原文地址:
https://www.cnblogs.com/pinard/p/9669263.html
-----------------------------------------------------------------------------------------------------
在强化学习(六)时序差分在线控制算法SARSA中我们讨论了时序差分的在线控制算法SARSA,而另一类时序差分的离线控制算法还没有讨论,因此本文我们关注于时序差分离线控制算法,主要是经典的Q-Learning算法。
Q-Learning这一篇对应Sutton书的第六章部分和UCL强化学习课程的第五讲部分。
1. Q-Learning算法的引入

这一类强化学习的问题求解不需要环境的状态转化模型,是不基于模型的强化学习问题求解方法。对于它的控制问题求解,和蒙特卡罗法类似,都是价值迭代,即通过价值函数的更新,来更新策略,通过策略来产生新的状态和即时奖励,进而更新价值函数。一直进行下去,直到价值函数和策略都收敛。
再回顾下时序差分法的控制问题,可以分为两类,一类是在线控制,即一直使用一个策略来更新价值函数和选择新的动作,比如我们上一篇讲到的SARSA, 而另一类是离线控制,会使用两个控制策略,一个策略用于选择新的动作,另一个策略用于更新价值函数。这一类的经典算法就是Q-Learning。
对于Q-Learning,我们会使用ε-贪婪法来选择新的动作,这部分和SARSA完全相同。但是对于价值函数的更新,Q-Learning使用的是贪婪法,而不是SARSA的ε-贪婪法。这一点就是SARSA和Q-Learning本质的区别。
2. Q-Learning算法概述
Q-Learning算法的拓补图入下图所示:
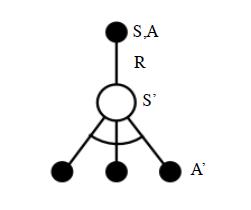


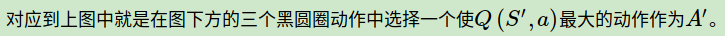

下面我们对Q-Learning算法做一个总结。
3. Q-Learning算法流程
下面我们总结下Q-Learning算法的流程。

4. Q-Learning算法实例:Windy GridWorld
我们还是使用和SARSA一样的例子来研究Q-Learning。如果对windy gridworld的问题还不熟悉,可以复习强化学习(六)时序差分在线控制算法SARSA第4节的第二段。
完整的代码参见我的github: https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/q_learning_windy_world.py
绝大部分代码和SARSA是类似的。这里我们可以重点比较和SARSA不同的部分。区别都在episode这个函数里面。

# play for an episode def episode(q_value): # track the total time steps in this episode time = 0 # initialize state state = START while state != GOAL: # choose an action based on epsilon-greedy algorithm if np.random.binomial(1, EPSILON) == 1: action = np.random.choice(ACTIONS) else: values_ = q_value[state[0], state[1], :] action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])

next_state = step(state, action)
def step(state, action): i, j = state if action == ACTION_UP: return [max(i - 1 - WIND[j], 0), j] elif action == ACTION_DOWN: return [max(min(i + 1 - WIND[j], WORLD_HEIGHT - 1), 0), j] elif action == ACTION_LEFT: return [max(i - WIND[j], 0), max(j - 1, 0)] elif action == ACTION_RIGHT: return [max(i - WIND[j], 0), min(j + 1, WORLD_WIDTH - 1)] else: assert False

values_ = q_value[next_state[0], next_state[1], :] next_action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)]) # Sarsa update q_value[state[0], state[1], action] += ALPHA * (REWARD + q_value[next_state[0], next_state[1], next_action] - q_value[state[0], state[1], action]) state = next_state
跑完完整的代码,大家可以很容易得到这个问题的最优解,进而得到在每个格子里的最优贪婪策略。
5. SARSA vs Q-Learning
现在SARSA和Q-Learning算法我们都讲完了,那么作为时序差分控制算法的两种经典方法吗,他们都有说明特点,各自适用于什么样的场景呢?

另外一个就是Q-Learning直接学习最优策略,但是最优策略会依赖于训练中产生的一系列数据,所以受样本数据的影响较大,因此受到训练数据方差的影响很大,甚至会影响Q函数的收敛。Q-Learning的深度强化学习版Deep Q-Learning也有这个问题。
在学习过程中,SARSA在收敛的过程中鼓励探索,这样学习过程会比较平滑,不至于过于激进,导致出现像Q-Learning可能遇到一些特殊的最优“陷阱”。比如经典的强化学习问题"Cliff Walk"
在实际应用中,如果我们是在模拟环境中训练强化学习模型,推荐使用Q-Learning, 如果是在线生产环境中训练模型,则推荐使用SARSA。
6. Q-Learning结语
对于Q-Learning和SARSA这样的时序差分算法,对于小型的强化学习问题是非常灵活有效的,但是在大数据时代,异常复杂的状态和可选动作,使Q-Learning和SARSA要维护的Q表异常的大,甚至远远超出内存,这限制了时序差分算法的应用场景。在深度学习兴起后,基于深度学习的强化学习开始占主导地位,因此从下一篇开始我们开始讨论深度强化学习的建模思路。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
-----------------------------------------------------------------------------------------