本篇博客是前篇博客并行化强化学习 —— 初探 —— 并行reinforce算法的尝试 (上篇:强化学习在多仿真环境下单步交互并行化设计的可行性)的继续,文中代码地址为:https://gitee.com/devilmaycry812839668/Parallelism_Reinforce_CartPole 。
---------------------------------------------------------------
上篇我们讨论了强化学习在多仿真环境下单步交互并行化设计的可行性,但是其中我们考虑的环境都是小规模的环境,这里我们考虑的是大规模的环境,大规模环境其简单的理解就是环境数量规模较大,在前文的基础上我们在mode=1的算法设计上采用大规模的环境数同时保持程序的并发度保持不变或较少的变化(之所以这里选择不大幅度调整并行程度是因为由于计算机硬件的限制,毕竟是家用级别的电脑,性能是有较低上限的)
本文讨论的是第四种设计,即:强化学习在大规模仿真环境下单步交互并行化设计,设计的标号为 mode=3。
其中, 在 processes_number=4 ,envs_number=128 时的具体运行代码:
python PolicyNetwork_version.py --mode=3 --processes_number=4 --envs_number=128
====================================================
对 mode=3 情况下进行测试,结果如下:
运行所需训练的episodes个数:(analysis.py)
envs_number_64/processes_4: mean: 321777.0000 std: 33583.6198 共解决任务数: 50 envs_number_128/processes_4: mean: 316720.0000 std: 31296.9040 共解决任务数: 50 envs_number_256/processes_4: mean: 323098.0000 std: 34588.5284 共解决任务数: 50 envs_number_512/processes_4: mean: 334613.0000 std: 36714.9299 共解决任务数: 50 envs_number_1024/processes_4: mean: 323867.0000 std: 37091.7978 共解决任务数: 50 envs_number_2048/processes_4: mean: 324296.0000 std: 33338.7835 共解决任务数: 50 envs_number_4096/processes_4: mean: 333363.0000 std: 31345.0344 共解决任务数: 50 envs_number_8192/processes_4: mean: 311045.0000 std: 29589.0541 共解决任务数: 50 envs_number_2048/processes_1: mean: 323145.2381 std: 36678.6963 共解决任务数: 42 envs_number_2048/processes_4: mean: 324296.0000 std: 33338.7835 共解决任务数: 50 envs_number_2048/processes_8: mean: 333463.2653 std: 34431.7749 共解决任务数: 49 envs_number_4096/processes_1: mean: 326543.0000 std: 30094.9913 共解决任务数: 50 envs_number_4096/processes_4: mean: 333363.0000 std: 31345.0344 共解决任务数: 50 envs_number_4096/processes_8: mean: 328517.0000 std: 33350.8990 共解决任务数: 50 envs_number_8192/processes_1: mean: 338575.0000 std: 38073.1062 共解决任务数: 38 envs_number_8192/processes_4: mean: 311045.0000 std: 29589.0541 共解决任务数: 50 envs_number_8192/processes_8: mean: 396648.5714 std: 27450.9497 共解决任务数: 35
运行时间:(analysis_2.py)
