本文的相关链接:
github上DQN代码的环境搭建,及运行(Human-Level Control through Deep Reinforcement Learning)conda配置
------------------------------------------------------------------
经验池的引入算是DQN算法的一个重要贡献,而且experience replay buffer本身也是算法中比较核心的部分,并且该部分实现起来也是比较困难的,尤其是一个比较好的、速度不太慢的实现。为此,在本博客介绍下相关的实现方法,并且给出了三种不同的变体,对不同变体测试并分析运行性能。
本文所介绍的experience replay buffer的最原始实现为:
Code from https://github.com/tambetm/simple_dqn/blob/master/src/replay_memory.py
在原始代码上进行了一些微调,得到第一种变体,如下:


# encoding:UTF-8 """Code from https://github.com/tambetm/simple_dqn/blob/master/src/replay_memory.py""" import random import numpy as np class ReplayBuffer(object): def __init__(self, config): self.cnn_format = config.cnn_format # buffer中数据的格式,'NCHW'或'NHWC' self.buffer_size = config.replay_buffer_size # 缓存池的最大容量 self.history_length = config.history_length # 一个状态,state的历史数据长度 self.dims = (config.screen_height, config.screen_width) # 一帧图像的高、宽 self.batch_size = config.batch_size # mini_batch_size 大小 self.count = 0 # 当前缓存池中现有存储数据的大小 self.current = 0 # 指针指向的索引号,下一帧新数据存储的位置 """ expericence replay buffer 定义经验池 pre_state->a,r,s,terminal """ self.actions = np.empty(self.buffer_size, dtype=np.uint8) self.rewards = np.empty(self.buffer_size, dtype=np.int8) # 这里我们设定reward为:0,+1,-1,三个种类 self.screens = np.empty((self.buffer_size, config.screen_height, config.screen_width), dtype=np.float32) # 设定屏幕截图汇总,states self.terminals = np.empty(self.buffer_size, dtype=np.bool) #terminal对应同索引号的screen # pre-allocate prestates and poststates for minibatch # 选择动作前的状态 s,a,s+1,中的状态s,当前状态 self.prestates = np.empty((self.batch_size, self.history_length) + self.dims, dtype=np.float32) # 选择动作前的状态 s,a,s+1,中的状态s+1,下一状态 self.poststates = np.empty((self.batch_size, self.history_length) + self.dims, dtype=np.float32) # 判断设置是否正确 assert self.history_length>=1 # history_length,状态state由几个图像组成,大小至少为1 def add(self, action, reward, screen, terminal): """ 向experience buffer中加入新的a,r,s,terminal操作 """ assert screen.shape == self.dims #判断传入的screen变量维度是否符合设定 # screen is post-state, after action and reward # screen 是动作后的图像,前一状态执行动作action后获得reward,screen # current指示当前的加入位置 self.actions[self.current] = action self.rewards[self.current] = reward self.screens[self.current, ...] = screen self.terminals[self.current] = terminal # experience buffer没有满时,current等于count,current自加一后赋值给count # buffer满时,count等于buffer容量,固定不变,count=buffer_size, current自加一,进行指针平移 self.count = max(self.count, self.current + 1) # 加入新值后,指针位置自动加一 self.current = (self.current + 1) % self.buffer_size #buffer_size经验池大小 def getState(self, index): return self.screens[(index - (self.history_length - 1)):(index + 1), ...] def sample(self): # memory must include poststate, prestate and history assert self.count > self.history_length # history_length至少为1,由于要考虑前后两个状态所以count至少为2 # sample random indexes indexes = [] while len(indexes) < self.batch_size: # find random index while True: # sample one index (ignore states wraping over index = random.randint(self.history_length, self.count - 1) # if wraps over current pointer, then get new one if