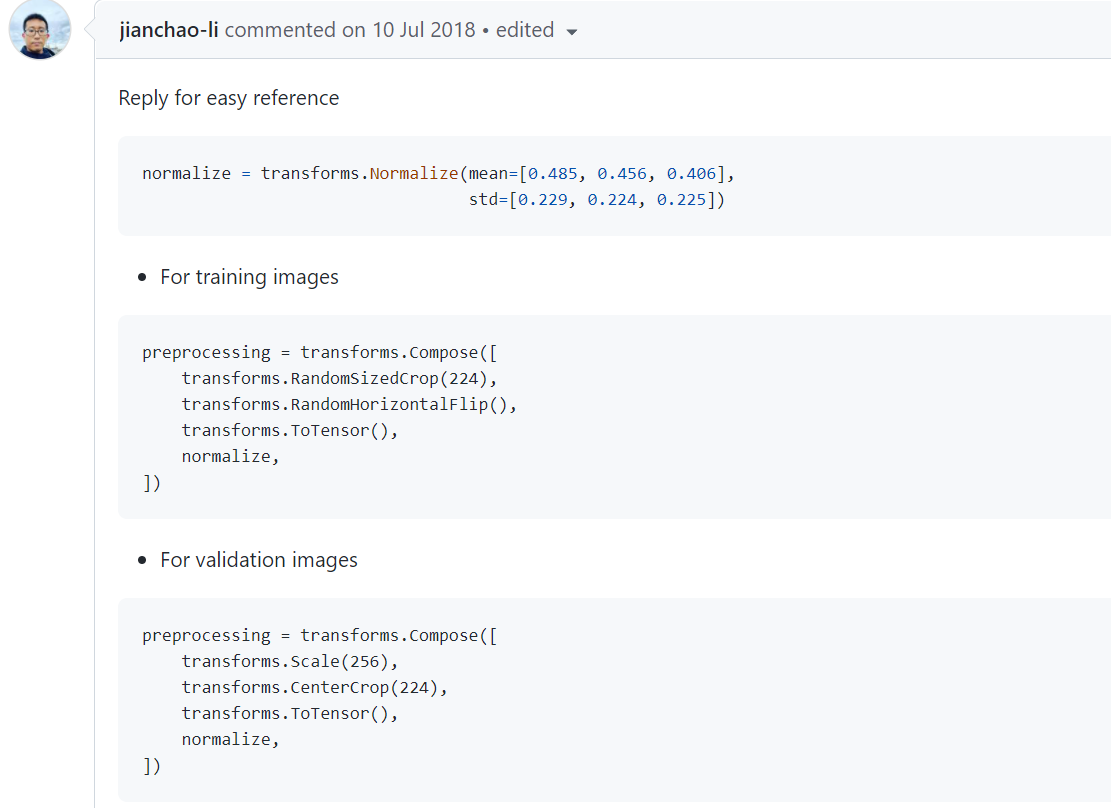
Reply for easy reference
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
- For training images
preprocessing = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
- For validation images
preprocessing = transforms.Compose([
transforms.Scale(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
loader = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(IMAGE_SIZE), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ])
在issues, 1439 和 1965 中对这个Magic Constant的来历进行了讨论:
https://github.com/pytorch/vision/issues/1439
https://github.com/pytorch/vision/pull/1965

pmeier 找不到原始数据预处理时的设置,于是尝试复现当时的设置:

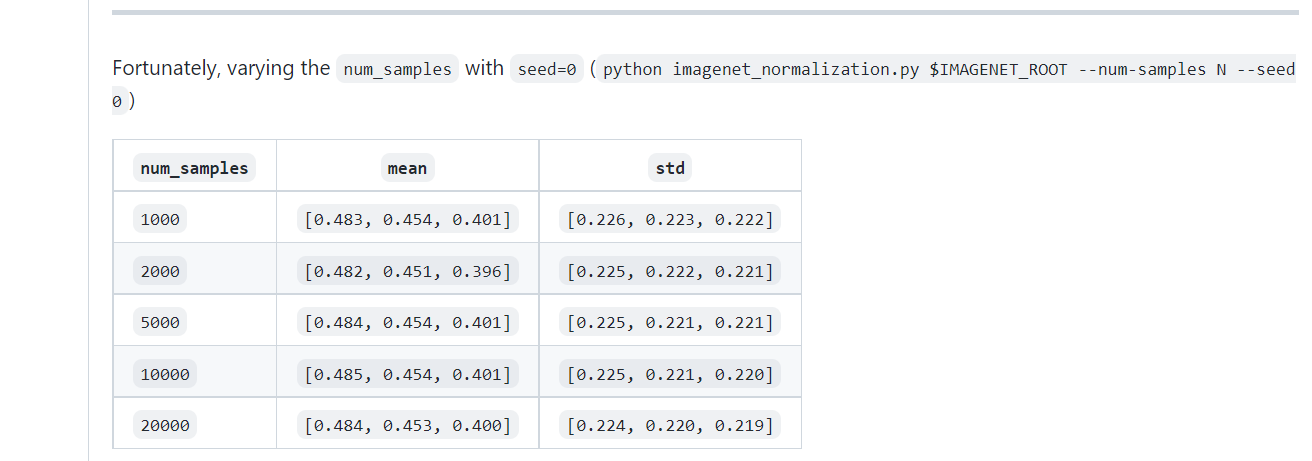
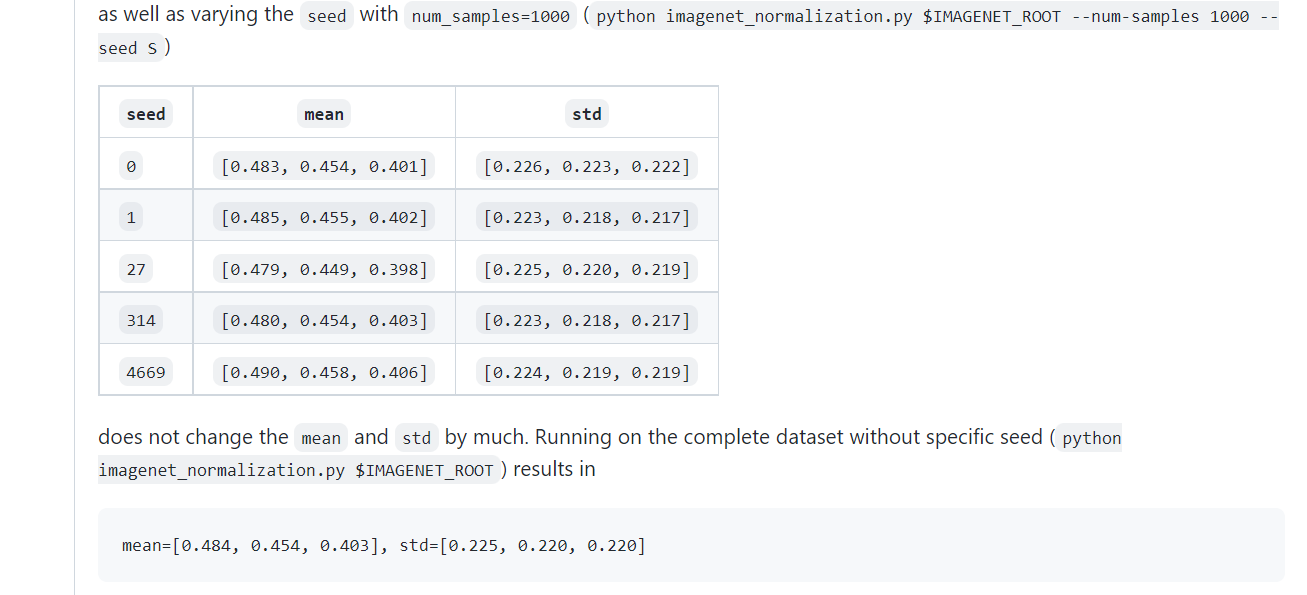
可以看到不管怎么尝试都没有复现原始的设置。
同时有人给出了同时代的出处: https://github.com/facebook/fb.resnet.torch/blob/master/datasets/imagenet.lua
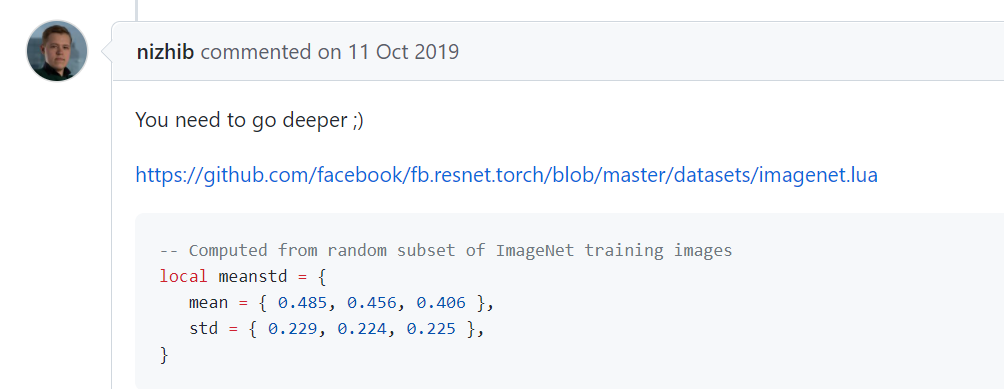
最后的问题就是这个magic constant是无法复现的:
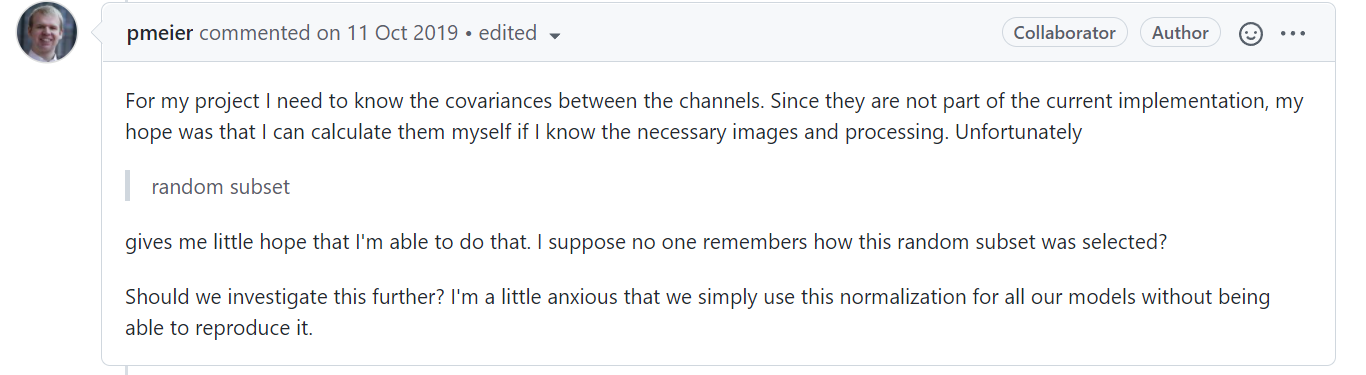
最后的结论是复现这些constant是没有太多意义的,因为即使使用可以复现的constant也不太会显著的提高模型性能,而且现有的模型都是使用这些magic constant训练好的。
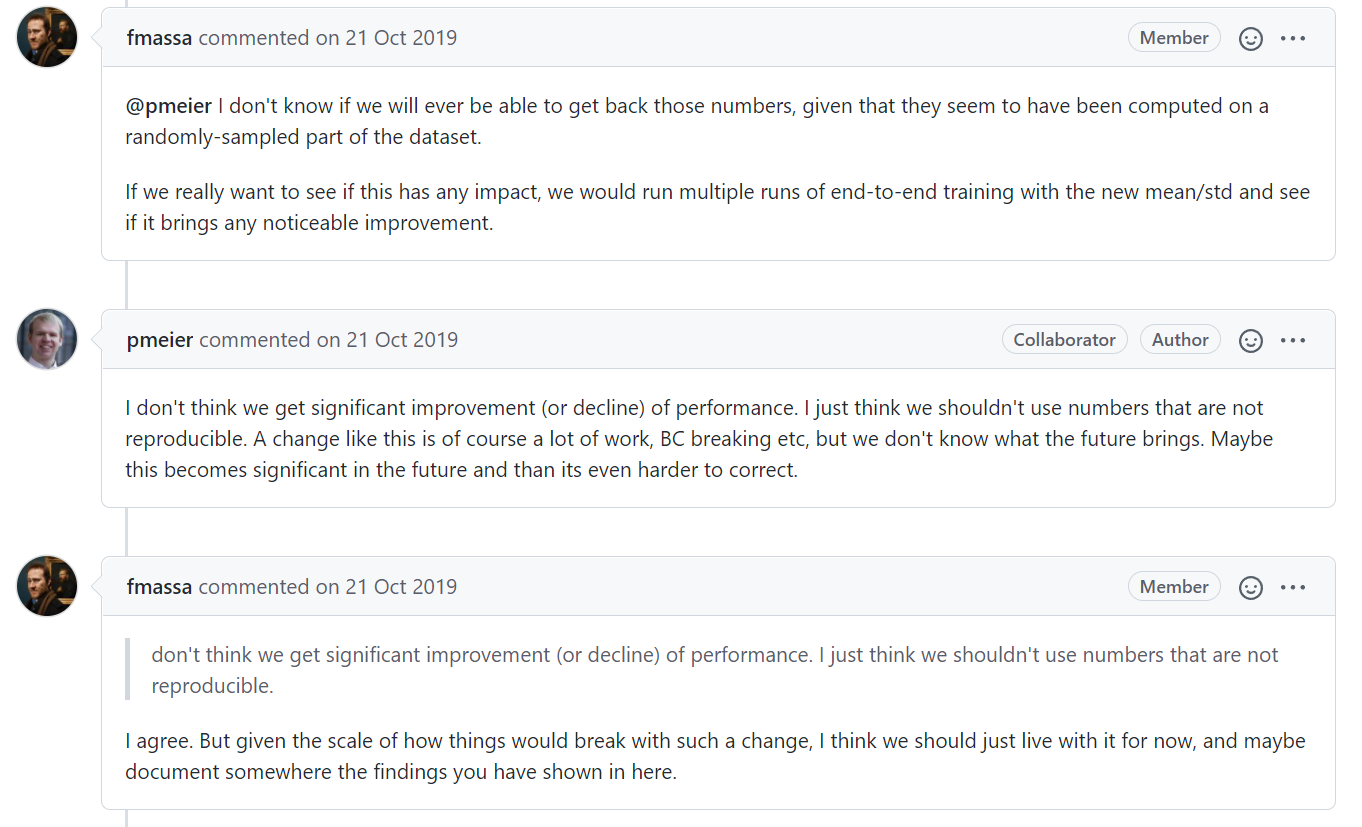
最后大家决定写个PR来记录和解释这个magic constant。

================================================
正是有了上面的讨论才有了下面的PR。
https://github.com/pytorch/vision/pull/1965

重点说明:
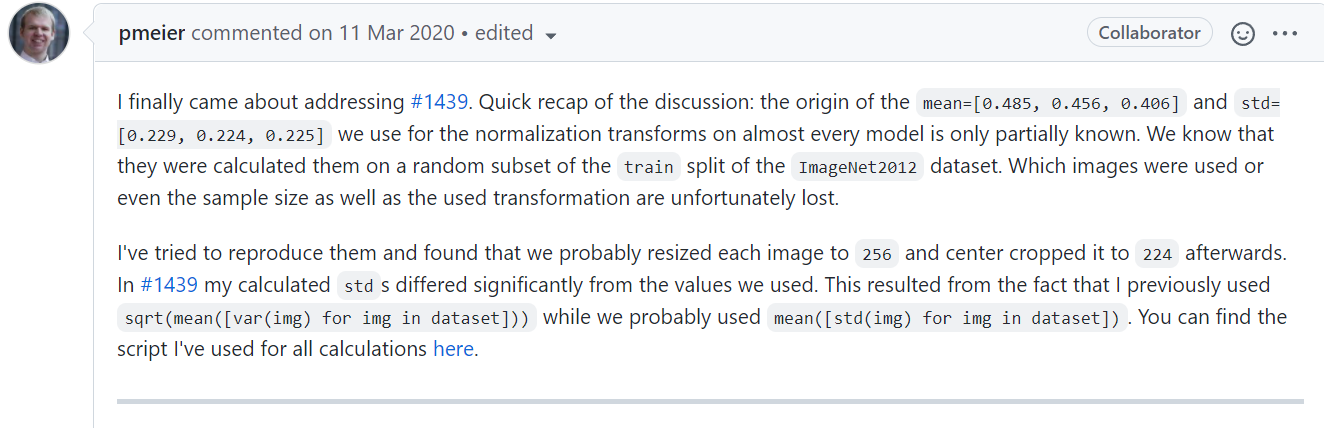
