Pandas中提供了许多用来处理时间格式文本的方法,包括按不同方法生成一个时间序列,修改时间的格式,重采样等等。
按不同的方法生成时间序列
In [7]: import pandas as pd
# 按起始和终止日期以及步长生成时间序列
In [8]: pd.date_range(start="20171212",end="20180101",freq="D")
Out[8]:
DatetimeIndex(['2017-12-12', '2017-12-13', '2017-12-14', '2017-12-15',
'2017-12-16', '2017-12-17', '2017-12-18', '2017-12-19',
'2017-12-20', '2017-12-21', '2017-12-22', '2017-12-23',
'2017-12-24', '2017-12-25', '2017-12-26', '2017-12-27',
'2017-12-28', '2017-12-29', '2017-12-30', '2017-12-31',
'2018-01-01'],
dtype='datetime64[ns]', freq='D')
In [9]: pd.date_range(start="20171212",end="20180101",freq="10D")
Out[9]: DatetimeIndex(['2017-12-12', '2017-12-22', '2018-01-01'], dtype='datetime64[ns]', freq='10D')
# 按起始日期,数量和步长生成时间序列
In [10]: pd.date_range(start="20171212",periods=10,freq="10D")
Out[10]:
DatetimeIndex(['2017-12-12', '2017-12-22', '2018-01-01', '2018-01-11',
'2018-01-21', '2018-01-31', '2018-02-10', '2018-02-20',
'2018-03-02', '2018-03-12'],
dtype='datetime64[ns]', freq='10D')
In [11]: pd.date_range(start="20171212",periods=10,freq="M")
Out[11]:
DatetimeIndex(['2017-12-31', '2018-01-31', '2018-02-28', '2018-03-31',
'2018-04-30', '2018-05-31', '2018-06-30', '2018-07-31',
'2018-08-31', '2018-09-30'],
dtype='datetime64[ns]', freq='M')
# 如果取不到最后一天,这个时间序列就会停止在前一个生成的日期处
In [12]: pd.date_range(start="20171212",end="20180105",freq="10D")
Out[12]: DatetimeIndex(['2017-12-12', '2017-12-22', '2018-01-01'], dtype='datetime64[ns]', freq='10D')
案例
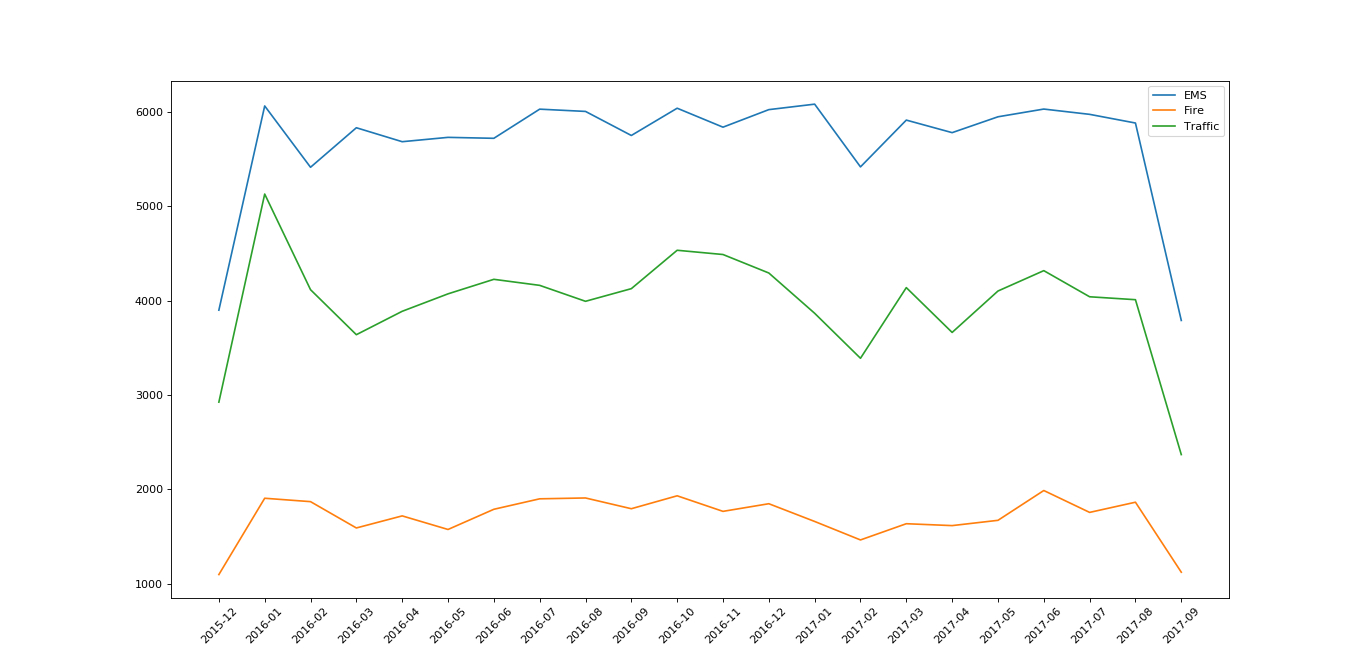
假如我们现在有美国2015年12月到2017年9月的911求救电话信息。(数据来源:Emergency - 911 Calls)假如我们需要统计并绘制每个月的各类求救电话的变化情况,应该怎么做呢?
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
filepath = "./911.csv"
df = pd.read_csv(filepath)
font = font_manager.FontProperties(fname="C:WindowsFontsmsyh.ttc")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp", inplace=True)
temp_list = df["title"].str.split(":")
cate_list = [i[0] for i in temp_list]
df["cate"] = cate_list
plt.figure(figsize=(20, 8), dpi=80)
# 分组
for group_name, group_data in df.groupby(by="cate"):
# 对不同分类进行绘图
count_by_month = group_data.resample("M").count()["title"]
_x = count_by_month.index
_y = count_by_month.values
plt.plot(range(len(_x)), _y, label=group_name)
_x = _x.strftime("%Y-%m")
plt.xticks(range(len(_x)), _x, rotation=45)
plt.legend(loc="best")
plt.show()
结果如图: