
一提到比特币、区块链,能让我们最先想到的就是去中心化,分布式数据库/账本,但是什么是去中心化,或者什么是区块链,却未必都能说得清。很多人对于区块链的认识就止步于此。网上查一查什么是区块链,各种专业词汇扑面而来,什么点对点网络,什么工作量证明机制(PoW),什么数字签名、共识算法,把人看得云里雾里,也未必真能搞得懂。实际上,区块链就是这样的一种技术,它并非是从零开始,而是基于已有的这些技术,经过巧妙的结合生成的。如果要搞懂区块链,就要搞明白这些东西是怎么结合在一起的。所以这篇文章主要在宏观的基础上,在技术层面做更进一步的深入。
如何理解区块链
首先,引入区块链的理念:将一个基于节点的去中心化共识协议与工作量证明(PoW)机制结合在一起。节点通过PoW机制获得参与到系统的权利,每隔一段时间将交易打包到区块中,从而创建出不断增长的区块链。
这里主要有两个概念:去中心化和工作量证明机制。
如何去中心化:区块链系统中的每一个区块,负责记录交易信息,每个用户的收支情况都被永久的存储在区块中供他人查询。每个节点都会保存一份完整的交易数据,所有这些节点组成了区块链的分布式数据库系统,任何一个节点的数据出现问题,都不会影响整个系统的运转。
工作量证明机制:工作量证明(Proof Of Work,简称PoW),简单理解就是一份证明,用来确认你在系统中做过一定量的工作。相较于低效的监测工作的整个过程,通过对工作结果进行认证来证明完成了相应的工作量,则是一种非常高效的方式。例如我们通过完成工作中的各项任务来证明我们为公司创造了价值,从而得到公司的认可。而这种"工作证明"一般都会花费一定的时间才能得到。
工作量证明机制(PoW)
工作量证明机制,是一种应对拒绝服务攻击(DoS)和其他服务滥用的经济对策。它要求发起者进行一定量的运算作为代价,也就意味着需要消耗计算机一定的时间。例如现在网站登录时都需要输入的验证码(滑块或者拼图),都采用的是这种CAPTCHA模式。
类似于CAPTCHA,哈希现金(HashCash)的原理是在邮件的消息头中增加一个包含收件人地址、发送时间和salt随机数的hashcash stamp的散列值,但是满足前20位都是0的散列值才是合法的。这就需要发送者在正式发送前需要通过调整salt的值进行多次计算,在满足该条件后才能成功发送。但是我们不希望发送者在算出这个stamp后继续复用,所以HashCash规定了过期的stamp是非法的(即发送时间 > stamp时间)。
区块链也是采用了类似hashcash的工作量证明方法,对区块头中的数据做双重SHA256运算( 即SHA256(SHA256(HEADER)) ),与当前网络的目标值做对比,如果小于目标值,则完成工作量证明。
这里对PoW做了较多的解释,是为了便于理解PoW是如何应用在区块链上的。挖矿也是通过PoW进行的。在比特币系统中,节点完成工作量证明后,就代表获得这个区块的交易记账权。系统会通过PoW机制让矿工们竞争记账权,谁在单位时间内执行的运算更多(拥有更高的算力),谁就有更高的概率获得区块的记账权。获得记账权的矿工将把该区块广播到网络中,全网其他节点在验证区块满足特定的条件后,其区块会被链接在主链上,从而在全网范围内形成对当前网络状态的一次共识,该矿工也会得到系统奖励的一定数量的代币。所有的区块通过这种形式链接在一起,形成了区块链的主链,从创世区块到当前生成的最新区块,所有历史交易数据都是公开透明的。