index - self.history_length < self.current <= index: continue # if wraps over episode end, then get new one # poststate (last screen) can be terminal state! if self.terminals[(index - self.history_length):index].any(): continue # otherwise use this index break # having index first is fastest in C-order matrices self.prestates[len(indexes), ...] = self.getState(index - 1) self.poststates[len(indexes), ...] = self.getState(index) indexes.append(index) actions = self.actions[indexes] rewards = self.rewards[indexes] terminals = self.terminals[indexes] # return s,a,s,a+1,terminal if self.cnn_format == 'NHWC': return np.transpose(self.prestates, (0, 2, 3, 1)), actions, rewards, np.transpose(self.poststates, (0, 2, 3, 1)), terminals else: #format is 'NCHW', faster than 'NHWC' return self.prestates, actions, rewards, self.poststates, terminals
该代码原理就是 add方法 把每次agent执行的action,从环境中获得的reward,游戏屏幕转移到的新状态state,s+1, 以及新状态是否为终止状态即terminal,这四个元素(action,reward,游戏屏幕的新状态,s+1, 是否终止terminal)加入到缓存池(eperience replay buffer)中。由于experience replay buffer有容量限制,于是每一次把游戏的新屏幕图像存入后还需要检查是否超过buffer容量,如果超出得自动删除最早存入buffer中的游戏屏幕图像。
sample方法则每次从缓冲中分别取出history_length长度的preState,和postState, preState是强化学习算法中执行动作之前的状态,postState则是强化学习算法中执行动作之后获得的新状态。 从preState 状态执行action 跳转到新状态postState获得reward,和postState是否为终止状态的标志。
其中不论是preState还是postState都是由history_length长度的游戏画面组成,也就是由history_length帧游戏画面组成,而游戏画面帧则是存入缓存池中的。比如history_length长度为4,缓存池(experience replay buffer)中5个画面帧s0,s1,s2,s3,s4中(s0,s1,s2,s3)可以看做是preState,而缓存池中s3对应的action也为强化学习中preState的动作,而强化学习中跳转到的新状态则表示为(s1,s2,s3,s4),此时获得的reward已经terminal则为缓存池中画面帧s4对应的reward及terminal。
对于sample抽取出的样本并不一定是可用的,这里我们要剔除掉不可用的,因为画面帧s0,s1,s2,s3,s4,分别对应的terminal为t0,t1,t2,t3,t4, 除t4可以为terminal以外t0,t1,t2,t3不能为terminal,或者说t0,t1,t2,t3的terminal标志必须为faulse,否则需要重新抽样。因为s0,s1,s2,s3对应的terminal为true,那么就不能用其组成preState和postState。preState和postState是强化学习算法中的概念,在游戏中我们没有办法获得agent在尤其中的速度,以及游戏中其他角色的速度等信息,因此在组成强化学习中的state时我们选择将游戏画面中的几个帧组成一个state,这样组成的preState和postState就含有了游戏中agent和其他角色的速度等信息,当然如果是强化学习中的平衡杆问题cartpole,我们本身就是可以获得小车和杆子的速度及位置的,这样我们就不需要把这几帧画面组成一个强化学习中的状态,在平衡杆问题中获得的每一帧非图像数据(位置,速度信息)直接可以作为强化学习中的state,由于DQN的一个创新就是使用了图像数据这种感知数据,因此无法直接获得游戏中各角色的速度等信息,也正是由此创新性的给出了一种用几帧游戏画面作为一个强化学习中的state的表示。但这同时也暗含着一个要求就是这几帧画面是要求连续的,因此不能有除最后一帧画面以外的画面对应的terminal为true,即终止画面(结束画面)。
replay buffer的最直观的设计就是使用一进一出的方法,就是一个队列的实现,即add加入一个新画面帧及其他信息则在队列的后面进入队列,如果队列满了则从队列的最前面弹出最好的画面帧及其他信息。但是由于DQN中设计的buffer容量过大 100*10000, 那么使用python中的list或numpy中array来实现队列,进行增删时都会需要较大的资源消耗,当然这个问题使用C、C++、Java等语言是较好解决的,在不考虑使用其他语言混合编写的情况下对此进行讨论。因此第一种变体使用循环队列的思想来用numpy中的array来实现,也就是使用一个指针性的变量指向下一次需要加入新画面的索引号,如果buffer填满则循环指向最初的位置,也就是从0号位置进行覆盖填充,如此循环。而由于有循环指针的设计变体1需要考虑一个连续的画面帧s0,s1,s2,s3,s4中是否有指针current所指向的帧,这里我们假设s4对应的索引号为index,那么s0对应的索引号为index-history_length, 也就是说一个组成preState和postState的画面帧上下限索引号为index-history_length与index。
如果我们保证index-history_length>=0,那么current对应的索引号如果大于index-history_length并且小于等于index的话说明s0,s1,s2,s3存在新覆盖进来的画面帧,由此不能保证s0,s1,s2,s3,s4为连续画面帧,所以保证index-history_length>=0在判断条件上更方便。同时由于是环形的缓冲池设计,如果我们保证index-history_length>=0,那么所选取的s0,s1,s2,s3,s4都是物理存储上连续的,更便于选取操作。
