参考:
https://blog.csdn.net/qq_37189298/article/details/110945128
========================================
代码:
import torch from torch import cuda import time x = torch.zeros([1,1024,1024,128*2], requires_grad=True, device='cuda:0') print("1", cuda.memory_allocated()/1024**2) y = 5 * x # y.retain_grad() print("2", cuda.memory_allocated()/1024**2) torch.mean(y).backward() print("3", cuda.memory_allocated()/1024**2) print(cuda.memory_summary()) time.sleep(60)


可以看到pytorch占显存共4777MB空间,其中变量及缓存共占4096空间。可以知道其中1024MB空间为缓存,可以手动释放,改代码:
import torch from torch import cuda import time x = torch.zeros([1,1024,1024,128*2], requires_grad=True, device='cuda:0') print("1", cuda.memory_allocated()/1024**2) y = 5 * x # y.retain_grad() print("2", cuda.memory_allocated()/1024**2) torch.mean(y).backward() print("3", cuda.memory_allocated()/1024**2) torch.cuda.empty_cache() print(cuda.memory_summary()) time.sleep(60)

根据参考文章可知,1024*3MB是变量内存,其余700MB为其他内存,其中变量内存中有1024为x.grad,而且程序运行过程中显存分配峰值为4096MB,如下图:
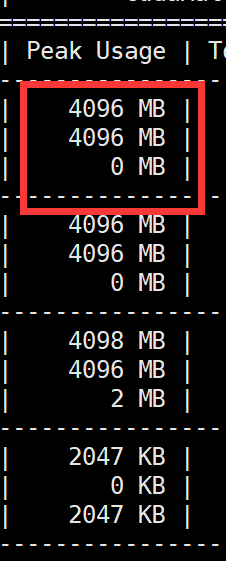
其中包括 x.grad 和 y.grad 各1024MB空间。
如果保存非叶子节点的grad值,即保存y.grad,运行:
import torch from torch import cuda import time x = torch.zeros([1,1024,1024,128*2], requires_grad=True, device='cuda:0') print("1", cuda.memory_allocated()/1024**2) y = 5 * x y.retain_grad() print("2", cuda.memory_allocated()/1024**2) torch.mean(y).backward() print("3", cuda.memory_allocated()/1024**2) torch.cuda.empty_cache() print(cuda.memory_summary()) time.sleep(60)
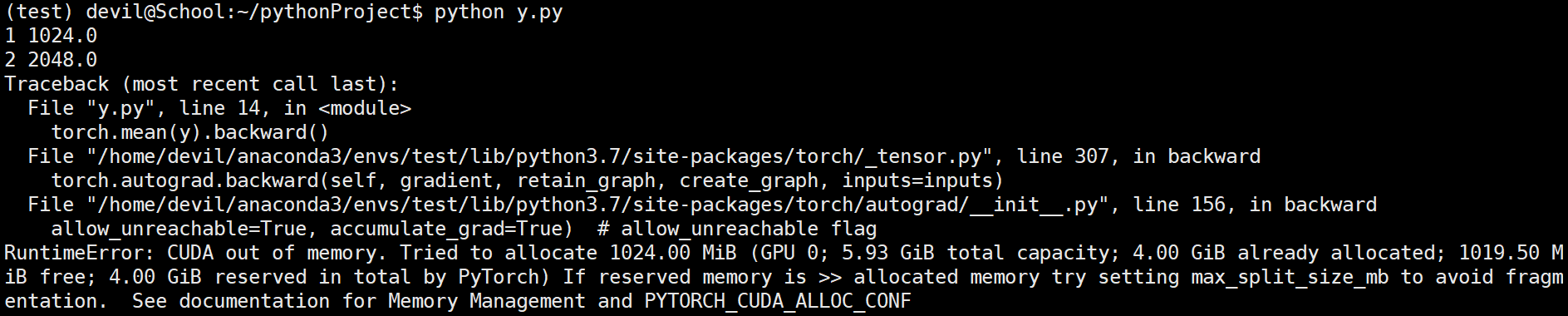
发现显存不够用了,也就是说保存y.grad后整体显存已经快达到5.9GB了,于是相同代码再Titan上运行:
发现总显存:
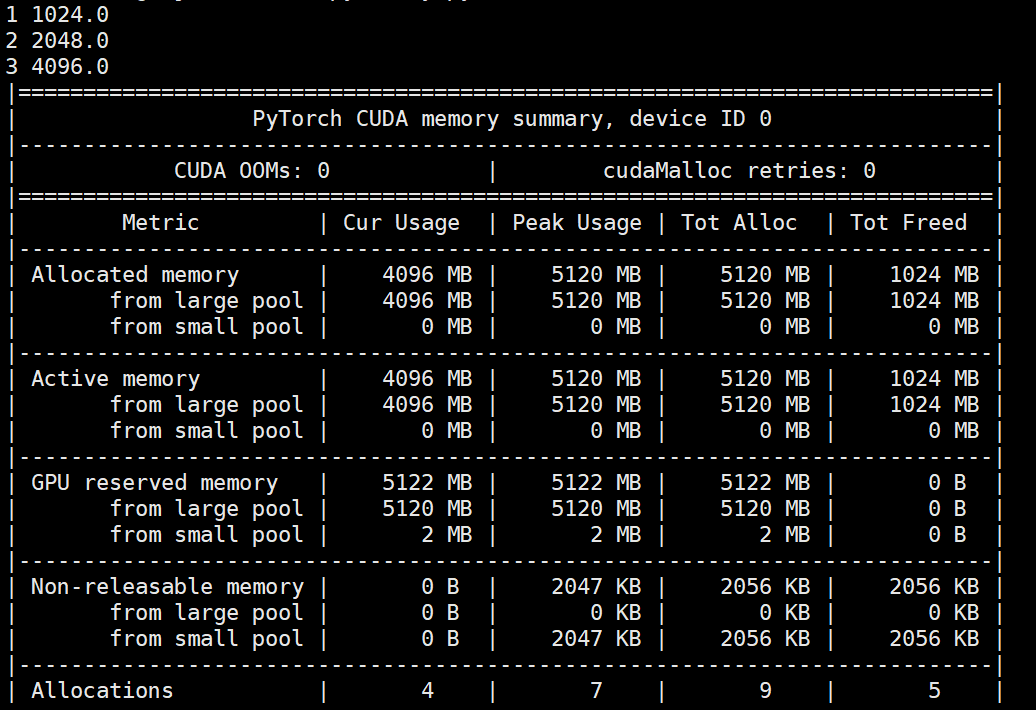
运行结果:
================================================
给出参考文章中给出的分析图:

一个个人体会就是如果是在多人使用共享显卡的时候,手动进行显存释放操作:
torch.cuda.empty_cache()
是非常不明智的,如果手动执行该操作后就把中间变量梯度给释放了,此时如果其他进程申请显存空间就有可能把刚才释放的那部分梯度的显存空间给占有了,如果原程序再次进行求梯度而此时系统显存已经不够就会导致系统崩溃。
======================================
不过对于原文的分析本人还是有一定的怀疑的,在泰坦上的运行代码和结果:
import torch from torch import cuda import time x = torch.ones([1,1024,1024,128*2], requires_grad=True, device='cuda:0') print("1", cuda.memory_allocated()/1024**2) y = 5 * x y.retain_grad() print("2", cuda.memory_allocated()/1024**2) print(cuda.memory_summary()) #time.sleep(30) torch.mean(y).backward() print("3", cuda.memory_allocated()/1024**2) # torch.cuda.empty_cache() print(cuda.memory_summary()) print(y.grad) print("."*100) print(x.grad) time.sleep(60)


=================================================
代码:
import torch from torch import cuda import time x = torch.ones([1,1024,1024,128*2], requires_grad=True, device='cuda:0') print("1", cuda.memory_allocated()/1024**2) y = 5 * x # y.retain_grad() print("2", cuda.memory_allocated()/1024**2) print(cuda.memory_summary()) #time.sleep(30) torch.mean(y).backward() print("3", cuda.memory_allocated()/1024**2) # torch.cuda.empty_cache() print(cuda.memory_summary()) print(y.grad) print("."*100) print(x.grad) time.sleep(60)


可以看到在titan显卡上如果保存y.grad,那么显存最后会保存5个1024MB的显存,其中,x,y,x.grad,y.grad变量各占1个1024MB显存,那多出的那1024MB显存又是怎么回事呢,这里假设这部分神奇缓存为X。
那么原文中如果不保存y.grad,那可能不可能是在y.grad的基础上进行in-replace操作呢,最后释放的缓存可能不可能是那个神奇X空间而不是y.grad空间呢,我想这也是有可能的。
个人还是比较支持 y.grad 空间被x.grad 空间覆盖这个观点的,至于多出来的1024MB的神奇X显存空间只能说这可能是pytorch在反向传导过程中求梯度隐含操作所产生的缓存空间。
========================================================