上面提到了区块是用于记录交易信息的,区块头中的数据参与了PoW的过程。那么接下来有必要进一步分析区块的内容了。
区块的组成

每个区块由区块头和区块体两部分组成。区块头中主要包含前一个区块的Hash地址(Prevhash)、时间戳(Timestamp)、随机数(Nonce)、当前区块的目标Hash值(CurrentTarget)。Merkle树的根值(Merkle Root)等信息;区块体中则包含了具体的交易数量(TX NUM)和自上一个区块生成以来发生的所有交易的列表。这个交易列表就是记账本,每一笔交易都会被永久地记入区块中,任何人都可以查询。而且交易都会伴随数字签名,确保交易不可篡改及真实有效性,所有交易都将通过Merkle树的Hash运算产生一个唯一的Merkle根值记录到区块头中(Merkle树是一种数据结构,后面将做介绍)。
状态转移与UTXO交易模式
从技术的角度出发,比特币记账本可以看做是一个状态转移的系统。持有人对现存的所有比特币的持有情况,可以理解为系统当前的一种状态。例如:小明有100个比特币,表示在当前的状态下,小明持有100个比特币。当小明想进行交易时,比如给小王转20个比特币,就需要以当前的状态(拥有100个比特币)和发起的交易(给小王转20个比特币),通过状态转移,生成新的状态(小明有80个比特币,小王有20个比特币)。这个状态转移可以看做是一个函数:
APPLY(STATE, TRANSACTION) => NEW_STATE
表示小明给小王转账的交易:
APPLY({XiaoMing: 100, XiaoWang: 0}, "send 20 from XiaoMing to XiaoWang") => {XiaoMing: 80, XiaoWang: 20 }
可以发现,交易的过程就是一个从输入到输出的过程,一个资金流转的过程,并且创世区块和后来挖矿产生的奖励区块不适用于这个公式(创世区块是整个链上的第一个区块;挖矿的奖励区块是凭空产生的,是发行代币的方式)。除此之外,其他的交易都必须要依据现有的输入来产生新的输出。而现有的输入是从何而来的,必然是从这个持有人在上一笔交易中的输出得到的。稍微有点绕,按照上面的例子,假如小王要给小李再转5个比特币,这笔交易的输入(5个币)必须是上一笔交易(小明给小王转账)中未被使用的输出(20个币)。这个未被使用的交易输出也叫做UTXO(Unspent TX Output),是比特币交易的基本单位。也可以简单理解为空闲的、未被占用的金额,就像已经花出去的钱(你上一笔交易的UTXO)是不可能再花一遍的(已成为别人的UTXO)。一笔交易可以包括一个或多个输入和一个或多个输出,每个输入包含一个对现有UTXO的引用和与持有者私钥创建的密码学签名;每个输出包含一个新的加入到状态中的UTXO。

对于交易中的每个输入和状态,有如下的定义:
1.如果引用的UTXO不在当前的状态中,则会返回错误;如果签名与引用的UTXO的持有者签名不一致,也会返回错误。
2.如果所有输入的UTXO总额与所有输出的UTXO总额不等,会返回错误。
3.返回的新状态NEW_STATE中,移除了所有输入的UTXO,增加了所有输出的UTXO。
Merkle树