We know that they were calculated them on a random subset of the train split of the ImageNet2012 dataset. Which images were used or even the sample size as well as the used transformation are unfortunately lost.
同时作者对自己复现出的结果和原始结果的差距做了猜测和解释:
In #1439 my calculated stds differed significantly from the values we used. This resulted from the fact that I previously used sqrt(mean([var(img) for img in dataset])) while we probably used mean([std(img) for img in dataset]). You can find the script I've used for all calculations here.
作者在上一次复现的时候使用的代码:
sqrt(mean([var(img) for img in dataset]))
但是原始结果中的代码可能是:
mean([std(img) for img in dataset])
作者又给出了新的计算代码:
https://gist.github.com/pmeier/f5e05285cd5987027a98854a5d155e27

======================================================
在 https://github.com/pytorch/vision/issues/3657 中对原始预处理过程中的具体代码形式进行了讨论:

给出了具体的预处理数据的代码形式:
import torch
from torchvision import datasets, transforms as T
transform = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
dataset = datasets.ImageNet(".", split="train", transform=transform)
means = []
variances = []
for img in subset(dataset):
means.append(torch.mean(img))
variances.append(torch.std(img)**2)
mean = torch.mean(torch.stack(means), axis=0)
std = torch.sqrt(torch.mean(torch.stack(variances), axis=0))
============================================================