EfficientNet是谷歌大脑在2019年提出的,论文地址是:https://arxiv.org/pdf/1905.11946.pdf
这篇文章主要想解决的一个问题是,如何平衡网络的深度、宽度和分辨率来提高模型的准确率。
通常而言,提高网络的深度、宽度和分辨率来扩大模型,从而提高模型的泛化能力。但如果单一提高某个参数的话,模型准确率很快会达到饱和,如下图所示。

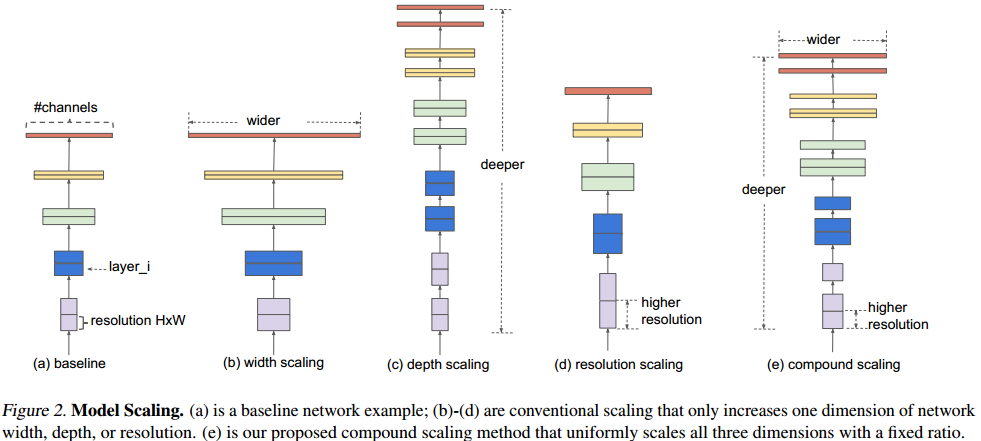
因此,需要同时对深度、宽度和分辨率来进行调整。作者提出了“复合相关系数(compound coefficient)”来动态提高这3个参数,如下图所示,(a)是baseline model,(b)-(d)是单一提高某个参数,(e)是3个参数动态调整。
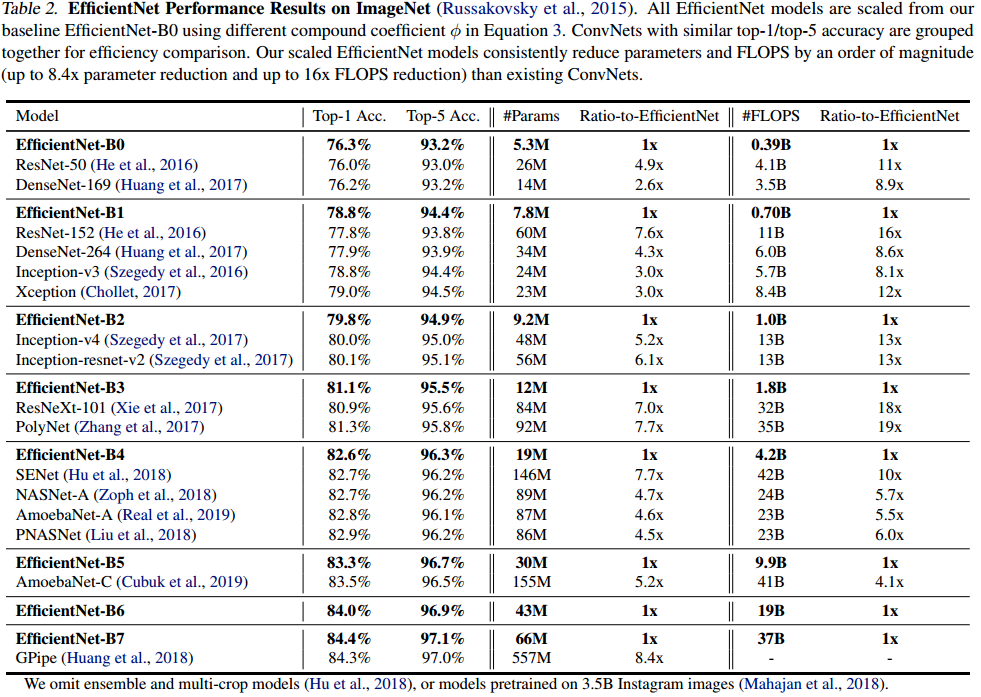
最终得到的结果,如下图所示。就EfficientNet-b0而言,其准确率比ResNet50还高,参数量更少和FLOPS更低(不知道FLOPS能否代表速度的意思?)。从总体而言,在同等参数量下,EfficientNet系列都完胜其他网络。

下面,我们具体来了解一下EfficientNet的细节。
前文提及到,动态调整深度、宽度和分辨率能提高网络的准确率,那么谷歌是如何做的?通过实验,作者得到了两个结论:
- 扩大网络中深度、宽度或者分辨率的任一维度能提高模型的准确率,但随着模型的扩大,这种准确率的增益效果会逐步消失;
- 为了更好的准确率和效率,很有必要去平衡提升网络中深度、宽度和分辨率的所有维度。
因此,谷歌对此进行了数据建模,如下图所示。使用了AutoML的方式,利用网格搜索的形式来搜索出这个相关系数。对,没错,有卡就是任性。其中,α,β,γ是使用网格搜索出来的常量,表明如何调整网络的深度、宽度和分辨率;Φ是用户自定义的相关系数,用来控制模型的扩增。
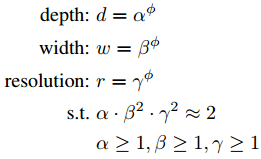
EfficientNet有8个系列,分别从b0-b7,,其中b0是baseline,b1-b7都是在b0基础上对深度、宽度和分辨率进行调整。从官方源码上,可以得到以下参数。其中,参数分别是宽度的相关系数,深度的相关系数,输入图片的分辨率和dropout的比例。这些参数如何得到的呢,就是通过刚刚介绍的AutoML进行搜索出来的。

所以,接下来介绍一下EfficientNet-b0的结构。EfficientNet-b0的结构与mobilenet v2很类似,使用了的Inverted Residuals和Linear Bottlenecks,并结合了SE模块。这么说,和mobilenet v3又很类似。如下图所示,左图是MobileNet V2的网络图,右图是EfficientNet-b0的网络图。可以很明显看出来,两者还是十分相像的,最大的区别是在通道数上进行改变。

综上所述,谷歌提出扩大模型来提高准确率的方法,即动态调整网络的宽度、深度和分辨率。确实在保证运算速度的前提下,能将模型的准确率提高很多。最后也确实感觉到,AutoML的强大,有卡真好。