envs_number_64/processes_4: mean: 526.7796 std: 126.2644 共解决任务数: 50 envs_number_128/processes_4: mean: 394.2612 std: 67.4358 共解决任务数: 50 envs_number_256/processes_4: mean: 332.7999 std: 53.1085 共解决任务数: 50 envs_number_512/processes_4: mean: 316.8702 std: 52.2924 共解决任务数: 50 envs_number_1024/processes_4: mean: 285.3062 std: 51.4774 共解决任务数: 50 envs_number_2048/processes_4: mean: 281.6246 std: 46.0122 共解决任务数: 50 envs_number_4096/processes_4: mean: 295.1882 std: 43.0754 共解决任务数: 50 envs_number_8192/processes_4: mean: 257.8469 std: 39.6341 共解决任务数: 50 envs_number_2048/processes_1: mean: 832.0377 std: 137.5005 共解决任务数: 42 envs_number_2048/processes_4: mean: 281.6246 std: 46.0122 共解决任务数: 50 envs_number_2048/processes_8: mean: 260.4818 std: 40.7339 共解决任务数: 49 envs_number_4096/processes_1: mean: 858.8439 std: 116.5244 共解决任务数: 50 envs_number_4096/processes_4: mean: 295.1882 std: 43.0754 共解决任务数: 50 envs_number_4096/processes_8: mean: 227.1919 std: 34.7875 共解决任务数: 50 envs_number_8192/processes_1: mean: 909.0905 std: 151.6751 共解决任务数: 38 envs_number_8192/processes_4: mean: 257.8469 std: 39.6341 共解决任务数: 50 envs_number_8192/processes_8: mean: 231.7492 std: 23.7098 共解决任务数: 35
说明:每组实验计划都是进行50次的,都是由于运行时间过长所以部分实验并没有做够50次,这也就出现了部分共解决任务不足50的情况,不过即使这样每个类型的设置做的试验也是足够多了。
根据上面的结果,我们可以看到不管是哪种设置最终算法都需要进行330000个episodes的训练,上面的试验中batch_size均设置为50,也就是说哪种设置对策略网络的训练次数或者说更新次数基本上是相同的。但是如果并行的环境数和进程数设置的共同很大时,导致整个算法中总的并行环境数过大,如prcocesses_number=8, envs_number=8192, 整个环境数为8*8192=65536,明显需要的episodes数有了一定幅度的增加,这说明如果环境数过大时往往会导致训练的不稳定,反而需要更多次的网络训练更新。
同时我们可以看到并行的环境数和并行的进程数都不是越多越好的,当进程数达到一定数值时对运行速度的提升并不明显,同时如果并行的环境数到达一定数量后在继续增加对运行速度的提升也并不明显。由于并行化实际上是在增加系统中某个待训练策略的可用训练数据的数量,但是该策略网络本身的训练速度和性能是有上限的,所以没必要一味的加大系统中的并行环境数和进程数,在环境数和进程数到达一定程度后对性能的提升不明显,对运行速度的提升也不明显,因为这样虽然增加了策略网络训练时的所能利用的数据数量但是达到它本身最大所需数量后运算时间是无法继续提升的,并行算法的本质就是尽量保证策略训练网络不需要等待数据的生成,因此达到这个目标就可以了,如果再继续增加数据的生成会导致数据的积压,也就是拉远了策略网络和生成的数据的分布,反而造成了训练的不稳定行。
总的说来,就是并行强化学习确实有用,可以有效提高算法的性能,但是其提升也是有上限的,过大的并行化反而会造成算法性能的衰退。建议并行进程数为当前计算设备的CPU核心数量,并行环境数设置为32,64,128,256,512几种。
上面实验环境(硬件):
i7-9700k,CPU锁频4.9Ghz, GPU:2060super
--------------------------------------------------------
后来又在一个3.6Ghz主频的服务器上运行,给出实验的结果:(batch_size均为50episodes,分别进行了2000次试验)
PolicyNetwork_version.py --mode=3 --processes_number=1 --envs_number=50000

结果的第一行表示总共参与计算的episodes个数,第二行表示运算的时间(单位:秒)。
PolicyNetwork_version.py --mode=3 --processes_number=1 --envs_number=128
结果的第一行表示总共参与计算的episodes个数,第二行表示运算的时间(单位:秒)。