-----------------------------------------------------------------------
第二种变体:
# encoding:UTF-8 """Code from https://github.com/tambetm/simple_dqn/blob/master/src/replay_memory.py""" import random import numpy as np class ReplayBuffer(object): def __init__(self, config): self.cnn_format = config.cnn_format # buffer中数据的格式,'NCHW'或'NHWC' self.buffer_size = config.replay_buffer_size # 缓存池的最大容量 self.history_length = config.history_length # 一个状态,state的历史数据长度 self.dims = (config.screen_height, config.screen_width) # 一帧图像的高、宽 self.batch_size = config.batch_size # mini_batch_size 大小 self.count = 0 # 当前缓存池中现有存储数据的大小 self.current = 0 # 指针指向的索引号,下一帧新数据存储的位置 """ expericence replay buffer 定义经验池 pre_state->a,r,s,terminal """ self.actions = np.empty(self.buffer_size, dtype=np.uint8) self.rewards = np.empty(self.buffer_size, dtype=np.int8) # 这里我们设定reward为:0,+1,-1,三个种类 self.screens = np.empty((self.buffer_size, config.screen_height, config.screen_width), dtype=np.float32) # 设定屏幕截图汇总,states self.terminals = np.empty(self.buffer_size, dtype=np.bool) #terminal对应同索引号的screen # pre-allocate prestates and poststates for minibatch # 选择动作前的状态 s,a,s+1,中的状态s,当前状态 self.prestates = np.empty((self.batch_size, self.history_length) + self.dims, dtype=np.float32) # 选择动作前的状态 s,a,s+1,中的状态s+1,下一状态 self.poststates = np.empty((self.batch_size, self.history_length) + self.dims, dtype=np.float32) assert self.history_length>=1 # history_length,状态state由几个图像组成,大小至少为1 def add(self, action, reward, screen, terminal): """ 向experience buffer中加入新的a,r,s,terminal操作 """ assert screen.shape == self.dims #判断传入的screen变量维度是否符合设定 # screen is post-state, after action and reward # screen 是动作后的图像,前一状态执行动作action后获得reward,screen # current指示当前的加入位置 self.actions[self.current] = action self.rewards[self.current] = reward self.screens[self.current, ...] = screen self.terminals[self.current] = terminal # experience buffer没有满时,current等于count,current自加一后赋值给count # buffer满时,count等于buffer容量,固定不变,count=buffer_size, current自加一,进行指针平移 self.count = max(self.count, self.current + 1) # 加入新值后,指针位置自动加一 self.current = (self.current + 1) % self.buffer_size #buffer_size经验池大小 def getState_order(self, index): #索引号:index - (self.history_length - 1)到index数据,不存在环形,顺序排列 return self.screens[(index - (self.history_length - 1)):(index + 1), ...] def getState_ring(self, index): if index - (self.history_length - 1) >= 0: # use faster slicing return self.screens[(index - (self.history_length - 1)):(index + 1), ...] else: # otherwise normalize indexes and use slower list based access _indexes = [(index - i) % self.count for i in reversed(range(self.history_length))] return self.screens[_indexes, ...] def sample(self): # memory must include poststate, prestate and history assert self.count > self.history_length # history_length至少为1,由于要考虑前后两个状态所以count至少为2 # sample random indexes indexes = [] while len(indexes) < self.batch_size: # find random index if self.count == self.buffer_size: # buffer 已满 while True: # sample one index (ignore states wraping over index = random.randint(0, self.buffer_size - 1) low_index_exclude = index - self.history_length upper_index_include = index if low_index_exclude >= 0: # if wraps over current pointer, then get new one if low_index_exclude < self.current <= upper_index_include: continue # if wraps over episode end, then get new one # poststate (last screen) can be terminal state! if self.terminals[(index - self.history_length):index].any(): continue # having index first is fastest in C-order matrices self.prestates[len(indexes), ...] = self.getState_order(index - 1) self.poststates[len(indexes), ...] = self.getState_order(index) indexes.append(index) # otherwise use this index break else: #low_index_exclude < 0 if self.current > low_index_exclude + self.buffer_size or self.current <= upper_index_include: continue # poststate (last screen) can be terminal state! if self.terminals[low_index_exclude:].any() or self.terminals[:upper_index_include].any(): continue # having index first is fastest in C-order matrices self.prestates[len(indexes), ...] = self.getState_ring(index - 1) self.poststates[len(indexes), ...] = self.getState_ring(index) indexes.append(index) # otherwise use this index break else: #self.count (not equal) self.buffer_size, buffer 缓存池,未满, current=count while True: # sample one index (ignore states wraping over index = random.randint(self.history_length, self.count - 1) # if wraps over episode end, then get new one # poststate (last screen) can be terminal state! if self.terminals[(index - self.history_length):index].any(): continue # having index first is fastest in C-order matrices self.prestates[len(indexes), ...] = self.getState_order(index - 1) self.poststates[len(indexes), ...] = self.getState_order(index) indexes.append(index) # otherwise use this index break actions = self.actions[indexes] rewards = self.rewards[indexes] terminals = self.terminals[indexes] # return s,a,s,a+1,terminal if self.cnn_format == 'NHWC': return np.transpose(self.prestates, (0, 2, 3, 1)), actions, rewards, np.transpose(self.poststates, (0, 2, 3, 1)), terminals else: #format is 'NCHW', faster than 'NHWC' return self.prestates, actions, rewards, self.poststates, terminals
第二种变体是在第一种的基础上改进的,采用了相同的思路和处理方法。第一种变体要求保证index-history_length>=0这个条件,但是在第二种变体中对此不作要求,而是分为三种情况进行处理,增加了条件判断以及不同条件下的处理办法。三种情况分别为:第一种情况,buffer填满时从0到buffer_size-1中选取索引号index,index决定的序列下限index-history_length>=0时,此时可以视作第一种变体所考虑的情况,采样第一种变体中相同的处理方法;第二种情况,buffer填满时从0到buffer_size-1中选取索引号index,index决定的序列下限index-history_length<时,此时存在有的屏幕画面(前面的画面帧)索引号大于后续画面帧的索引号,因此需要分别考虑索引号小于0的画面帧及索引号大于0的画面帧,既要分别满足current条件又要分别保证terminal的条件;第三种情况则是buffer没有满时,此时和第三种变体的考虑情况相同,此时就没有current变量需要考虑,因为current保证在队列的最后面,不存在覆盖的问题,此时只需要考虑满足terminal条件即可,并且第三种情况时index_history_length>=0条件是需要满足的,判断条件减少了。
----------------------------------------------------------------
第三种变体:
# encoding:UTF-8 """Code from https://github.com/tambetm/simple_dqn/blob/master/src/replay_memory.py""" import random import numpy as np class ReplayBuffer(object): def __init__(self, config): self.cnn_format = config.cnn_format # buffer中数据的格式,'NCHW'或'NHWC' self.buffer_size = config.replay_buffer_size # 缓存池的最大容量 self.history_length = config.history_length # 一个状态,state的历史数据长度 self.dims = (config.screen_height, config.screen_width) # 一帧图像的高、宽 self.batch_size = config.batch_size # mini_batch_size 大小 self.count = 0 # 当前缓存池中现有存储数据的大小 """ # expericence replay buffer 定义经验池 pre_state->a,r,s,terminal # 这里我们设定reward为:0,+1,-1,三个种类 # 设定屏幕截图汇总,states # terminal对应同索引号的screen """ self.actions = [] self.rewards = [] self.screens = [] self.terminals =[] # pre-allocate prestates and poststates for minibatch # 选择动作前的状态 s,a,s+1,中的状态s,当前状态 self.prestates = np.empty((self.batch_size, self.history_length) + self.dims, dtype=np.float32) # 选择动作前的状态 s,a,s+1,中的状态s+1,下一状态 self.poststates = np.empty((self.batch_size, self.history_length) + self.dims, dtype=np.float32) # 判断设置是否正确 assert self.history_length>=1 # history_length,状态state由几个图像组成,大小至少为1 def add(self, action, reward, screen, terminal): """ 向experience buffer中加入新的a,r,s,terminal操作 """ assert screen.shape == self.dims #判断传入的screen变量维度是否符合设定 # screen is post-state, after action and reward # screen 是动作后的图像,前一状态执行动作action后获得reward,screen # current指示当前的加入位置 self.actions.append(action) self.rewards.append(reward) self.screens.append(screen) self.terminals.append(terminal) if self.count<self.buffer_size: self.count+=1 else: self.actions.pop(0) self.rewards.pop(0) self.screens.pop(0) self.terminals.pop(0) def getState(self, index): return self.screens[(index - (self.history_length - 1)):(index + 1)] def sample(self): # memory must include poststate, prestate and history assert self.count > self.history_length # history_length至少为1,由于要考虑前后两个状态所以count至少为2 # sample random indexes indexes = [] while len(indexes) < self.batch_size: # find random index while True: # sample one index (ignore states wraping over index = random.randint(self.history_length, self.count - 1) # if wraps over episode end, then get new one # poststate (last screen) can be terminal state! if sum(self.terminals[(index - self.history_length):index])!=0: continue # otherwise use this index break # having index first is fastest in C-order matrices self.prestates[len(indexes), ...] = self.getState(index - 1) self.poststates[len(indexes), ...] = self.getState(index) indexes.append(index) actions = [] rewards = [] terminals = [] for index in indexes: actions.append(self.actions[index]) rewards.append(self.rewards[index]) terminals.append(self.terminals[index]) actions = np.array(actions) rewards = np.array(rewards) terminals = np.array(terminals) # return s,a,s,a+1,terminal if self.cnn_format == 'NHWC': return np.transpose(self.prestates, (0, 2, 3, 1)), actions, rewards, np.transpose(self.poststates, (0, 2, 3, 1)), terminals else: #format is 'NCHW', faster than 'NHWC' return self.prestates, actions, rewards, self.poststates, terminals
变体三与变体一的设计思路基本一致,只不过区别在于:1.变体3没有使用numpy中的array实现循环队列,而是使用python的list实现了一个普通的队列,入队则append,出队列则pop(0)。2.由于没有使用循环队列因此没有了current的变量,在使用sample方法判断时保证index-history_length>=0的前提下不用考虑current造成的不连续性,因为新状态都是在队列的最末尾。在使用add时需要考虑是否达到容量,如果达到则出队,使用pop(0)。
