参考:
https://cloud.tencent.com/developer/article/1626387
据说在pytorch中使用torch.cuda.empty_cache()可以释放缓存空间,于是做了些尝试:
上代码:
import torch import time import os #os.environ["CUDA_VISIBLE_DEVICES"] = "3" device='cuda:2' dummy_tensor_4 = torch.randn(120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1024/1024 = 360.0M memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第一阶段:") print("变量类型:", dummy_tensor_4.dtype) print("变量实际占用内存空间:", 120*3*512*512*4/1024/1024, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") torch.cuda.empty_cache() time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第二阶段:") print("释放缓存后:", "."*100) print("变量实际占用内存空间:", 120*3*512*512*4/1024/1024, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") del dummy_tensor_4 torch.cuda.empty_cache() time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第三阶段:") print("删除变量后释放缓存后:", "."*100) print("变量实际占用内存空间:", 0, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") time.sleep(60)
运行结果:

第一阶段:

第二阶段:

第三阶段:

===================================================
可以看到在pytorch中显存创建360M的变量其实总占有了1321M空间,其中变量自身占了360M空间,缓存也占了360M空间,中间多出了那1321-360*2=601M空间却无法解释,十分诡异。
总的来说 torch.cuda.empty_cache() 操作有一定用处,但是用处不太大。
===================================================
更改代码:
import torch import time import os #os.environ["CUDA_VISIBLE_DEVICES"] = "3" device='cuda:2' dummy_tensor_4 = torch.randn(120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1024/1024 = 360.0M dummy_tensor_5 = torch.randn(120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1024/1024 = 360.0M memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第一阶段:") print("变量类型:", dummy_tensor_4.dtype) print("变量实际占用内存空间:", 2*120*3*512*512*4/1024/1024, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") torch.cuda.empty_cache() time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第二阶段:") print("释放缓存后:", "."*100) print("变量实际占用内存空间:", 2*120*3*512*512*4/1024/1024, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") del dummy_tensor_4 del dummy_tensor_5 torch.cuda.empty_cache() time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第三阶段:") print("删除变量后释放缓存后:", "."*100) print("变量实际占用内存空间:", 0, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") time.sleep(60)
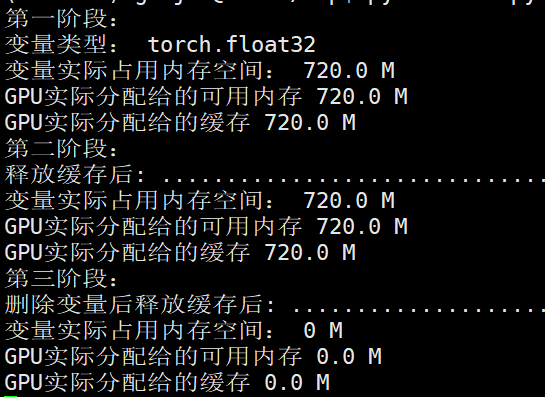
第一阶段:

第二阶段:

第三阶段:

发现依然有显存空间无法解释。
=============================================
上面的操作都是在24G显存的titan上进行的,最后决定用1060显卡试验下,6G显存比较好尝试。
代码:
import torch import time import os import functools #os.environ["CUDA_VISIBLE_DEVICES"] = "3" device='cuda:0' shape_ = (4, 1024, 512, 512) # 4GB # dummy_tensor_4 = torch.randn(120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1024/1024 = 360.0M # dummy_tensor_5 = torch.randn(10, 120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1024/1024 = 360.0M dummy_tensor_6 = torch.randn(*shape_).float().to(device) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第一阶段:") print("变量类型:", dummy_tensor_6.dtype) print("变量实际占用内存空间:", functools.reduce(lambda x, y: x*y, shape_)*4/1024/1024, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") torch.cuda.empty_cache() time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第二阶段:") print("释放缓存后:", "."*100) print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") del dummy_tensor_6 torch.cuda.empty_cache() time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第三阶段:") print("删除变量后释放缓存后:", "."*100) print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") time.sleep(60)
输出结果:
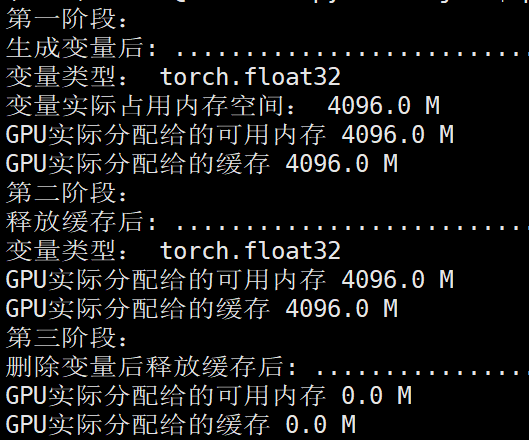
第一阶段:

第二阶段:

第三阶段:

由于显卡总共6G显存,所以
memory_allocated
memory_reserved
这两部分应该是指的相同显存空间,因为这两个部分都是显示4G空间,总共6G空间。
可以看到单独执行:torch.cuda.empty_cache()
并没有释放显存,还是4775MB,但是执行:
del dummy_tensor_6
torch.cuda.empty_cache()
显存就进行了释放,为679MB。
更改代码:
import torch import time import os import functools #os.environ["CUDA_VISIBLE_DEVICES"] = "3" device='cuda:0' shape_ = (4, 1024, 512, 512) # 4GB # dummy_tensor_4 = torch.randn(120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1024/1024 = 360.0M # dummy_tensor_5 = torch.randn(10, 120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1024/1024 = 360.0M dummy_tensor_6 = torch.randn(*shape_).float().to(device) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第一阶段:") print("生成变量后:", "."*100) print("变量类型:", dummy_tensor_6.dtype) print("变量实际占用内存空间:", functools.reduce(lambda x, y: x*y, shape_)*4/1024/1024, "M") print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") torch.cuda.empty_cache() time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第二阶段:") print("释放缓存后:", "."*100) print("变量类型:", dummy_tensor_6.dtype) print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") # for _ in range(10000): # dummy_tensor_6 += 0.001 # print(torch.sum(dummy_tensor_6)) del dummy_tensor_6 time.sleep(15) memory_allocated = torch.cuda.memory_allocated(device)/1024/1024 memory_reserved = torch.cuda.memory_reserved(device)/1024/1024 print("第三阶段:") print("删除变量后释放缓存后:", "."*100) print("GPU实际分配给的可用内存", memory_allocated, "M") print("GPU实际分配给的缓存", memory_reserved, "M") time.sleep(60)
运行结果:
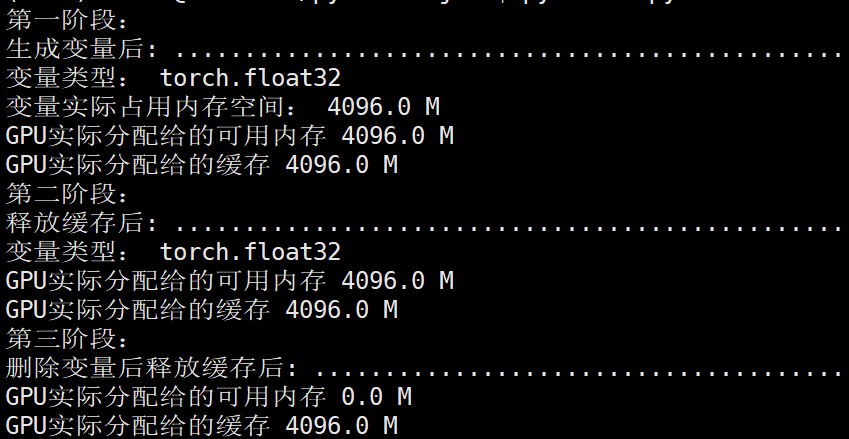
NVIDIA显存显示第一,二,,三阶段均为:
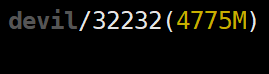
如果没有执行torch.cuda.empty_cache(),即使删除GPU上的变量显存空间也不会被释放,该部分显存还为缓存空间所占。
================================================
总结:
torch.cuda.memory_reserved() 表示进程所获得分配到总显存大小(包括变量显存和缓存等)
torch.cuda.memory_allocated 表示进程为变量所分配的显存大小
torch.cuda.memory_reserved() - torch.cuda.memory_allocated
表示进程中空闲的显存空间,一般是指进程显存中缓存空间的大小。(不是GPU空闲显存空间,而是进程已获得的显存中未被使用的空间)
================================================