Merkle树是数据结构中的一种树结构,可以是二叉树,也可以是多叉树,具有树的所有特点。由于Merkle树中会进行Hash运算,所以也被称为Hash树。在了解Merkle树之前,先来看看Hash算法及HashList。
Hash算法是一种可以将任意长度的数据转换成固定长度字符串的算法。是一种安全散列算法。最显著的特点是几乎不可逆、无冲突。Hash算法最常见的应用就是对数据完整性的校验。例如我们在下载一些文件时,资源提供方会给出一个MD5或者SHA的值,这个值实际上就是资源在经过Hash运算后的值,用户下载数据后,可以对数据进行Hash,然后跟这个值比对,如果相同,就说明数据在传输过程中无损坏或篡改。

缺点:当下载较大的文件时,如果出现Hash值不匹配的情况,那么就要重新下载整个文件。
这种通过对整个文件进行Hash运算来判断数据是否损坏的方法,效率很低下。如果将文件分割成一个个小的数据块,分别对其做Hash,就得到了HashList。在点对点网络中传输数据时,会从多个节点同时下载数据。假设某些节点网络不稳定或者数据不可信,那么为了验证数据的准确性,就会采用HashList,如果某些数据块损坏了,只需要重新下载这些小的数据块即可,无需重新下载整个文件。
通常在下载数据前,会先从可信数据源那里获取一个Root Hash值。Root Hash是将HashList中每个数据块的Hash值拼接到一起,再做一次Hash运算所得到的值。这个值用来校验HashList是否正确。得到Root Hash后,会再下载该数据的HashList。判断HashList正确后,才开始文件数据的下载。最后将下载的数据块做Hash后与HashList做比对,如果出现不一致,则说明数据被损坏,需要重新下载该数据块。

然后回过头来再看Merkle树,它的底层与HashList一样,都是将数据分成小数据块,然后分别计算其Hash值。但是再往上一层就不同了,它不是把所有的Hash值合并到一起做Hash,而是将两个相邻的Hash值拼接在一起进行Hash运算,产生一个新的Hash。例如Block1的Hash值201w与Block2的Hash值0mzc合并Hash后产生新的3ali Hash值。而如果两两匹配后出现孤立的Hash值,则直接将其做Hash,例如Block5。最终产生一个Root Hash值,通常称为Merkle Root。
同样,在下载前,会先从可信数据源中获取正确的Merkle Root,然后再从其他节点下载Merkle树,通过Merkle Root来辨别Merkle树的真伪。如果发现不匹配,则从其他节点继续下载该Merkle树,直到获得一个与可信Merkle Root相匹配的Merkle树。
由于Merkle树是逐级分支的,所以它可以从任意一个分支开始下载并验证。考虑Root->d063->09yk->a8b5->Block3这个分支,如果对这个分支的Hash值验证通过后,就可以下载Block3的数据了。而在HashList中需要先得到整个Hash值列表后才能使用Root Hash验证。

在区块链系统中,最下层的叶节点中存放的是交易数据,每个中间层的节点都是它的两个子节点的Hash,根节点也是它的两个子节点的Hash,代表Merkle树的顶部。如果有攻击者恶意篡改交易数据,或者篡改Merkle树的某一部分,必然导致上层节点的Hash值变动,最终导致验证不通过。