分析:
根据实验,我们可以看到并行的环境数设置为128和50000时,运行时间和需要进行的策略网络更新次数相差不大。可以看到当envs_number设置为50000时所需要的episodes个数要多于envs_number=128时的时候,这种情况应该是由于环境数过多导致训练数据与策略网络分布的差距较大,因此影响了训练的稳定性,因此需要更多的训练次数,但是同时我们也可以看到虽然batch_size=50000时训练次次数多了,但是训练的时间反而减少了,这说明envs_number增加后提高了数据生成的效率,加快了数据生成的速度也就减少了训练策略网络时对数据的等待造成的空载时间,从而提高了运算速度。总之,过大的提高环境数,可以一定程度提高运算速度,但是需要牺牲一定的训练稳定度,由于训练稳定性如果过差的话就会造成训练策略的衰退,因此对于训练速度来说训练的稳定性更加重要,由此我们需要在训练速度和稳定性上来做权衡,因此不建议把环境数设置的过大,本文的实验环境下256个环境数就可以得到不错的结果,环境数为50000就不是很必要了,虽然本文环境下设环境数50000也是收敛的但这并不通用,设置为128,256,512,甚至是1024作为环境个数也都是比较通用的设置,建议的设置。
---------------------------------
当并行的环境数设置为极大值时,如envs_number=500000,发现算法无法取得要求的结果,进入衰退:(算法稳定性很重要,不建议大环境数的设置)
prcocesses_number=1, envs_number=500000, 共进行了12次试验,0次收敛,12次衰退,有效率0%。
--------------------------------
为了极限测评,在3.6Ghz主频服务上,测试多进程并行的情况:
500进程并行:
export CUDA_VISIBLE_DEVICES=-1 && python -u PolicyNetwork_version.py --mode=3 --processes_number=500 --envs_number=1
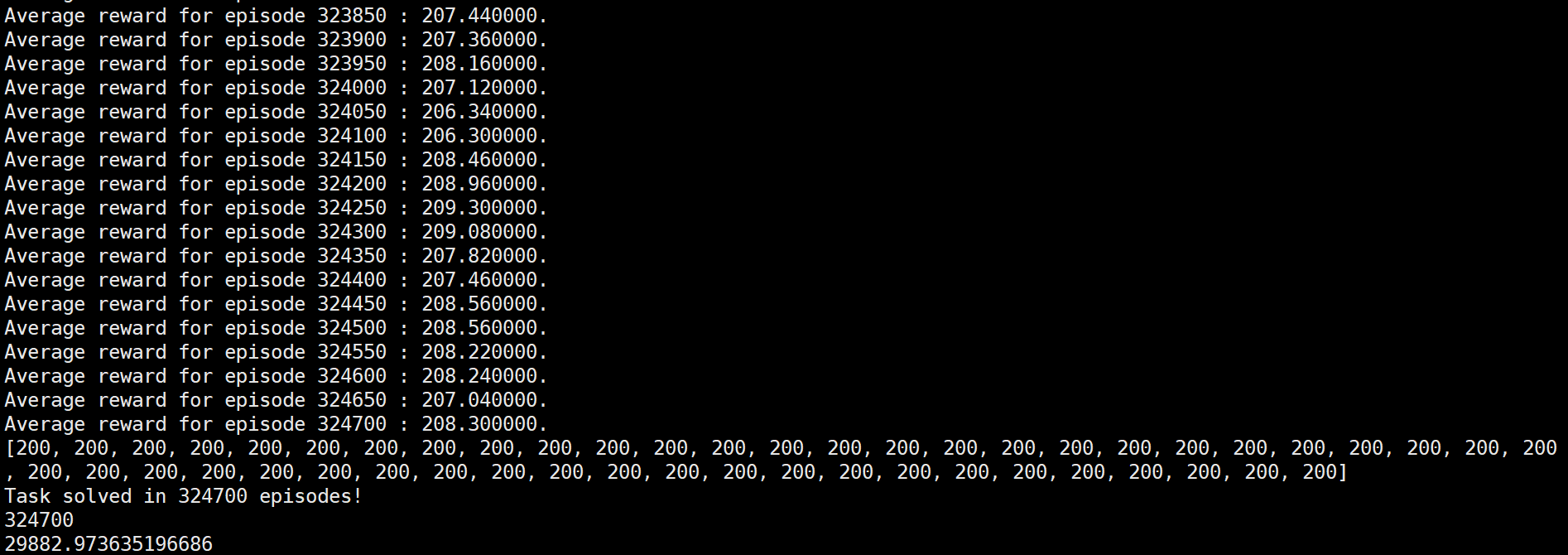
1000进程并行:
export CUDA_VISIBLE_DEVICES=-1 && python -u PolicyNetwork_version.py --mode=3 --processes_number=1000 --envs_number=1
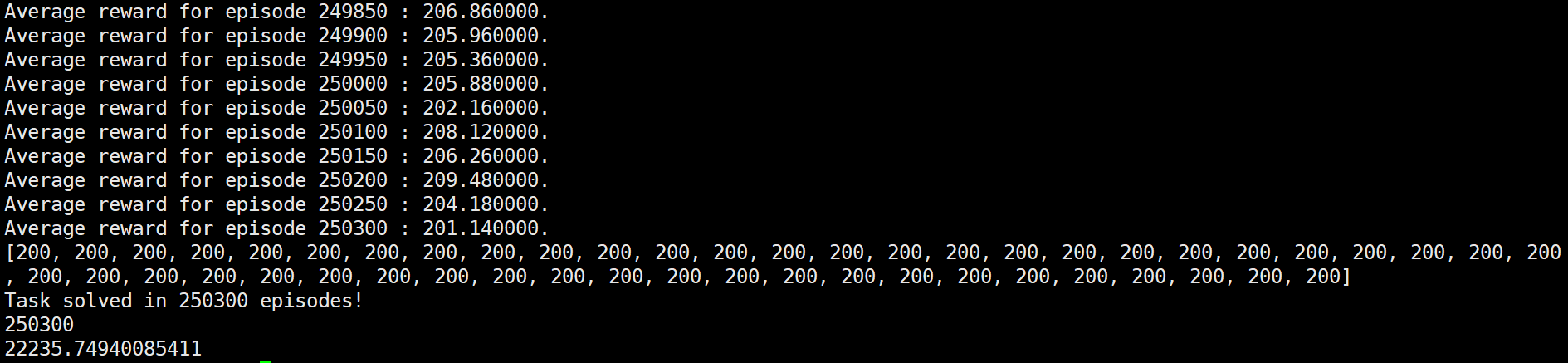
发现500进程和1000进程情况下,算法都取得了正常结果,在500进程时需要的策略网络训练更新次数和其他测试情况相仿,均在330000episodes上下,而进程为1000时策略网络训练更新次数有所减少,总的episodes数在250000左右。不论是500进程还是1000进程情况下总的运行时间都答复增加,有了近10多倍的时间增加,这说明进程过多后导致系统在调配进程上花费的时间将大幅增加,反而影响了算法的运行时间。
--------------------------------------------------------------
后补充的试验结果:(i7-9700k cpu上)
batch_size=50, mode=3
训练共需的episodes个数:
envs_number_8/processes_4: mean: 303500.0000 std: 29027.9714 共解决任务数: 8 envs_number_64/processes_4: mean: 321777.0000 std: 33583.6198 共解决任务数: 50 envs_number_128/processes_4: mean: 316720.0000 std: 31296.9040 共解决任务数: 50 envs_number_256/processes_4: mean: 323098.0000 std: 34588.5284 共解决任务数: 50 envs_number_512/processes_4: mean: 334613.0000 std: 36714.9299 共解决任务数: 50 envs_number_1024/processes_4: mean: 323867.0000 std: 37091.7978 共解决任务数: 50 envs_number_2048/processes_4: mean: 324296.0000 std: 33338.7835 共解决任务数: 50 envs_number_4096/processes_4: mean: 333363.0000 std: 31345.0344 共解决任务数: 50 envs_number_8192/processes_4: mean: 311045.0000 std: 29589.0541 共解决任务数: 50 envs_number_2048/processes_1: mean: 323701.0000 std: 37681.4072 