在深度学习的视觉领域中魔法常数一直都存在,而且一直在广泛应用,但是一直也都找不到它的出处,不经意间找到了它的出处。

相关地址:
https://pytorch.org/vision/stable/models.html
===========================================
本文主要介绍一下这个黄金魔法常数的应用之广。
mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]
===========================================
本文以国产深度学习框架mindspore举例:
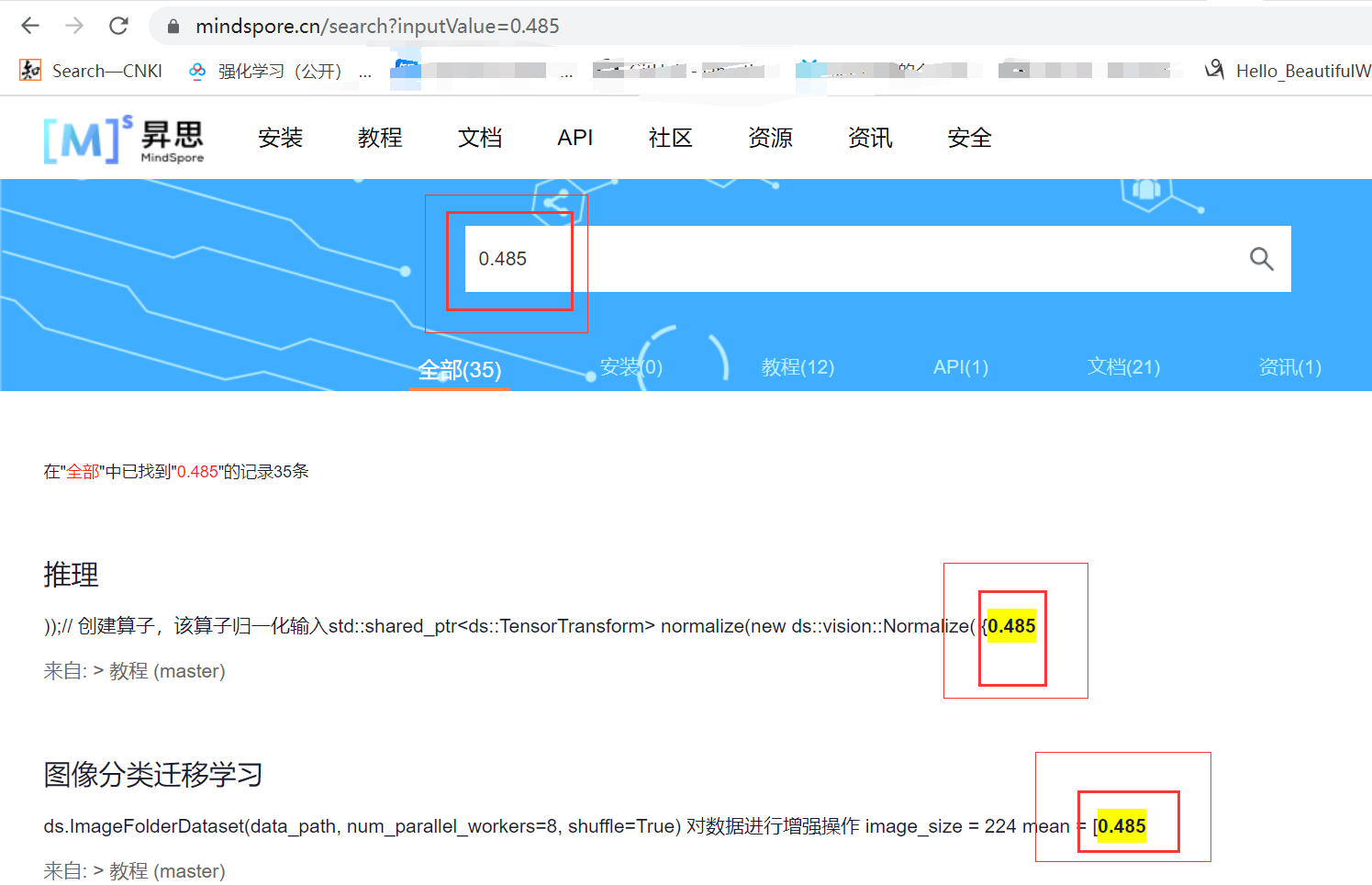
在很多VISION代码中进行数据正则化时甚至直接使用这个神奇常数而不加任何解释:
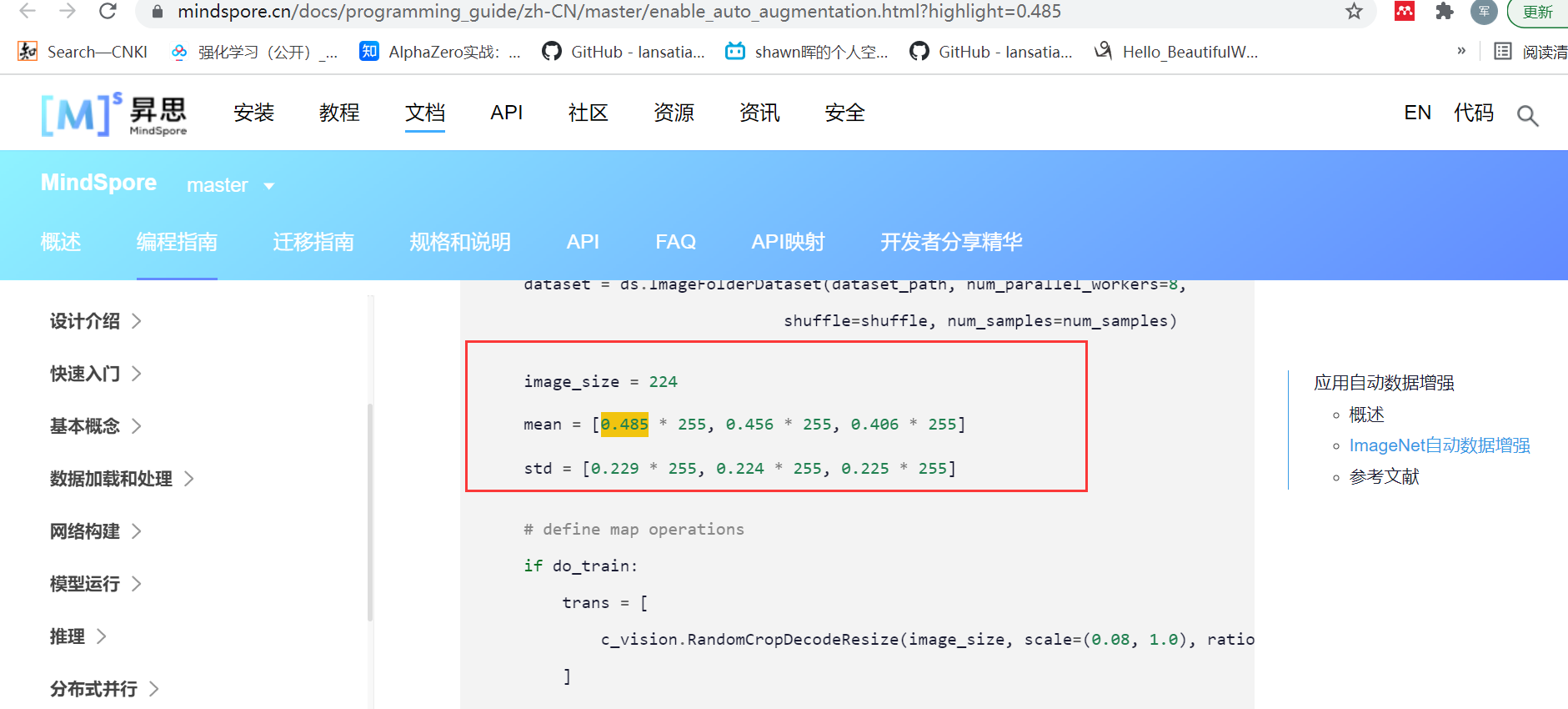
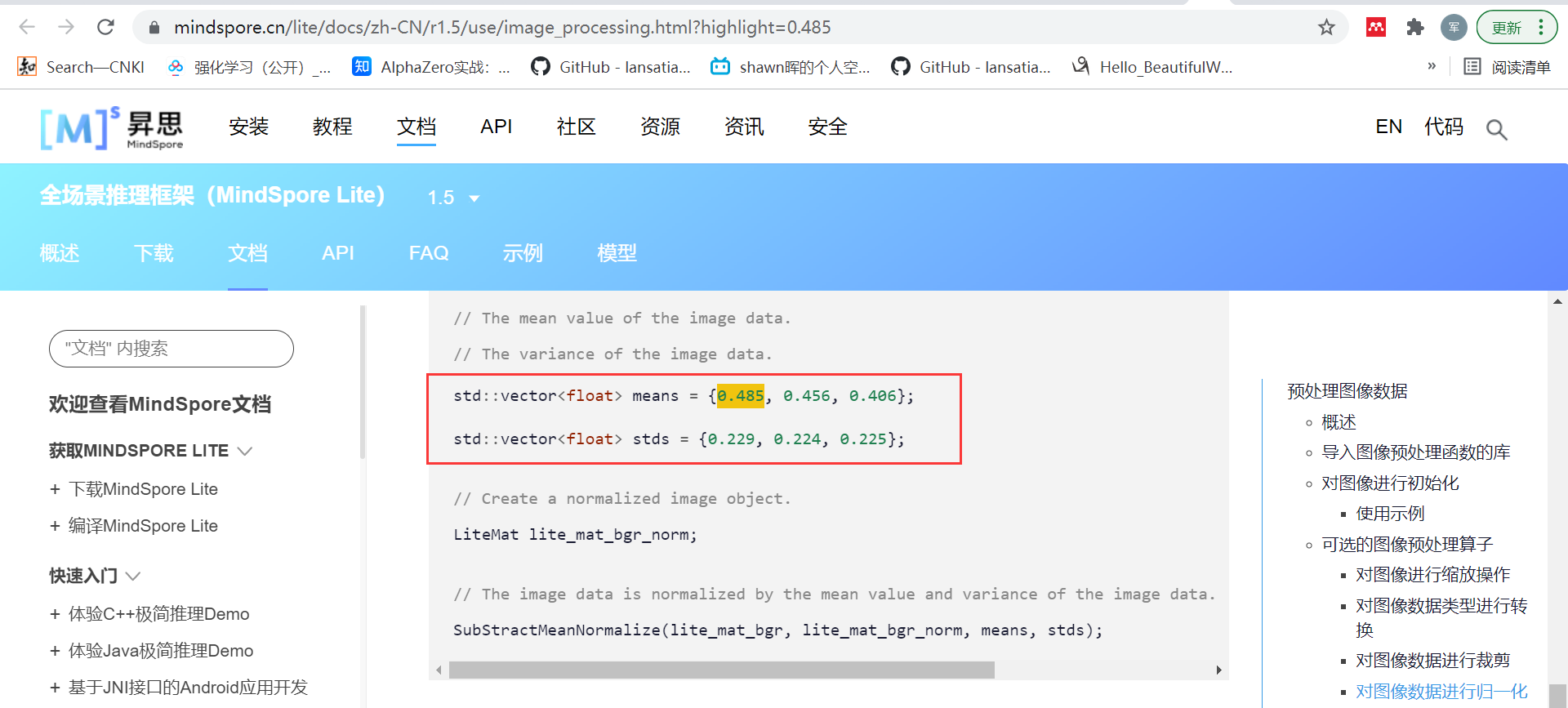
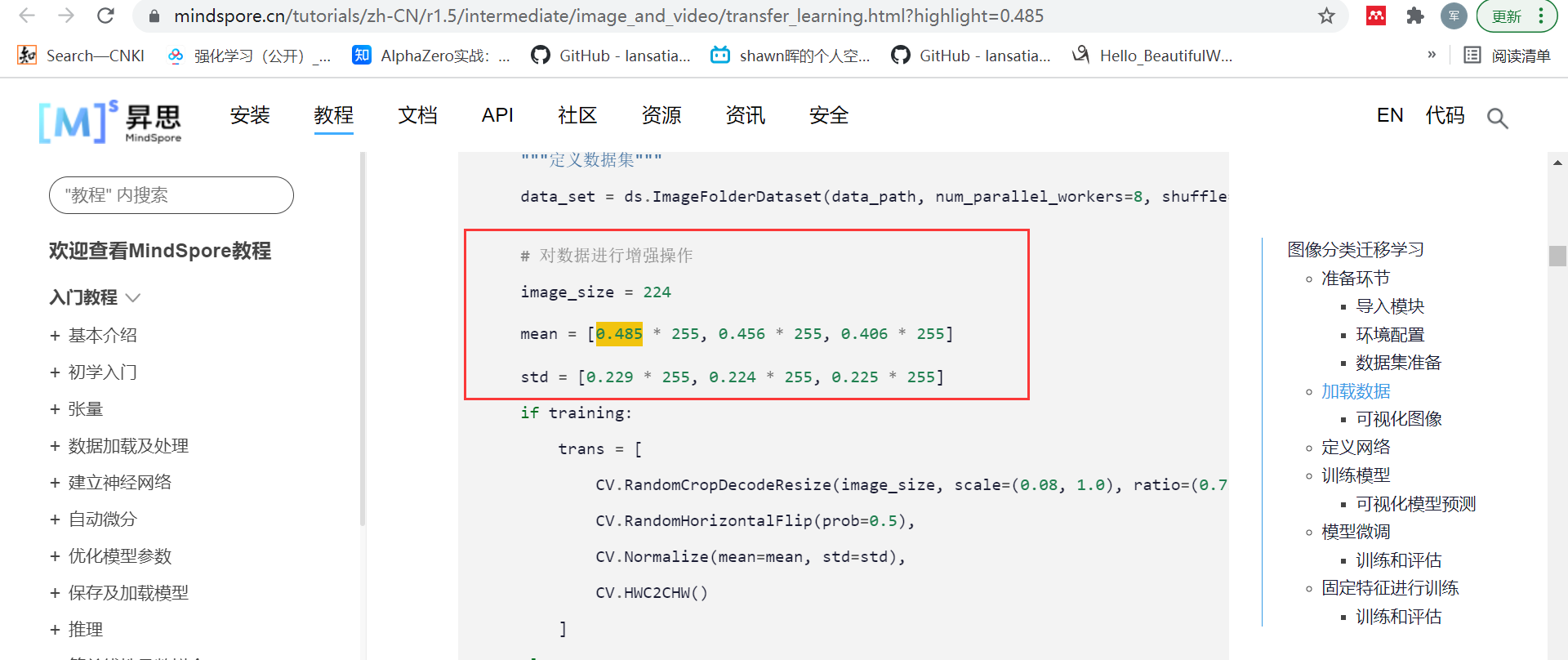
当然也有少数会说明下是在IMAGENET数据集下进行的数据正则化:
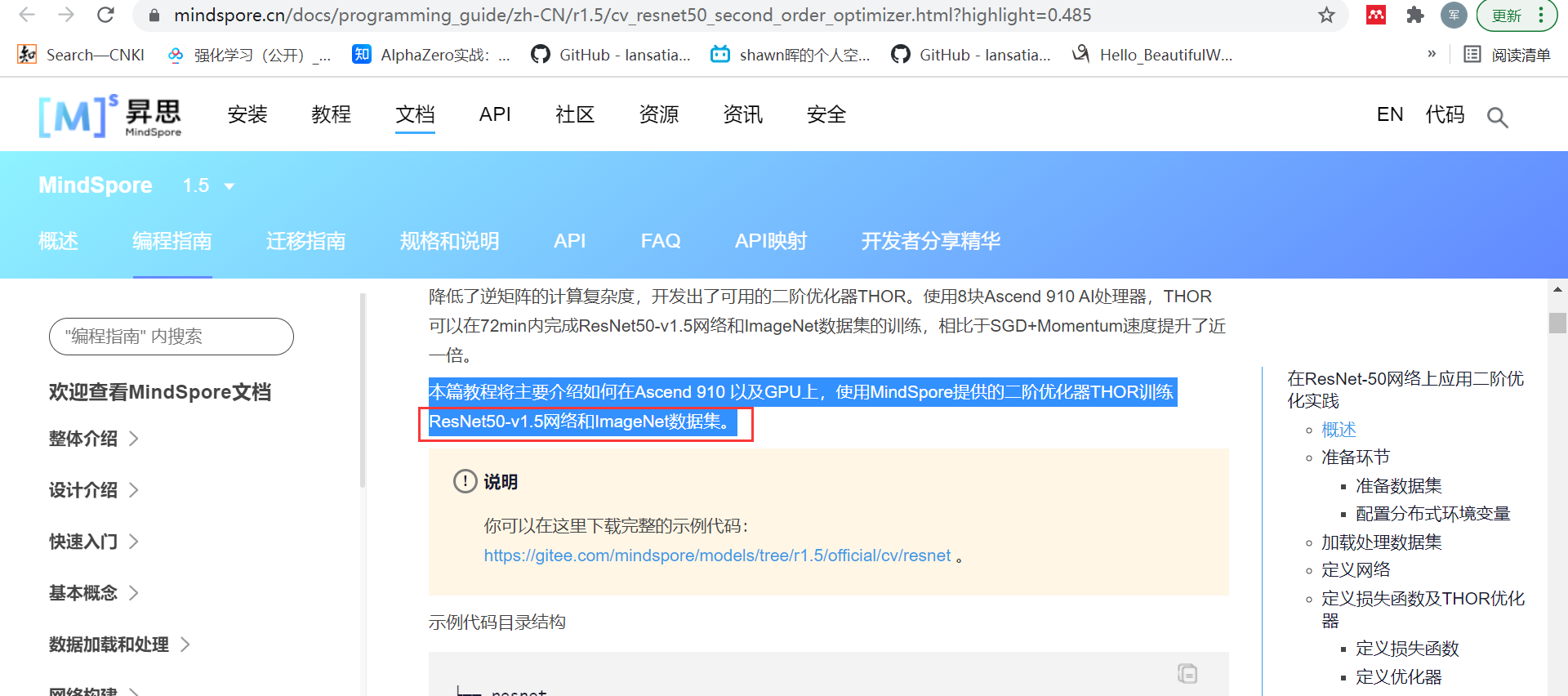
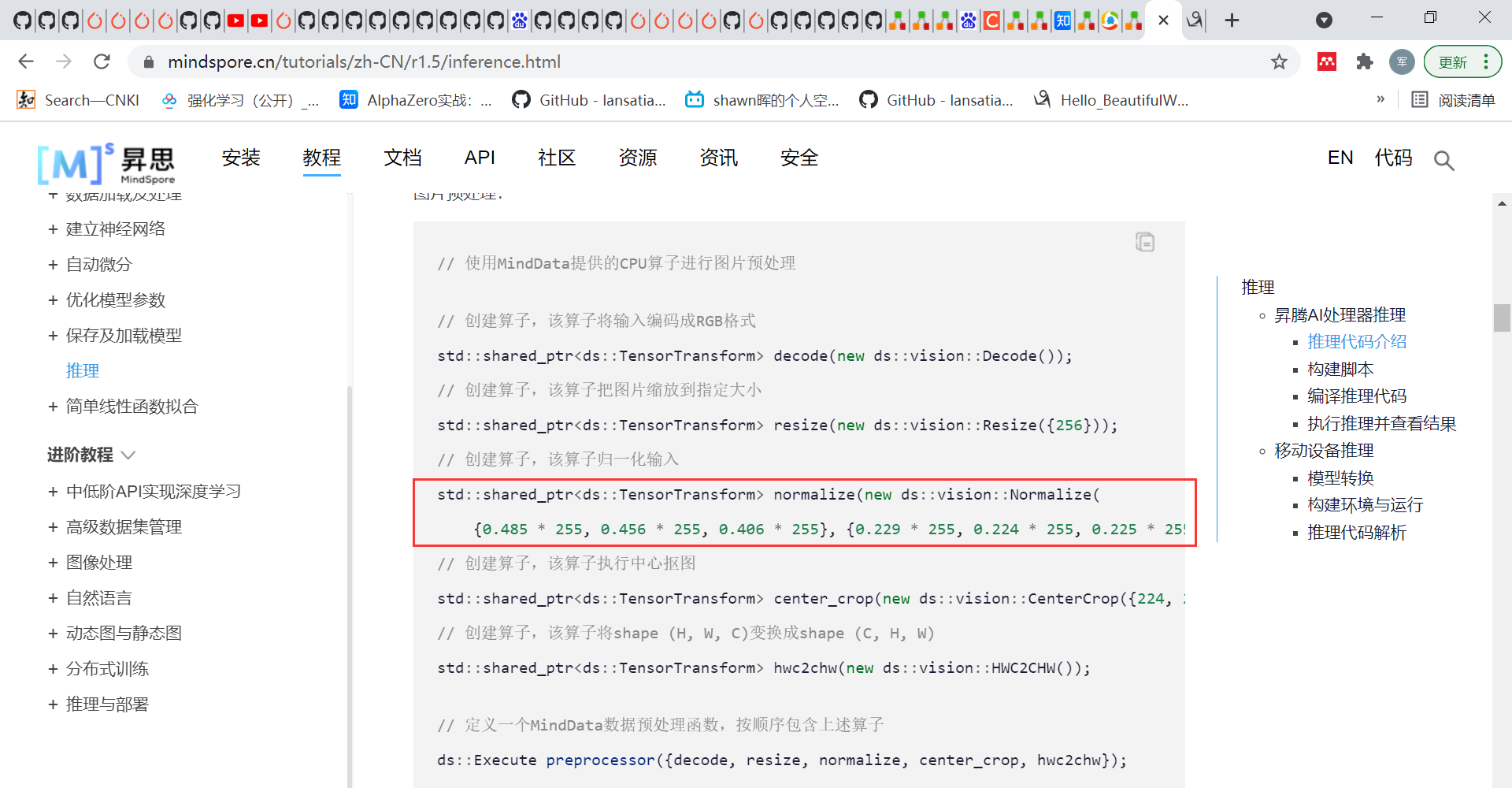