-----------------------------------------------------
性能分析:
测试文件:

# encoding:UTF-8 import numpy as np import time from replay_buffer import ReplayBuffer as ReplayBuffer_1 from replay_buffer_2 import ReplayBuffer as ReplayBuffer_2 from replay_buffer_3 import ReplayBuffer as ReplayBuffer_3 class Config(object): def __init__(self): self.cnn_format = "NCHW" self.replay_buffer_size = 5*10000#100*10000 self.history_length= 4 self.screen_height = 100 self.screen_width = 100 self.batch_size = 32 config = Config() rf_1 = ReplayBuffer_1(config) rf_2 = ReplayBuffer_2(config) rf_3 = ReplayBuffer_3(config) state = np.random.random([config.screen_height, config.screen_width]) action = np.uint8(0) reward = np.int8(1) for i in range(5000*10000): #总步数 terminal =np.random.choice([True, False], 1, [0.1, 0.9])[0] rf_1.add(action, reward, state, terminal) if rf_1.count >= 5*10000: # 开始抽样的步数 rf_1.sample() if i%10000 == 0: print(i) if i == 5*10000: a = time.time() if i ==55*10000: b = time.time() break print(b-a)
第一种变体资源消耗:

第二种变体资源消耗:

第三种变体资源消耗:

可以看到三种算法对CPU的占有都可以达到100%,同时第一、二种变体内存占用相同。第三种其实内存占用应该要大于第一、二种的,之所以这里显示第三种变体算法消耗内存少是因为测试文件中传入变体算法的输入值为固定不变的,而第三种变体中缓冲池是使用列表来构建的,由于Python语言中变量引用原理导致大量变量所指向的内存空间为同一块。
运行时间:
第一种变体:
820.264048815
801.370502949
802.797419071
第二种变体:
781.069205999
795.399427891
789.664218903
第三种变体:
1906.51530409
1825.43317413
1893.87990212
可以看到设计比较复杂的第一、二种变体运行时间相当,第三种变体运行时间2倍多于前两种。
由于我们只测试了50万次的计算,原DQN中设计的是5000万次计算,由此我们按最快的800秒/50万次来计算,总共进行5000万次需要时间:
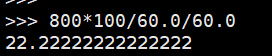
而本文相关的DQN算法(使用第一种变体的experience replay buffer)共需要运行99小时左右,也就是说整个DQN算法运行过程中需要处理buffer的时间就占总算法的20%以上,由此可见在DQN算法中在CPU上进行处理的时间开销还是很大的,如果考虑和真是游戏环境进行交互等可能CPU花销更大些,根据不完整的估计在整个DQN算法中CPU上需要的开销可能会占整个算法的50%,也就是说cpu上的开销其实可能和GPU上的开销相当,如果我们有效提升CPU上运算性能可以对整个DQN算法进行较大运算性能的提升。
-------------------------------------------------------------
时间过得很快,最早是在14年左右接触到强化学习算法的,那时还是在读研究生的时候,但是就是感觉强化学习算法很抽象,搞不清楚它是要做什么的,它的目的是啥,关键点在,具体途径是啥,等等吧,都是全然不知,所以接触不就后也就放弃掉了。2017年下半年开始读phd,由于种种不可言说的原因在入学快一年的时候才获得研究课题,或是说才有研究方向,也不知怎的居然是强化学习方向。由于也是经历重重考验才得到的研究方向,所以也没资格,更是不敢去挑肥拣瘦的,所以也就只好硬着头皮接了下来。当时手上仅有的设备就是一台i5 CPU,NVIDIA1060显卡,在加上前期的种种不可言说的经历,而且在半年前也是由于朋友介绍接触过这个方向(当时阿里正在搞强行学习的推荐算法),总之就是既感觉有几分欣慰(毕竟有研究方向了),也感觉有些失落,因为这个研究方向在我所知道的人里面就没有搞这个研究方向的,硬件上也是不太行,软件上啥历史遗留资源也没有,就连身边可以问的人都没有,于是乎一边做着一边考虑出路了。这中间去过公司面试,去过国企和科研单位面试过,总的说就是感觉不合适,一晃就2018年下半年了,此时也是研究上啥进展都没有(可能确实有些三心二意了),在外边找出路上也是难以如意顺心,就这样带着无奈回家过年了。再一次返校就是2019年了,可能正是前期种种的不如意,遭遇的种种难堪,这是终于爆发了,2019年上半年居然病倒了,而且是毫无预兆,各种压力,各种难受,还要不停的跑医院,就这样经历了三四个月终于算是好的差不多了,此时2019年的上半年也是快过去了,原本打算外边出路不好找的话就安心在学校学习了,可谁想到又赶上这事情,真可谓是屋漏偏逢连夜雨,也是没有正经做啥的。本就因为各种不可言说的原因导致自己晚了一年入实验室,这又出了这么一个插曲,算下来自己相当于晚了两年才开始正式工作。2019年下半年也是想开了,也算是读phd的副产品,那就是心态得到了提升,也更加耐折磨了,下半年开学后也是该准备开题了,由于各种不可言说的原因原本应该2018年开的题被延期到2019年年末了。这时候虽然开始正式准备工作了,可是心里即使再想得开也难免难受,对于自己遭受的那些不可言说的经历还是不能完全放下,强打精神去往下走却还是感觉心不由衷,不管怎么说最后还是水过了开题,毕竟开题这个东西还是比较水的。开完题就是快到2020的元旦了,前脚刚到家就爆发了疫情,没法子就在农村的家呆到了今年9月返校,此时已是毕业季,但是对于我来说更像是入学季,可以说我比同级的人整个晚了好几年,而且本身就开始的晚,再加上这么长时间的假期,回来后感觉很多东西都是要重新开始的,这时候也把19年的一些资料找了出来,这便有了这篇博客要说的内容。
---------------------------------------------