共解决任务数: 50 envs_number_2048/processes_4: mean: 324296.0000 std: 33338.7835 共解决任务数: 50 envs_number_2048/processes_8: mean: 334348.0000 std: 34643.7757 共解决任务数: 50 envs_number_4096/processes_1: mean: 326543.0000 std: 30094.9913 共解决任务数: 50 envs_number_4096/processes_4: mean: 333363.0000 std: 31345.0344 共解决任务数: 50 envs_number_4096/processes_8: mean: 328517.0000 std: 33350.8990 共解决任务数: 50 envs_number_4096/processes_12: mean: 350911.0000 std: 57265.3083 共解决任务数: 50 envs_number_4096/processes_16: mean: 397040.0000 std: 19373.8690 共解决任务数: 50 envs_number_8192/processes_1: mean: 337009.0000 std: 37324.6523 共解决任务数: 50 envs_number_8192/processes_4: mean: 311045.0000 std: 29589.0541 共解决任务数: 50 envs_number_8192/processes_8: mean: 395599.0000 std: 25855.4085 共解决任务数: 50
训练共需运行的时间:
envs_number_8/processes_4: mean: 1676.1162 std: 236.4164 共解决任务数: 8 envs_number_64/processes_4: mean: 526.7796 std: 126.2644 共解决任务数: 50 envs_number_128/processes_4: mean: 394.2612 std: 67.4358 共解决任务数: 50 envs_number_256/processes_4: mean: 332.7999 std: 53.1085 共解决任务数: 50 envs_number_512/processes_4: mean: 316.8702 std: 52.2924 共解决任务数: 50 envs_number_1024/processes_4: mean: 285.3062 std: 51.4774 共解决任务数: 50 envs_number_2048/processes_4: mean: 281.6246 std: 46.0122 共解决任务数: 50 envs_number_4096/processes_4: mean: 295.1882 std: 43.0754 共解决任务数: 50 envs_number_8192/processes_4: mean: 257.8469 std: 39.6341 共解决任务数: 50 envs_number_2048/processes_1: mean: 830.2081 std: 143.7839 共解决任务数: 50 envs_number_2048/processes_4: mean: 281.6246 std: 46.0122 共解决任务数: 50 envs_number_2048/processes_8: mean: 263.6988 std: 46.1861 共解决任务数: 50 envs_number_4096/processes_1: mean: 858.8439 std: 116.5244 共解决任务数: 50 envs_number_4096/processes_4: mean: 295.1882 std: 43.0754 共解决任务数: 50 envs_number_4096/processes_8: mean: 227.1919 std: 34.7875 共解决任务数: 50 envs_number_4096/processes_12: mean: 212.8947 std: 52.4886 共解决任务数: 50 envs_number_4096/processes_16: mean: 208.0952 std: 35.2886 共解决任务数: 50 envs_number_8192/processes_1: mean: 904.2129 std: 150.0643 共解决任务数: 50 envs_number_8192/processes_4: mean: 257.8469 std: 39.6341 共解决任务数: 50 envs_number_8192/processes_8: mean: 233.0773 std: 23.6474 共解决任务数: 50
----------------------------------------