甚至在很多时候对数据的正则化采用magic constant已经成为了标配:
================================================
总的来说在VISION领域,在深度学习的视觉VISION领域数据预处理的魔法常数magic constant、黄金数值: mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]是十分常见的,甚至是标准配置,但是这是为什么呢?
其实在pytorch的官网教程中给出了解释,这个数字其实最早是pytorch官网对IMAGENET12数据集进行训练所使用的数据正则化设置,同时pytorch给出了自己使用该种设置训练好的多种模型参数,而如果使用这些训练好的模型参数进行再训练或迁移学习的话那么必须要依旧使用这个magic constant来对数据进行正则化,也就是说使用pytorch训练好的模型(这些模型训练的时候就是使用了magic constant),那么为了保证收敛性也必须要继续使用这个magic constant来对数据进行正则化,这样久而久之VISION数据集进行正则化时一般默认都是使用这个constant了,但是这其实是一个误区,这个magic constant其实只是对IMAGENET12数据集有效,或者说对pytorch给出的那些使用IMAGENET12数据集训练的模型参数才有效,如果你需要训练的是一个mnist手写数据集,而且使用的模型和参数不是pytorch给出的预训练好的,那么并不是一定要使用这个magic constant的。
在对MNIST数据集进行数据预处理时不使用MAGIC CONSTANT的例子:
https://www.mindspore.cn/tutorials/zh-CN/r1.5/dataset.html
https://www.mindspore.cn/tutorials/zh-CN/r1.5/quick_start.html
===================================================
总的来说这个MAGIC CONSTANT虽然成为了领域的标配,但这主要还是因为VISION领域重要的模型参数都是pytorch使用这个参数预训练好的,所以其他人要使用这个预训练好的模型参数也就只能接着使用这个MAGIC CONSTANT来做数据正则化了,久而久之很多新人反而不知道这个MAGIC CONSTANT的来历以及使用范围了,而那些老人虽然知道但是毕竟在这个新人剧增的时候也就是占很小比例的一部分了,所以对这个 mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225] 有些了解还是有些意义的。
===================================================