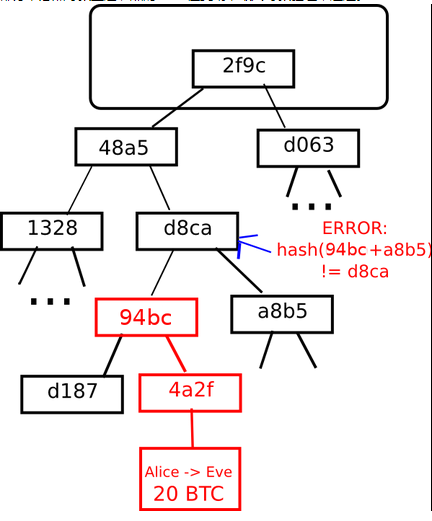
了解了Merkle树的结构后,如果我们要查找某一笔交易,那么顺序是怎样的呢?首先,可以根据区块头中的时间戳确认交易存在的具体区块。而Merkle Root也是放在区块头中的,如果我们从Merkle Root开始向下查找,假设底层有n笔交易数据,那么找到所需的步骤为log2(n),其实就是算法中的二分查找。简化支付验证(Simplified Payment Verification)就是利用这种方案,实现了轻量级的钱包客户端,只需下载区块头及相关交易的分支,即可对交易进行确认。但是它也存在一些缺点:
1.容易遭到全节点的拒绝服务,所以要保证较多的与全节点的连接,而且要保证这些节点是可信的;
2.spv客户端向全节点请求的交易必须与它的密钥一致,这样全节点会看到该客户端的相应用户的公钥,造成隐私泄露。
P2P网络

P2P网络即对等网络,是一种去中心化的分布式应用架构。这种网络结构与目前传统的CS(Client/Server)、BS(Browse Server)结构的本质区别是,网络中不存在中心节点/服务器。在P2P架构中,每个节点的地位都是对等的,都具有相同的功能,无主从之分。节点通过将硬件资源以服务的形式共享到网络中,这些共享的资源可以被其他节点直接访问。一个节点既可充当服务器的角色,又是服务请求方,故节点越多,网络中可提供的资源就越多。而CS、BS这些模式都是以中心应用服务器为核心的,由用户向中心服务器发起请求,中心服务器处理请求后再将结果返回给用户。用户之间的通信也需要通过中心服务器转发来完成。所以P2P网络中的核心思想也是去中心化。除了这个特点,P2P网络还具有扩展性强、健壮性、高性价比、负载均衡、隐私保护等特点。我们日常使用的BT下载就是采用P2P让客户端之间进行数据传输。BT下载是通过BitTorrent协议(一种中心索引式的P2P文件分分析通信协议),让你在下载其他用户资源的同时,也为其他用户提供上传。所以下载的人越多,可连接到的节点就越多,下载速度就越快。
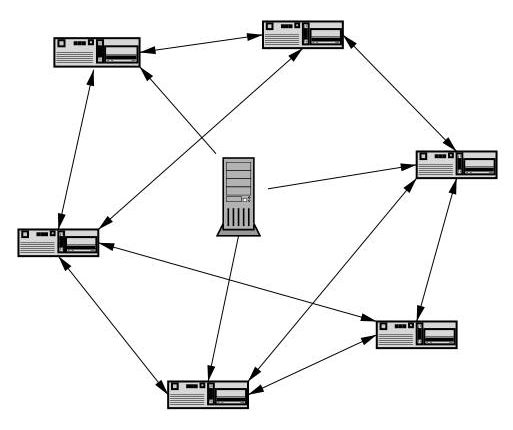
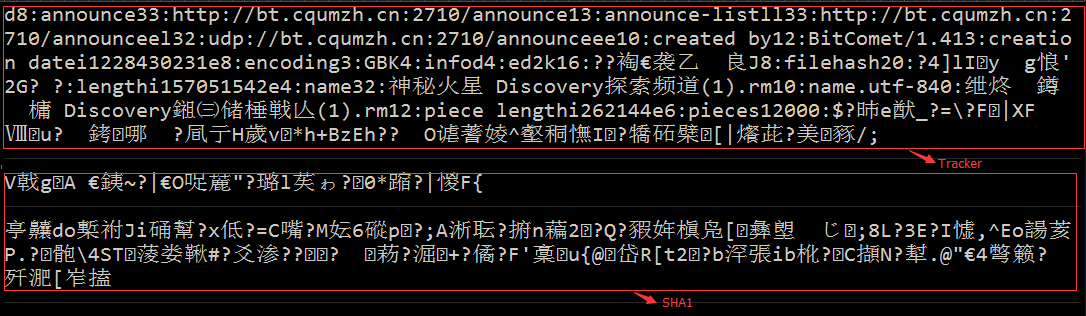
在BT架构中,我们发现还是存在一个"中心服务器",该服务器的作用并非提供下载服务,而是对发布的torrent文件进行统一管理。torrent文件本质上是一个索引文件,包含了Tracker信息(发布资源的服务器的位置)和文件信息(文件名、大小、Hash值等),这些信息根据BitTorrent协议内的B编码规则进行编码。torrent文件中的Hash信息是对每一块要下载的文件内容的加密结果。使用文本工具打开.torrent文件,就可以看个大概(乱码是SHA1校验码):
结语
通过以上的内容可以发现,组成区块链的这些技术实际上早已有着广泛的应用,只是我们之前并未那么密切的关注过,而区块链只是将这些技术巧妙的结合到了一起。理解了这些技术的原理后,我们就可以揭开区块链神秘的面纱,去进一步窥探其中的奥秘。
参考资料:
《区块链技术指南》 邹均/张海宁著
《Ethereum white paper》